Amazon Athena & Glue Data Catalog 알아보기 - 서버리스 쿼리와 메타스토어

앞선 AWS 데이터 분석 스택 Overview에서 분석 스택의 큰 그림과, 쿼리 한 번이 엔진과 메타스토어, 저장소를 지나는 흐름을 살펴봤습니다. 이번 글에서는 그 중심에 있는 두 구성요소, Amazon Athena와 AWS Glue Data Catalog를 자세히 알아봅니다.
이 둘은 한 쌍으로 움직입니다. Athena는 SQL을 실행하는 엔진이고, Glue Data Catalog는 “그 SQL이 가리키는 테이블이 무엇이고 어디에 있는지”를 알려주는 메타스토어입니다. 둘의 역할 분리와 권한 모델까지 정리합니다.
TL;DR
- Amazon Athena는 Trino/Presto 기반의 서버리스 SQL 엔진으로, S3 데이터를 적재 없이 쿼리하고 스캔량 기준으로 과금합니다.
- Glue Data Catalog는 DB/테이블/컬럼/파티션 메타데이터의 중앙 메타스토어이며, Athena/Redshift/EMR이 같은 정의를 공유합니다.
- Athena의 “테이블”은 곧 Glue Catalog의 엔트리입니다. 데이터는 S3에, 정의는 Catalog에 있습니다.
- Glue 리소스 권한은 CATALOG > DATABASE > TABLE 계층이며, 한 리소스 접근에는 그 조상 전부에 대한 IAM 권한이 필요합니다.
1. Amazon Athena
1.1. 서버리스 SQL 엔진
Amazon Athena는 S3에 있는 데이터를 표준 SQL로 분석하는 서버리스 쿼리 서비스입니다. 엔진은 분산 SQL 엔진인 Trino/Presto 계보를 따릅니다. 클러스터를 띄우거나 관리할 필요가 없으며, 쿼리를 실행한 만큼(스캔한 데이터량 기준)만 비용을 냅니다.
서버리스라는 점은 두 가지를 뜻합니다. 첫째, 인프라를 직접 운영하지 않습니다(AWS가 관리합니다). 둘째, 사용하지 않을 때 드는 고정비가 없습니다. 그래서 “가끔, 빠르게” S3 데이터를 들여다보는 ad-hoc 분석에 잘 맞습니다.
1.2. 쿼리 실행 흐름
Athena는 비동기로 동작합니다. 쿼리를 제출하면 즉시 결과가 오는 것이 아니라, “시작 -> 완료 폴링 -> 결과 조회” 순서를 거칩니다. 쿼리 한 번이 지나는 길을 그림으로 보면 다음과 같습니다.
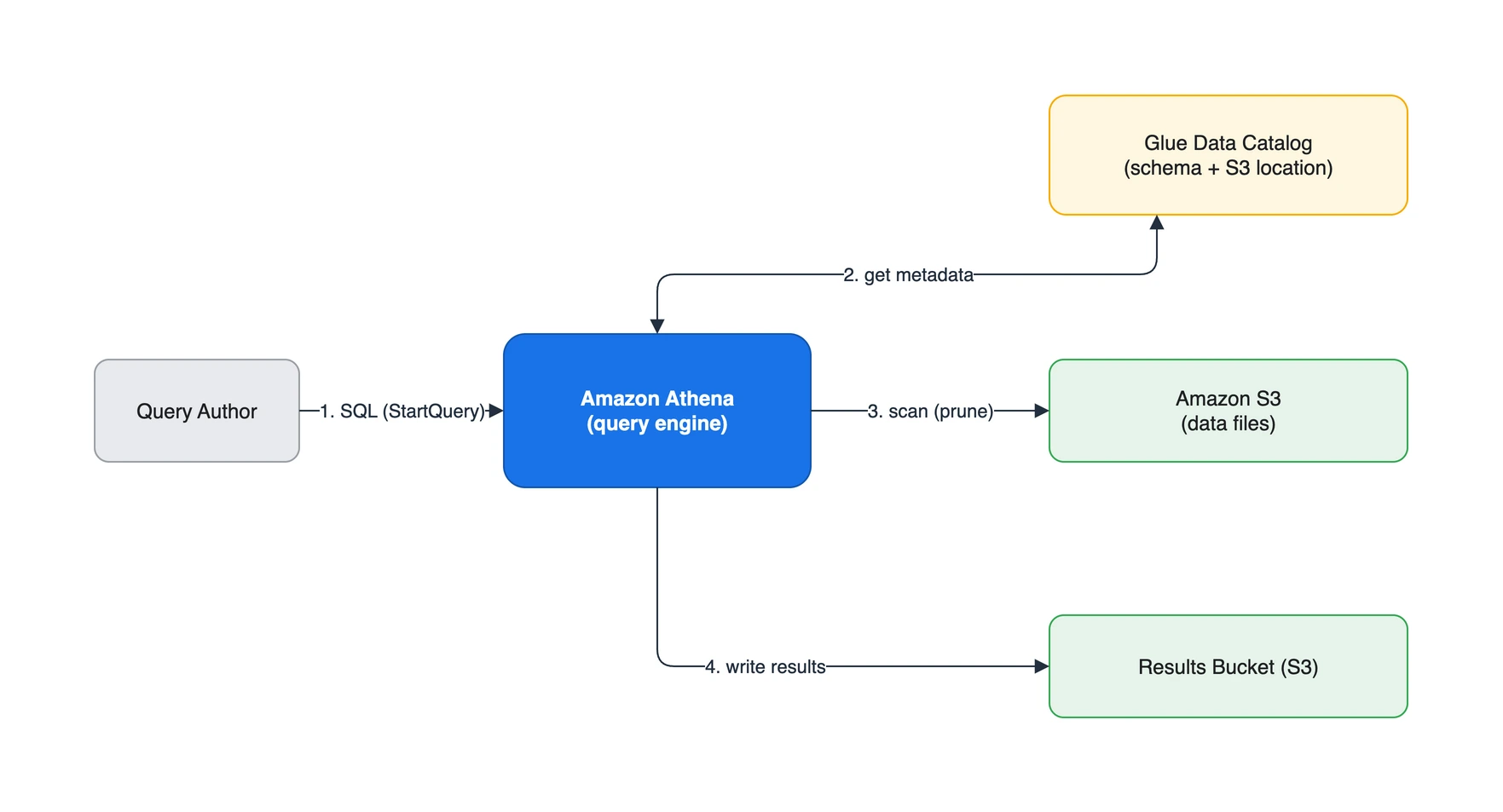
- SQL 제출: 클라이언트가
StartQueryExecution으로 쿼리를 던집니다. 이때 실행할 workgroup이 정해집니다. - 메타데이터 조회: Athena가 대상 테이블의 스키마와 S3 위치, 파티션 정보를 Glue Data Catalog에서 받아옵니다.
- 데이터 스캔: Catalog가 알려준 S3 위치의 데이터를 스캔합니다. 파티션 필터가 있으면 해당 파티션만 읽습니다(partition pruning).
- 결과 기록: 결과는 결과 버킷(S3)에 기록되고 클라이언트로 반환됩니다.
코드로 보면 StartQueryExecution으로 쿼리 ID를 받고, GetQueryExecution으로 상태를 폴링한 뒤, 성공하면 GetQueryResults로 결과를 가져오는 형태입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import boto3, time
athena = boto3.client("athena", region_name="ap-northeast-2")
def run_query(sql, workgroup="primary"):
# 전제: workgroup에 결과 위치를 enforce로 고정해 두었다고 가정한다.
# 그렇지 않으면 QueryExecutionContext(Database/Catalog)와
# ResultConfiguration(OutputLocation)을 명시해야 한다. 예:
# athena.start_query_execution(
# QueryString=sql, WorkGroup=workgroup,
# QueryExecutionContext={"Database": "sales_db"},
# ResultConfiguration={"OutputLocation": "s3://.../results/"},
# )
qid = athena.start_query_execution(
QueryString=sql, WorkGroup=workgroup,
)["QueryExecutionId"]
while True:
state = athena.get_query_execution(
QueryExecutionId=qid
)["QueryExecution"]["Status"]["State"]
if state in ("SUCCEEDED", "FAILED", "CANCELLED"):
break
time.sleep(2)
if state != "SUCCEEDED":
raise Exception(f"Athena {state}")
return athena.get_query_results(QueryExecutionId=qid)
1.3. workgroup - 실행 단위의 경계
workgroup은 쿼리 실행의 경계입니다. 결과 저장 위치, 데이터 스캔 한도, 암호화, CloudWatch 지표 같은 정책을 workgroup 단위로 강제할 수 있습니다. 팀이나 용도별로 workgroup을 나누면 비용 추적과 권한 통제가 쉬워집니다.
비용 통제는 두 종류로 나뉩니다. workgroup마다 per-query limit은 하나만, per-workgroup limit은 여러 개 둘 수 있습니다.
Athena allows you to set two types of cost controls: per-query limit and per-workgroup limit. For each workgroup, you can set only one per-query limit and multiple per-workgroup limits.
핵심은 두 한도의 동작이 다르다는 점입니다. per-query control limit은 쿼리 한 건이 스캔하는 데이터량의 상한이고, 이 한도를 넘기면 해당 쿼리는 자동으로 취소됩니다(CANCELLED). 반면 per-workgroup limit은 일정 기간 동안 workgroup 전체의 누적 스캔량에 대한 경보일 뿐이며, 한도를 넘겨도 쿼리가 자동 취소되지는 않습니다.
The per-query control limit specifies the total amount of data scanned per query. If any query that runs in the workgroup exceeds the limit, it is canceled. […] The default action is to cancel the query if it exceeds the limit. This setting cannot be changed.
per-query limit은 폭주 쿼리(파티션 필터 누락으로 풀스캔하는 경우 등)가 막대한 스캔 비용을 일으키기 전에 잘라내는 안전장치입니다. 1.2절의 폴링 루프에서 state가 CANCELLED로 끝나는 경우 중 상당수가 바로 이 한도 초과입니다. 한도값은 10 MB부터 7 EB까지 지정할 수 있습니다. 다만 per-query 한도로 취소된 쿼리도 그 시점까지 스캔한 양만큼은 과금되며, 부분 결과가 S3 결과 prefix에 남을 수 있다는 점은 주의해야 합니다.
결과 위치를 workgroup에
enforce로 고정해 두면, 클라이언트는WorkGroup이름만 지정하면 됩니다. 결과 객체에 대한 권한도 workgroup별 prefix로 좁힐 수 있습니다.
2. AWS Glue Data Catalog
2.1. 중앙 메타스토어
Athena가 데이터를 직접 들고 있지 않다는 점이 중요합니다. 데이터는 S3에, 그 데이터의 정의(스키마)는 Glue Data Catalog에 있습니다. 분석 스택에서 “테이블”이란 곧 Glue Data Catalog의 엔트리입니다. “이 S3 위치의 파일들은 이런 컬럼을 가진 테이블”이라는 정의가 Catalog에 등록되어 있고, Athena/Redshift Spectrum/EMR이 모두 같은 정의를 참조합니다.
그래서 한 곳(Catalog)에서 테이블을 정의하면 여러 엔진이 동일한 테이블을 봅니다. 메타데이터가 한 군데로 모이는 것이 Glue Data Catalog의 핵심 가치입니다.
2.2. 크롤러와 ETL
Glue는 메타스토어 외에 두 가지 일을 더 합니다.
- Crawler: S3 등 데이터 소스를 스캔해 스키마를 자동으로 추론하고 Catalog에 테이블을 등록/갱신합니다. 스키마를 수기로 정의하는 부담을 줄입니다.
- ETL Job: Spark 기반으로 데이터를 변환/이동합니다.
분석 스택의 맥락에서는 Glue를 주로 메타스토어 + 크롤러로 사용합니다. ETL은 별도 파이프라인 주제이므로 이 시리즈에서는 깊이 다루지 않습니다.
2.3. 파티션 - 스캔량을 줄이는 핵심
큰 테이블은 보통 날짜 같은 키로 파티션됩니다. 파티션이 있으면 WHERE dt = '2026-03-31' 같은 필터로 해당 파티션만 스캔합니다. Athena는 스캔량 기준 과금이므로, 파티션 필터가 곧 비용 절감입니다.
파티션을 Catalog에 인식시키는 방법은 여러 가지입니다. MSCK REPAIR TABLE로 일괄 로드할 수도 있지만, 파티션이 많아지면 느려집니다. 운영에서는 partition projection(파티션을 패턴으로 계산해 메타데이터 등록 없이 인식)이나 Glue Crawler를 더 많이 씁니다.
partition projection은 파티션 메타데이터를 Catalog에 일일이 등록하지 않고, 테이블 속성에 정의한 규칙으로 파티션 값을 계산합니다. 파티션이 수천 개 이상으로 늘어날 때 특히 유리합니다.
규칙은 테이블 속성(table properties)의 key-value로 정의합니다. 컬럼마다 projection.<columnName>.type을 지정하고(지원 타입은 enum, integer, date, injected), 타입에 따라 projection.<columnName>.range(integer/date의 범위), projection.<columnName>.format(date의 포맷), projection.<columnName>.values(enum의 값 목록) 같은 보조 속성을 더합니다. 마지막에 projection.enabled를 true로 설정하면 활성화됩니다. 예를 들어 dt가 yyyy-MM-dd 형식의 날짜 파티션이라면 다음과 같이 정의합니다.
1
2
3
4
'projection.enabled' = 'true'
'projection.dt.type' = 'date'
'projection.dt.range' = '2020-01-01,NOW'
'projection.dt.format' = 'yyyy-MM-dd'
S3 경로가 .../column=value/... 패턴을 따르지 않는다면 storage.location.template로 경로 템플릿을 직접 지정할 수 있으며, 이때 템플릿에는 파티션 컬럼마다 placeholder가 반드시 하나씩 있어야 하고 경로는 forward slash로 끝나야 합니다.
if you use a custom template, the template must contain a placeholder for each partition column. Templated locations must end with a forward slash so that the partitioned data files live in a “folder” per partition.
한 가지 함정은 projection을 켜면 Catalog에 등록된 기존 파티션 메타데이터를 Athena가 무시한다는 점입니다.
Enabling partition projection on a table causes Athena to ignore any partition metadata registered to the table in the AWS Glue Data Catalog or Hive metastore.
즉 MSCK REPAIR TABLE이나 Crawler로 등록한 파티션과 projection을 섞어 쓸 수 없으며, projection 규칙이 곧 단일 진실 공급원이 됩니다.
3. 권한 - Glue 리소스의 fine-grained IAM
Athena 쿼리의 실질적인 접근 통제는 API가 아니라 Glue(메타데이터)와 S3(실데이터) 에서 일어납니다. 여기서는 Glue 쪽 IAM을 봅니다. (S3 Tables/Lake Formation이 얽히는 경우는 이후 글에서 다룹니다.)
3.1. CATALOG > DATABASE > TABLE 계층
Glue Data Catalog의 리소스는 계층 구조입니다.
1
2
3
CATALOG
└─ DATABASE
└─ TABLE / FUNCTION
ARN으로 표현하면 다음과 같습니다.
1
2
3
arn:aws:glue:<region>:<account-id>:catalog
arn:aws:glue:<region>:<account-id>:database/<db>
arn:aws:glue:<region>:<account-id>:table/<db>/<table>
3.2. 조상 권한이 모두 필요하다
핵심 규칙은 delete가 아닌 모든 Athena 동작은 대상 리소스와 그 조상 전부에 대한 IAM 권한을 요구한다는 점입니다. 예를 들어 한 테이블을 쿼리하려면 그 table, 소속 database, 계정 catalog에 대한 권한이 모두 있어야 합니다. AWS 문서는 이를 다음과 같이 명시합니다.
For any non-delete Athena action on a resource, such as
CREATE DATABASE,CREATE TABLE,SHOW DATABASE,SHOW TABLE, orALTER TABLE, you need permissions to call this action on the resource (table or database) and all ancestors of the resource in the Data Catalog.
파티션도 같은 원칙을 따릅니다. 파티션은 독립 리소스가 아니라 테이블에 종속되므로, 파티션 조회 권한은 catalog/database/table 세 층 모두에서 부여해야 합니다.
To run actions in AWS Glue on partitions, permissions for partition actions are required at the catalog, database, and table levels. Having access to partitions within a table is not sufficient. For example, to run
GetPartitionson tablemyTablein the databasemyDB, you must grantglue:GetPartitionspermissions on the catalog,myDBdatabase, andmyTableresources.
여기서 단수형 glue:GetPartition과 복수형 glue:GetPartitions는 서로 다른 action입니다. GetPartitions(복수)는 테이블의 파티션 목록을 한 번에 조회하는 호출로, Athena가 partition pruning 전에 사용합니다. GetPartition(단수)은 특정 파티션 하나를 조회하며, BatchCreatePartition/BatchGetPartition 같은 batch action도 대량 파티션을 다루는 작업(MSCK REPAIR TABLE 등)에서 필요합니다. SELECT 쿼리만 한다면 GetPartitions로 충분하지만, DDL이나 파티션 등록까지 다루면 단수형과 batch action을 함께 부여해야 누락 없이 동작합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase", "glue:GetDatabases",
"glue:GetTable", "glue:GetTables",
"glue:GetPartition", "glue:GetPartitions"
],
"Resource": [
"arn:aws:glue:ap-northeast-2:<account-id>:catalog",
"arn:aws:glue:ap-northeast-2:<account-id>:database/sales_db",
"arn:aws:glue:ap-northeast-2:<account-id>:table/sales_db/*"
]
}
catalog ARN을 빼고 database/table만 적으면 권한이 끊겨 조회가 실패합니다. 조상까지 모두 포함하는 것이 fine-grained 권한 설계의 기본입니다.
Athena의 워크그룹 권한(
athena:StartQueryExecution등)과 Glue 권한은 별개입니다. 워크그룹에서 쿼리를 시작할 수 있어도, Glue 권한이 없으면 메타데이터 단계에서 막힙니다.
4. 실습 - Athena와 Glue를 함께 다루기
전제: S3 버킷 s3://amzn-s3-demo-bucket/orders/ 아래에 날짜 파티션으로 주문 데이터가 쌓여 있다고 가정합니다.
4.1. 테이블 등록 (Glue Catalog)
Athena DDL로 테이블을 정의하면 Glue Data Catalog에 메타데이터가 등록됩니다. 데이터는 옮기지 않습니다.
1
2
3
4
5
6
7
8
CREATE EXTERNAL TABLE IF NOT EXISTS sales_db.orders (
order_id bigint,
buyer_id bigint,
amount double
)
PARTITIONED BY (dt string)
STORED AS PARQUET
LOCATION 's3://amzn-s3-demo-bucket/orders/';
4.2. 파티션 인식과 쿼리
파티션을 인식시킨 뒤(MSCK REPAIR TABLE 또는 partition projection), 파티션 필터를 걸어 쿼리합니다.
1
2
3
4
5
6
7
MSCK REPAIR TABLE sales_db.orders;
SELECT dt, count(*) AS cnt, sum(amount) AS revenue
FROM sales_db.orders
WHERE dt BETWEEN '2026-03-01' AND '2026-03-31' -- 파티션 필터로 스캔 범위 한정
GROUP BY dt
ORDER BY dt;
이 쿼리는 다음 순서로 동작합니다. Athena가 sales_db.orders의 스키마와 S3 위치를 Glue Catalog에서 받고(2단계), 3월 파티션만 S3에서 스캔하며(3단계), 결과를 반환합니다(4단계). 1편에서 본 흐름이 그대로 적용됩니다.
4.3. 권한이 끊기면
만약 glue:GetPartitions 권한이 없거나 catalog ARN이 빠져 있으면, 같은 쿼리가 메타데이터 단계에서 AccessDeniedException으로 실패합니다. 에러 메시지에 어떤 action이 어떤 리소스에서 거부됐는지 나오므로, 그 action/리소스를 IAM 정책에 추가하면 됩니다. 메시지는 대략 다음 형태입니다.
1
2
3
4
AccessDeniedException: User: arn:aws:sts::<account-id>:assumed-role/analyst/...
is not authorized to perform: glue:GetPartitions
on resource: arn:aws:glue:ap-northeast-2:<account-id>:table/sales_db/orders
because no identity-based policy allows the glue:GetPartitions action
진단의 핵심은 메시지의 perform:(거부된 action)과 on resource:(거부된 ARN)를 그대로 읽는 것입니다. 위 예시라면 glue:GetPartitions를 정책에 추가하되, 3.2절 원칙대로 table ARN만이 아니라 catalog와 database ARN까지 함께 넣어야 합니다. action 하나를 추가했는데도 다음 단계에서 또 다른 ARN으로 같은 에러가 반복된다면, 조상 ARN 중 하나가 여전히 빠져 있을 가능성이 높습니다.
5. 다음 편
이번 편에서는 일반적인 Glue 테이블(S3 + Glue Catalog)을 기준으로 Athena와 메타스토어, 권한을 정리했습니다. 다음 편에서는 한 단계 더 들어갑니다.
- Apache Iceberg 테이블 포맷 - S3 Tables가 전제하는 오픈 테이블 포맷의 구조(메타데이터 계층, ACID, 스키마/파티션 진화)를 먼저 정리합니다.
- S3 Tables & Catalog Federation - 관리형 Iceberg 레이크하우스가 등장하면, Glue Catalog 안에 federated 카탈로그(
s3tablescatalog)가 중첩되고 ARN이 깊어집니다. - AWS Lake Formation - 레이크하우스 데이터에는 IAM 위에 데이터 접근 권한 계층이 하나 더 얹힙니다.
일반 Glue 테이블과 레이크하우스 테이블의 권한 모델이 어떻게 달라지는지가 다음 두 편의 핵심입니다.
6. Reference
- Amazon Athena - What is Amazon Athena?
- Athena - Using the AWS Glue Data Catalog
- Athena - Fine-grained access to databases and tables in the Glue Data Catalog
- Athena - Partition projection
- AWS Glue - Data Catalog
- Athena - Workgroups
- Athena - Configure per-query and per-workgroup data usage controls
- Athena - Set up partition projection
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi