RAG 개념과 파이프라인 Overview - LLM의 한계와 검색 증강 파이프라인 [RAG 1]

사내 정책 문서를 찾는 상황을 떠올려 봅니다. “출장 규정에서 숙박비 한도가 얼마였지”, “보안 정책상 외부 저장소 사용이 허용되는가” 같은 질문의 답은 대부분 어딘가의 문서에 이미 존재합니다. 하지만 문서는 PDF, Confluence 위키, 사내 위키 등 여러 곳에 흩어져 있고, 일반 LLM에게 물으면 그 문서를 보지 못한 채 그럴듯하지만 틀린 답을 낼 수 있습니다. 이 문제를 푸는 대표적인 방법이 RAG(Retrieval-Augmented Generation, 검색 증강 생성)입니다. 이번 글에서는 RAG가 왜 필요한지, 전체 파이프라인이 어떻게 구성되는지, 그리고 실무에서 RAG를 만들 때 관통하는 세 가지 설계 목표인 정확도, 지연, 보안을 살펴봅니다.
TL;DR
- RAG는 모델의 파라미터에만 의존하지 않고, 질문과 관련된 외부 문서를 검색해 생성 모델에 제공하는 방식입니다.
- 인덱스 갱신이 완료되면 재학습 없이 변경된 문서를 검색 대상에 반영할 수 있지만, 검색과 인용이 답변의 사실성을 보장하지는 않습니다.
- 파이프라인은 오프라인 인덱싱과 온라인 질의로 나뉘며, 실무 품질은 검색 및 근거 충실도, 지연, 권한과 데이터 보호를 함께 평가해야 합니다.
1. LLM만으로는 왜 부족한가
RAG를 이해하려면 먼저 LLM 단독 사용의 한계를 짚어야 합니다. LLM은 방대한 텍스트로 사전 학습된 모델이라 일반 지식과 언어 능력은 뛰어나지만, 사내 정책 문서 검색이라는 목적에서는 세 가지 구조적 한계가 있습니다.
1.1. Knowledge Cutoff (학습 시점의 한계)
모델은 특정 시점까지의 데이터로 학습됩니다. 그 이후에 개정된 정책이나, 애초에 학습 데이터에 포함되지 않은 조직 내부 문서는 모델의 파라미터만으로 확인할 수 없습니다. 즉 “우리 회사의 최신 출장 규정”은 검색이나 별도 제공 없이는 검증할 근거가 없습니다.
1.2. Hallucination (환각)
더 큰 문제는, 모델이 모른다고 대답하는 대신 그럴듯한 문장을 지어낸다는 점입니다. 정책 문서 검색처럼 정확성이 중요한 맥락에서 hallucination은 치명적입니다. 존재하지 않는 조항을 실제 규정인 것처럼 제시하면, 사용자는 잘못된 정보를 신뢰하게 됩니다.
1.3. 근거(출처)의 부재
LLM이 답을 생성해도 “그 답이 어느 문서 몇 페이지에 근거하는가”를 제시하지 못하면, 사용자는 답을 검증할 수 없습니다. 정책/규정 도메인에서는 답 자체보다 출처를 함께 제시하는 것(grounding)이 신뢰의 전제가 됩니다.
2. RAG의 기본 아이디어
RAG는 이 한계에 대응하기 위해 모델을 다시 학습시키는 대신, 질문 시점에 외부 지식을 가져옵니다. 원 논문은 이를 모델 파라미터에 담긴 지식과 별도로 조회하는 비파라미터 메모리의 결합으로 설명합니다. 실무 구현의 핵심은 단순합니다. 질문이 들어오면 관련 문서를 먼저 검색하고, 검색된 문서를 질문과 함께 프롬프트에 넣어 LLM이 그 문서에 근거해 답을 생성하도록 하는 것입니다.
비유하자면, 닫힌 책 시험(closed-book)을 보던 모델에게 열린 책 시험(open-book)을 보게 하는 것과 같습니다. 모델은 모든 것을 외우고 있을 필요 없이, 필요한 순간에 관련 페이지를 펼쳐 보고 답하면 됩니다. 이 구조 덕분에 RAG는 다음을 얻습니다.
- 최신성: 수집과 인덱스 갱신이 끝나면 재학습 없이 변경 문서를 검색 대상에 반영할 수 있습니다.
- 검증 가능성: 검색된 청크의 문서 ID, 섹션, 버전을 보존하면 답변에 근거를 연결할 수 있습니다.
- 통제 가능성: 모델이 제공된 문서 범위 안에서 답하고, 근거가 없으면 모른다고 답하도록 지시할 수 있습니다. 다만 이 지시만으로 환각이나 잘못된 인용이 사라지지는 않으므로 평가와 검증이 필요합니다.
2.1. RAG vs Fine-tuning
지식을 주입하는 다른 방법으로 fine-tuning이 있습니다. 둘은 경쟁 관계라기보다 목적이 다릅니다.
| 구분 | RAG | Fine-tuning |
|---|---|---|
| 주입 대상 | 지식(사실, 문서 내용) | 행동/형식/톤, 도메인 표현 |
| 최신화 | 인덱스 갱신 완료 후 반영 | 일반적으로 재학습 필요 |
| 출처 제시 | 가능(검색 문서가 근거) | 어려움(파라미터에 녹아듦) |
| 접근제어 | 검색 단계에서 문서별 권한 필터 가능 | 모델에 학습되면 분리/회수 어려움 |
| 초기 비용 | 상대적으로 낮음 | 상대적으로 높음 |
사내 정책 문서처럼 자주 바뀌고, 출처가 중요하며, 문서별 접근 권한이 다른 데이터는 RAG가 자연스러운 선택입니다. 실무에서는 도메인 표현 학습(fine-tuning)과 지식 주입(RAG)을 함께 쓰기도 합니다.
3. RAG 파이프라인 전체 흐름
RAG는 크게 두 단계로 나뉩니다. 하나는 미리 문서를 검색 가능한 형태로 준비하는 오프라인 인덱싱, 다른 하나는 사용자 질문에 답하는 온라인 질의입니다. 인덱싱의 품질이 이후 검색 후보의 품질을 결정하므로, 먼저 문서와 권한 메타데이터를 신뢰할 수 있는 단위로 준비해야 합니다. 두 단계는 벡터 저장소를 공유하며, 인덱싱이 벡터와 메타데이터를 기록하고 질의가 이를 검색합니다.
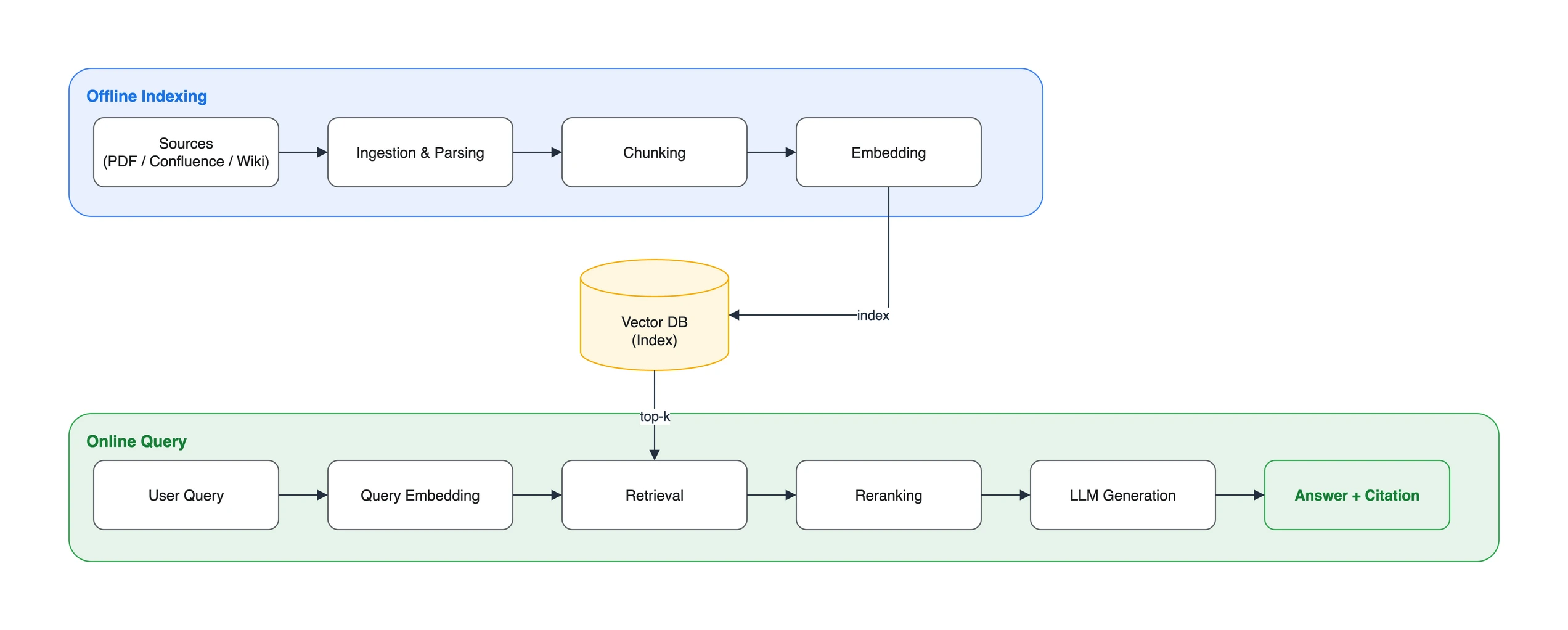
3.1. 오프라인 인덱싱 (ingestion -> chunking -> embedding -> indexing)
문서를 검색 가능한 벡터로 변환해 저장소에 넣는 준비 과정입니다. 사용자 질문과 무관하게 미리 수행합니다.
- Ingestion(수집/파싱): PDF, Confluence, 위키 등 다양한 소스에서 원문 텍스트를 추출합니다. 포맷마다 파싱 난이도가 다르며(표/레이아웃이 많은 PDF는 특히 까다롭습니다), 이 단계에서 문서별 메타데이터(부서, 접근 권한, 개정일 등)도 함께 수집합니다.
- Chunking(분할): 문서를 검색 단위인 청크(chunk)로 쪼갭니다. 너무 크면 관련 없는 내용이 섞여 검색 정확도가 떨어지고, 너무 작으면 문맥이 끊깁니다. 청크 크기와 전략은 검색 품질을 좌우하는 핵심 변수입니다(2편에서 상세히 다룹니다).
- Embedding(임베딩): 각 청크를 고정 차원의 수치 벡터로 변환합니다. 같은 모델로 벡터화한 질문과 청크의 거리를 비교해, 단어가 정확히 같지 않아도 의미가 가까운 후보를 찾는 검색을 수행합니다.
- Indexing(색인): 임베딩 벡터를 벡터 데이터베이스에 저장하고, 빠른 유사도 검색을 위한 인덱스(HNSW/IVF 등)를 구성합니다(3편에서 다룹니다).
3.2. 온라인 질의 (retrieval -> reranking -> generation)
사용자 질문이 들어온 시점에 실시간으로 동작하는 과정입니다.
- Retrieval(검색): 질문도 같은 임베딩 모델로 벡터화한 뒤, 벡터 DB에서 가까운 청크 상위 K개를 가져옵니다. BM25는 정확한 단어와 구문을 찾는 키워드 순위화 함수이며, 이를 벡터 검색과 결합한 hybrid search는 서로 다른 실패 모드를 보완합니다(4편).
- Reranking(재순위화): 1차 후보를 질문과 함께 더 정밀한 모델에 넣어 다시 정렬합니다. 관련 청크를 상위로 올릴 수 있지만, 후보 수와 모델에 따라 지연과 비용이 추가됩니다(4편).
- Generation(생성): 최종 선별된 청크를 질문과 함께 프롬프트에 넣어 LLM이 답을 생성합니다. 답변의 각 주장과 인용이 실제 청크를 가리키는지 후처리 또는 평가로 확인해야 합니다(7편).
3.3. 두 단계를 한눈에
| 단계 | 시점 | 하는 일 | 주로 결정하는 것 |
|---|---|---|---|
| Ingestion | 오프라인 | 소스에서 텍스트/메타데이터 추출 | 파싱 품질 |
| Chunking | 오프라인 | 검색 단위로 분할 | 검색 정확도의 토대 |
| Embedding | 오프라인 | 청크를 의미 벡터로 변환 | 의미 검색 성능 |
| Indexing | 오프라인 | 벡터 DB 저장 + 인덱스 구성 | 검색 속도/확장성 |
| Retrieval | 온라인 | 질문과 가까운 청크 K개 검색 | 재현율(recall) |
| Reranking | 온라인 | 후보를 정밀 재정렬 | 정밀도(precision) |
| Generation | 온라인 | 문서 근거로 답 생성 + 출처 | 답변 품질/신뢰 |
4. 사내 정책 문서라는 관통 예시
이 시리즈는 “사내 정책 문서 검색”을 관통 예시로 삼습니다. 이 도메인이 RAG의 여러 이슈를 한꺼번에 드러내기 때문입니다.
- 혼합 소스: 정책은 PDF 사규, Confluence 페이지, 위키 등 서로 다른 포맷으로 존재합니다. ingestion/chunking 전략이 포맷마다 달라집니다.
- 정확성이 중요: 규정을 잘못 답하면 실무 판단이 어긋납니다. 환각 억제와 출처 제시가 필수입니다.
- 접근 권한 분리: 인사/보안/재무 정책은 열람 권한이 다릅니다. “누가 어떤 문서를 검색할 수 있는가”가 처음부터 설계에 들어와야 합니다.
- 응답 속도: 사내 도구로 쓰이려면 질문에 빠르게 답해야 합니다. 지연이 크면 아무도 쓰지 않습니다.
이처럼 정확도, 지연, 보안이 동시에 요구되는 점이 이 시리즈가 잡는 세 가지 설계 목표로 이어집니다.
5. RAG의 세 가지 설계 목표
실무 RAG는 하나의 지표만 좋아서는 쓸 수 없습니다. 서로 당기는 세 축을 균형 있게 맞추는 일입니다.
5.1. 정확도 (Accuracy / Faithfulness)
“검색이 관련 문서를 잘 찾았는가”와 “생성된 답이 그 문서에 충실한가(faithfulness)”의 두 층으로 나뉩니다. 검색이 틀리면 근거 기반 답변의 출발점이 무너지고, 검색이 맞아도 모델이 문서를 벗어나 지어내면 신뢰할 수 없습니다. 그래서 청킹, hybrid search, reranking으로 검색 품질을 올리고, 답변과 제공 문맥의 충실도를 별도 평가해 회귀를 막습니다(6편).
5.2. 지연 (Latency)
RAG는 검색과 생성을 매 질문마다 수행하므로 단계마다 지연이 쌓입니다. 벡터 검색, reranking, LLM 생성이 각각 시간을 먹고, 특히 reranking처럼 정확도를 올리는 단계는 지연을 늘립니다. 캐싱, 인덱스 튜닝, top-k 조정으로 지연을 줄이되 정확도를 얼마나 희생하는지 함께 봐야 합니다(6편).
5.3. 보안 / 접근제어 (DevSecOps)
사내 문서 RAG에서 보안은 부가 기능이 아니라 1급 설계 제약입니다. 문서별 권한에 따라 검색 결과를 필터링하고(RBAC/metadata filtering), 민감정보(PII)를 인덱싱 전에 처리하며, 검색된 문서가 프롬프트로 들어오는 특성상 prompt injection과 데이터 유출(exfiltration)을 방어해야 합니다. 이 시리즈가 일반적인 RAG 튜토리얼과 다른 지점이며, 5편에서 비중 있게 다룹니다.
정확도를 위한 최적화가 보안과 충돌하기도 합니다. 예를 들어 지연을 줄이려는 캐시가 권한 기반 검색과 충돌해 다른 권한 사용자에게 결과가 새는 경우가 있습니다. 이런 교차 지점은 5편/6편에서 함께 다룹니다.
6. Naive RAG의 함정
큰 그림을 잡았으므로, 이제 이 두 단계에서 자주 생기는 실패를 구체적으로 볼 차례입니다. 가장 단순한 RAG는 문서를 자르고, 임베딩하고, top-k를 검색해 그대로 프롬프트에 넣습니다. 이 방식은 데모에는 충분할 수 있지만 실무에서는 금방 한계를 드러냅니다.
- 청킹 시 문맥 손실: 청크를 쪼개면 각 청크가 원문 어디에 속했는지 맥락이 사라져, 검색이 엉뚱한 청크를 가져옵니다. 이를 보완하는 기법이 Contextual Retrieval입니다(2편).
- 의미 검색만의 한계: 벡터 검색은 의미는 잘 잡지만 정확한 키워드(제품명, 조항 번호)에는 약합니다. 키워드 검색과 결합한 hybrid search가 필요합니다(4편).
- 순위의 부정확성: 1차 검색 상위 결과가 항상 가장 관련 있는 것은 아니라, reranking으로 재정렬이 필요합니다(4편).
- 보안 공백: 권한/PII/injection을 고려하지 않은 RAG는 사내에 그대로 올릴 수 없습니다(5편).
즉 “동작하는 RAG”에서 “정확하고, 빠르고, 안전한 RAG”로 가는 과정이 이 시리즈의 나머지 내용입니다.
7. 시리즈 맵
이 글은 RAG 시리즈의 첫 글입니다. 앞으로 다음 주제를 이어갈 예정입니다.
- (1) RAG 개념과 파이프라인 Overview - LLM 한계, 파이프라인 전체 흐름, 세 가지 설계 목표 (현재 글)
- (2) 청킹/임베딩과 Contextual Retrieval - 청킹 전략, 임베딩 모델 선택, 문맥 손실 보완, 메타데이터 설계
- (3) 벡터 DB와 인덱스 - HNSW/IVF 개념, pgvector vs Qdrant, 메타데이터 필터링
- (4) 검색 정확도 - Hybrid Search(BM25 + dense), RRF 융합, reranking
- (5) 보안과 접근제어(DevSecOps) - RBAC/metadata filtering, PII 처리, prompt injection, 캐시-권한 충돌
- (6) 지연 최적화와 평가 - 캐싱, 인덱스 튜닝, top-k, Ragas로 정확도 회귀 방지
- (7) LLM API 연동과 고급 - citation/grounding, GraphRAG/Agentic RAG
8. Reference
- arXiv - Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Anthropic Engineering - Introducing Contextual Retrieval
- AWS Docs - Protect sensitive data in RAG applications with Amazon Bedrock
- OWASP - LLM01:2025 Prompt Injection
- Ragas Docs - Available Metrics
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi