RAG LLM API 연동과 고급 기법 - Citation, GraphRAG, Agentic RAG [RAG 7]

RAG 1편부터 6편까지 검색 파이프라인을 인덱싱, 벡터 DB, 검색 정확도, 보안, 지연/평가 순으로 살펴봤습니다. 이번 글에서는 검색된 청크를 LLM에 넘겨 답을 만드는 generation 단계와, 이 단계에서 출처(citation)를 어떻게 보장하는지를 다룹니다. 이어서 표준 vector RAG를 넘어서는 고급 기법인 GraphRAG와 Agentic RAG를 정리하고, 사내 정책 문서 RAG 관점에서 어떤 이점과 한계가 있는지 정직하게 짚어봅니다. 마지막 편인 만큼 시리즈를 관통한 원칙도 함께 정리합니다.
- Generation 단계는 검색된 문맥을 답변 근거로 제한하고, 사용자가 검증할 수 있는 citation을 반환해야 합니다. citation은 근거 위치를 가리키지만 답변 해석의 정확성을 보장하지는 않습니다.
- Claude Citations는 제공 문서의 유효 포인터와 직접 추출한
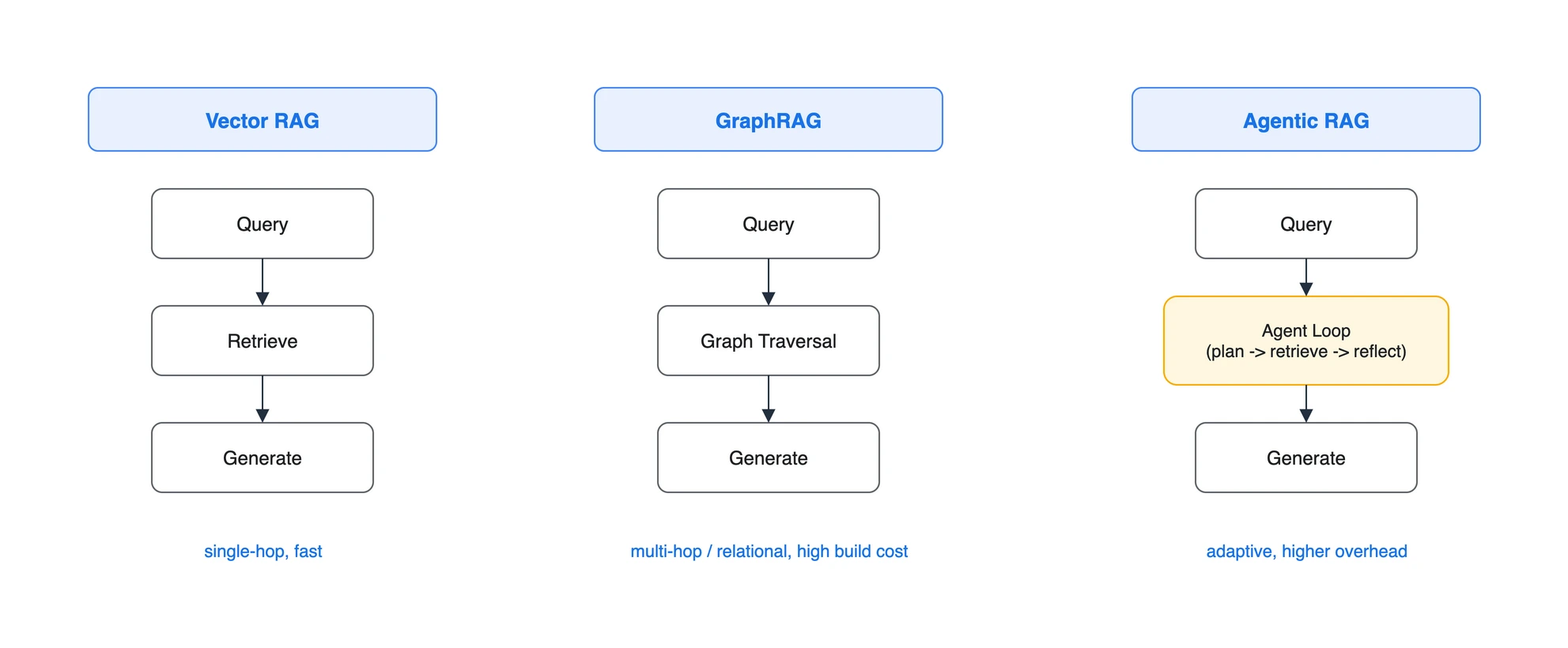
cited_text를 반환합니다. 현재 문서 기준으로 structured outputs와 동시에 사용할 수 없으므로 응답 계약을 먼저 선택해야 합니다.- GraphRAG는 텍스트에서 그래프와 community summary를 만들며, 전체 코퍼스의 주제나 연결 관계를 묻는 질의에 맞습니다. 모든 질의의 대체재가 아닙니다.
- Agentic RAG는 필요할 때 검색하고 생성 결과를 점검하는 제어 흐름입니다. 추가 호출과 상태 관리가 생기므로 어려운 질의에만 라우팅할지 평가로 결정합니다.
1. Generation 단계와 컨텍스트 주입
검색이 끝나면 상위 청크들을 질의와 함께 프롬프트에 넣어 LLM에게 답을 생성하게 합니다. 이 단계의 핵심은 두 가지입니다.
- Grounding: 모델이 자기 사전 지식이 아니라 제공된 문서에 근거해 답하도록 유도합니다. 프롬프트에 “제공된 문서에 없는 내용은 답하지 말고 모른다고 하라” 같은 제약을 명시합니다.
- Citation: 답의 각 주장에 출처를 함께 반환하게 구성합니다. 정책 문서 RAG에서는 “어느 규정 몇 조에 근거했는가”를 제시하는 것이 신뢰의 전제입니다. 출처 없이 그럴듯한 답만 나오면, 사용자는 그 답을 검증할 수 없습니다.
문제는 프롬프트로 “출처를 붙여라”라고 지시해도, 모델이 출처 자체를 그럴듯하게 지어낼(hallucinate) 수 있다는 점입니다. 제공하지 않은 조항 번호를 만들어내거나, 실제와 다른 문장을 인용문으로 제시하는 경우입니다. 이를 API 차원에서 방지하는 기능이 citation 지원입니다.
2. Claude Citations API
Anthropic의 Claude API는 citation을 서버 측에서 처리하는 기능을 제공합니다. document content block에 citations.enabled=true를 설정하면, API가 응답을 여러 text block으로 나누고 인용된 block에는 citations 배열을 붙여 반환합니다. 각 citation은 cited_text(실제 인용된 원문), document_index, document_title, 그리고 위치 정보(plain text는 char_location의 start_char_index/end_char_index, PDF는 page_location)를 담습니다.
여기서 중요한 보장은, cited_text가 모델이 새로 만든 인용문이 아니라 제공 문서에서 직접 추출된 값이라는 점입니다. 반환된 citation은 제공 문서 내 유효한 포인터를 가지므로, 존재하지 않는 문장을 인용한 것처럼 표시하는 문제를 줄입니다. RAG처럼 출처 검증이 중요한 시스템에서 유용하지만, 문서 선택과 모델의 해석이 옳다는 보장은 아닙니다.
RAG 청크를 citation과 함께 넘기는 방식은 목적에 따라 다릅니다.
| 넣는 방식 | 동작 |
|---|---|
| plain-text document block | 문장 단위 인용을 원할 때 각 청크를 넣음 |
| custom content document block | chunking을 억제하고 원하는 단위로 인용 |
| search_result content block | source/title 필수, 아래 두 위치로 전달 |
전용 search_result content block은 source와 title이 필요합니다. 동적으로 검색한 결과는 tool result에, 미리 확보한 결과는 user message의 top level에 넣는 방식으로 사용할 수 있습니다. API 필드와 제약은 변경될 수 있으므로 구현 전 현재 provider 문서를 확인합니다.
Citation이 보장하는 것은 인용 포인터와 텍스트의 진위(anti-fabrication)이지, 모델이 그 인용을 올바르게 해석했는지가 아닙니다. 즉 “이 문장은 실제로 문서에 있다”는 보장이지 “이 문장이 질문에 대한 올바른 근거다”라는 보장은 아닙니다.
3. 중요 제약: Citation과 structured output의 비호환
정책 RAG를 설계할 때 반드시 알아야 할 제약이 있습니다. Citations는 structured output과 동시에 사용할 수 없습니다. citation을 켠 채로 출력 포맷(structured output, output_config.format)을 지정하면 API가 400 error를 반환합니다.
이유는 두 기능의 출력 구조가 충돌하기 때문입니다. citation은 citation block을 text와 interleave(교차 배치)해야 하는데, structured output이 요구하는 strict JSON schema는 이런 교차 구조를 허용하지 않습니다. 하나의 응답에서 “인용이 붙은 자유 텍스트”와 “고정 스키마 JSON”을 동시에 만들 수 없다는 의미입니다.
정책 문서 RAG에서 흔히 원하는 두 요구, 즉 “출처 인용을 강제하고 싶다”와 “답을 구조화된 JSON으로 받고 싶다”가 정면으로 부딪힙니다. 실무에서는 다음 중 하나를 택해야 합니다.
- 둘 중 하나를 포기한다(citation을 취하고 자유 텍스트를 받거나, 구조화 출력을 취하고 citation을 포기).
- 호출을 분리한다. 예를 들어 1차 호출로 citation이 붙은 답을 받고, 2차 호출로 그 답을 구조화된 JSON으로 정리합니다.
참고로 OpenAI 등 다른 LLM API도 컨텍스트 주입과 프롬프트 구성에 대한 가이드를 제공하므로, 사용하는 provider의 공식 문서에서 grounding/citation 관련 기능을 확인하는 것이 좋습니다.
4. 고급 기법 - GraphRAG
표준 RAG는 청크를 벡터로 색인하고 유사도로 검색합니다. GraphRAG는 다른 접근입니다. 문서에서 엔티티와 관계를 추출해 knowledge graph를 만들고, 검색 시 그래프를 순회(traverse)해 관련 정보를 모읍니다.
Microsoft GraphRAG는 텍스트에서 엔터티, 관계, 핵심 claim을 추출하고, 그래프 community를 계층화해 summary를 만듭니다. Global Search는 코퍼스 전체의 주제나 요약형 질문에, Local Search는 특정 엔터티와 이웃 관계를 묻는 질문에 쓰도록 설계되었습니다. “여러 정책이 어떤 관계로 연결되는가” 또는 “코퍼스 전체의 공통 주제는 무엇인가”처럼 관계와 전체 맥락이 필요한 질의에 후보가 될 수 있습니다.
다만 이 방식은 색인 시점의 LLM 호출, 그래프 생성, summary 생성과 갱신 비용을 요구합니다. Microsoft의 원 논문도 약 100만 토큰 규모의 데이터셋에서 global sensemaking 질의에 대한 결과를 보고한 것이지, 모든 single-hop lookup에서 vector RAG보다 낫다고 주장하지는 않습니다. 단일 조항 찾기에는 기본 top-k vector search가 더 단순한 선택일 수 있습니다.
따라서 전면 교체보다 질의 라우팅을 검증하는 편이 실용적입니다. 기준 vector RAG와 GraphRAG를 같은 문서와 정답 셋에서 비교하고, global 또는 관계 질의에서만 충분한 이득이 확인되면 그 경로로 보냅니다. 정책 문서의 상충 해석처럼 고위험 질문은 그래프 결과도 원문 citation으로 다시 검증해야 합니다.
5. 고급 기법 - Agentic RAG
Agentic RAG는 고정된 한 번의 검색 대신, 제어 로직이 검색 필요 여부와 다음 행동을 선택하는 패턴입니다. Self-RAG는 필요한 경우 passage를 검색하고, 검색된 passage와 생성 결과를 reflection token으로 점검하는 구체적 예입니다. 모든 Agentic RAG가 planning, multi-agent 협업, 도구 사용을 포함하는 것은 아니므로 이를 하나의 고정 아키텍처로 이해하면 안 됩니다.
이 접근은 한 번의 검색으로 근거가 충분하지 않은 질문에서 추가 검색이나 검증을 시도할 수 있습니다. 반대로 추가 retrieval, 평가, 생성 단계는 요청당 호출 수와 상태 관리 복잡도를 늘립니다. 품질 이득과 지연 비용은 모델, 도구, 종료 조건에 따라 달라지므로 일반적인 개선률로 판단하지 않습니다.
저지연 정책 문서 RAG에서는 모든 질의에 agent loop를 붙이지 않습니다. 기본 retrieval로 충분한 질의와 다문서 추론 또는 근거 부족 질의를 구분하고, 각 경로의 정확도, citation 완결성, tail 지연, 비용을 평가한 뒤 제한적으로 라우팅합니다.
6. 한계와 미해결 영역
GraphRAG와 Agentic RAG는 연구가 활발한 영역이지만, 사내 정책 문서 RAG의 구체적 요구사항과 어떻게 맞물리는지는 아직 근거가 충분하지 않은 부분이 있습니다.
- 보안/감사와의 정합성: 5편에서 다룬 multi-tenancy 격리, 감사 로깅 요구사항과 GraphRAG/Agentic RAG가 어떻게 호환되는지는 도메인 직접 근거가 부족합니다. 그래프 순회나 agent의 동적 검색이 접근제어 경계를 넘지 않도록 하는 설계는 추가 검증이 필요합니다.
- 실효 이득의 불확실성: 정책 문서의 상충 해석에서 GraphRAG가 실제로 얼마나 이득을 주는지, agentic 접근이 비용 대비 답 품질을 얼마나 개선하는지는 자체 코퍼스로 측정하기 전에는 단정하기 어렵습니다.
결론은 명확합니다. 이 기법들의 도입은 유행이 아니라 비용/지연 대비 이득을 측정한 뒤 결정해야 합니다. 표준 vector RAG로 목표 정확도가 나온다면, 복잡도를 더할 이유가 없습니다.
7. 시리즈 마무리
1편부터 7편까지 관통한 원칙을 정리합니다.
- 세 축의 균형: RAG는 정확도(검색 품질), 지연, 보안을 동시에 만족시켜야 합니다. 하나를 위해 다른 하나를 무너뜨리지 않도록 균형을 잡는 것이 설계의 핵심입니다.
- 자기 데이터로 측정: 청크 크기, 임베딩, 인덱스 파라미터, top-k, 고급 기법 도입까지 보편 최적값은 없습니다. 자사 코퍼스와 질의로 측정하고 개선하는 루프가 벤치마크 수치보다 우선합니다.
- 보안은 1급 제약: 사내 정책 문서 RAG는 편의 기능이 아니라 보안을 1급 제약으로 놓고 설계해야 합니다. 접근제어, PII 처리, prompt injection 방어, citation을 통한 검증 가능성을 처음부터 파이프라인에 넣습니다.
RAG는 “검색이 틀리면 생성도 틀린다”는 구조 위에서, 검색 품질을 끌어올리고 그 결과를 안전하고 검증 가능하게 사용자에게 전달하는 일련의 엔지니어링입니다. 이 시리즈가 그 전체 그림을 잡는 데 도움이 되었기를 바랍니다.
8. 시리즈 맵
- (1) RAG 개념과 파이프라인 Overview
- (2) 청킹/임베딩과 Contextual Retrieval
- (3) 벡터 DB와 인덱스
- (4) 검색 정확도: Hybrid Search + Reranking
- (5) 보안과 접근제어(DevSecOps)
- (6) 지연 최적화와 평가
- (7) LLM API 연동과 고급 (현재 글)
9. Reference
- Anthropic Docs - Citations
- Anthropic Docs - Search results
- Microsoft Research - From Local to Global: A Graph RAG Approach to Query-Focused Summarization
- Microsoft GraphRAG Docs - Welcome
- Asai et al. - Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi