RAG 청킹과 임베딩, Contextual Retrieval - 검색 품질을 좌우하는 인덱싱 설계 [RAG 2]

RAG 1편에서 RAG 파이프라인의 큰 그림을 살펴봤습니다. 이제 오프라인 인덱싱이 온라인 답변에 어떤 영향을 주는지 보겠습니다. 이번 글에서는 문서를 어떻게 쪼개는지(chunking), 어떤 임베딩으로 벡터화하는지, 청킹에서 잃은 맥락을 어떻게 보강하는지(Contextual Retrieval)를 다룹니다. 검색 후보가 부실하면 근거 기반 답변도 부실해지므로, 인덱싱 설계는 검색 품질의 출발점입니다.
TL;DR
- 청크는 검색과 인용의 최소 단위다. 문서 구조와 실제 질문을 기준으로 경계를 정하고, 크기와 overlap은 평가로 조정한다.
- Contextual Retrieval은 원문 전체를 바탕으로 청크별 짧은 설명을 만들어 벡터와 BM25 색인 앞에 붙이는 전처리 기법이다.
- Anthropic의 공개 평가에서는 Contextual Embeddings와 Contextual BM25, reranking을 함께 썼을 때 top-20 검색 실패율이 줄었다. 이 결과는 해당 평가 구성의 관측값이므로 자체 코퍼스에서 재현 검증해야 한다.
- 출처, 섹션, 버전, 권한 메타데이터를 청크와 함께 보존해야 이후 필터링과 인용을 신뢰할 수 있다.
1. 왜 청킹이 검색 품질을 좌우하는가
임베딩 모델은 입력 텍스트를 고정 차원의 벡터로 바꿉니다. 청크는 이 변환과 검색, 인용에 사용되는 최소 단위이므로, 청크 경계가 “무엇이 검색되는가”를 결정합니다. 크기와 경계에는 서로 반대되는 실패 모드가 있습니다.
- 너무 크면: 한 청크에 여러 주제가 섞여 특정 질문과의 유사도가 희석될 수 있습니다. 검색된 청크가 길면 관련 없는 내용까지 LLM 프롬프트에 들어가 생성 품질과 비용, 지연에 부담을 줍니다.
- 너무 작으면: 문맥이 끊깁니다. “그 한도는 20만원이다” 같은 문장만 남으면, 그것이 무엇의 한도인지(숙박비인지 식비인지) 알 수 없어 검색에도, 생성에도 도움이 되지 않습니다.
즉 청크는 하나의 완결된 의미 단위가 되도록 자르는 것이 이상적입니다. 문제는 문서마다 그 단위가 다르다는 점입니다.
2. 청킹 전략
같은 문서라도 어떤 기준으로 자르느냐에 따라 청크의 모양이 달라집니다. 대표적인 세 가지 접근을 비교하면 다음과 같습니다.
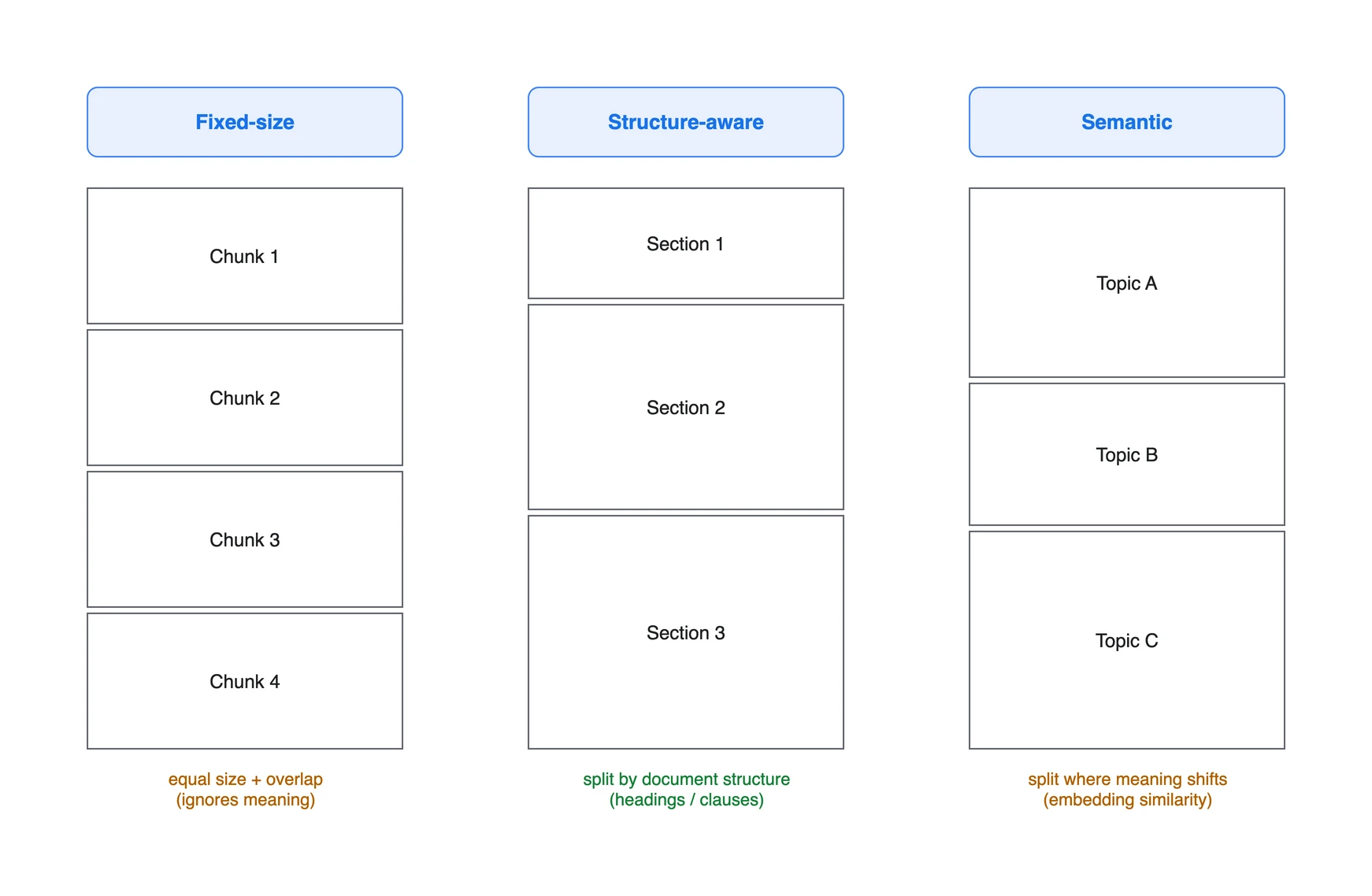
2.1. Fixed-size Chunking (고정 크기 + overlap)
토큰 또는 문자 수를 기준으로 일정 크기마다 자르고, 인접 청크가 일부 겹치도록 overlap을 둡니다. overlap은 경계에서 문맥이 끊기는 위험을 줄이지만, 저장량과 중복 검색 후보를 늘립니다. 단순하고 예측 가능하지만 의미 경계를 무시하므로 문장이나 조항 중간이 잘릴 수 있습니다.
청크 크기와 overlap의 보편 최적값은 없습니다. 먼저 답변에서 인용해야 하는 최소 근거 단위와 임베딩 모델의 입력 한도를 정한 뒤, 대표 질의로 recall과 답변 근거 충실도를 함께 측정해 조정합니다.
2.2. Recursive / Structure-aware Chunking (구조 인식 분할)
문서의 구조(제목, 문단, 리스트, 표 등)를 우선 경계로 삼아 자릅니다. 먼저 큰 단위(섹션)로 나누고, 너무 크면 문단, 문장 순으로 재귀적으로 쪼갭니다. 정책 문서처럼 “조/항/호” 같은 구조가 명확한 문서에 잘 맞습니다. 마크다운/HTML(Confluence)의 헤딩 구조를 활용하면 청크가 자연스러운 의미 단위로 떨어집니다.
2.3. Semantic Chunking (의미 기반 분할)
문장 단위 임베딩의 유사도가 급격히 바뀌는 지점을 경계로 삼아, 의미가 이어지는 문장들을 한 청크로 묶습니다. 의미 응집도가 높은 청크를 만들 수 있지만, 사전 임베딩 계산 비용이 들고 항상 고정 크기보다 낫다고 보장되지는 않습니다(도메인에 따라 결과가 갈립니다).
2.4. Parent-Child (Small-to-Big)
검색은 작은 청크로 하되, LLM에 넘길 때는 그 청크가 속한 더 큰 부모 청크(또는 원문 구간)를 함께 제공합니다. “검색 정밀도(작은 청크)”와 “생성 문맥(큰 청크)”을 분리해 둘 다 취하는 방식입니다. 정책 문서에서 특정 조항으로 검색한 뒤, 답변에는 해당 조 전체를 근거로 주고 싶을 때 유용합니다.
2.5. 전략 비교
| 전략 | 경계 기준 | 장점 | 주의점 |
|---|---|---|---|
| Fixed-size | 토큰/문자 수 | 단순, 예측 가능 | 의미 경계 무시, 중간 잘림 |
| Recursive | 문서 구조 | 구조 있는 문서에 적합 | 구조가 없는 문서엔 효과 제한 |
| Semantic | 임베딩 유사도 | 높은 의미 응집도 | 사전 계산 비용, 이득 불확실 |
| Parent-Child | 검색/생성 분리 | 정밀도와 문맥 동시 확보 | 저장/구현 복잡도 증가 |
정답은 하나가 아닙니다. 혼합 소스라면 포맷별로 전략을 달리 적용(구조 있는 위키는 recursive, 평문 PDF는 fixed+overlap)하는 것도 실용적입니다.
3. 임베딩 모델 선택 기준
청크 경계를 정했다면, 그 청크와 사용자 질문을 같은 벡터 공간에 놓을 임베딩 모델을 고릅니다. 임베딩 모델은 의미 기반 검색의 후보 품질을 결정하므로 다음 조건을 함께 봅니다.
- 벡터 차원(dimension): 차원이 크면 표현력이 늘지만 저장/검색 비용도 늘어납니다. 검색 품질과 비용의 균형점을 봅니다.
- 최대 입력 길이(context length): 청크 크기 전략과 맞아야 합니다. 청크가 모델 입력 한도를 넘으면 잘려서 임베딩됩니다.
- 도메인/언어 적합성: 한국어 정책 문서라면 한국어(또는 다국어) 성능이 중요합니다. 벤치마크(예: MTEB) 점수와 함께 실제 코퍼스로 검증합니다.
- 운영 방식: API형(간편, 데이터 외부 전송)과 self-host형(데이터 통제, 운영 부담)의 trade-off가 있습니다. 사내 정책 문서처럼 민감한 데이터라면 데이터 전송 경계가 중요한 선택 기준입니다(5편에서 다룹니다).
- 일관성: 인덱싱과 질의에는 호환되는 같은 임베딩 모델과 전처리 방식을 써야 합니다. 모델, 차원, 정규화 방식이 바뀌면 기존 벡터를 새 설정으로 다시 만들어야 합니다.
4. 청킹의 근본 문제: 맥락 손실
청킹에는 전략과 무관한 공통 약점이 있습니다. 청크를 잘라내는 순간, 각 청크가 원문 어디에 속했는지에 대한 맥락이 사라진다는 점입니다.
예를 들어 어떤 정책 문서의 한 청크가 “본 한도는 직전 분기 대비 10% 이내로 조정한다”라고만 되어 있다면, 이것이 어느 정책의, 무슨 한도에 대한 규정인지 청크 자체로는 알 수 없습니다. 임베딩은 이 애매한 문장을 그대로 벡터화하므로, “출장 숙박비 한도”를 물어도 이 청크가 검색되지 않을 수 있습니다. 문서 전체를 읽는 사람에게는 자명한 맥락이, 잘린 청크에는 없는 것입니다.
5. Contextual Retrieval
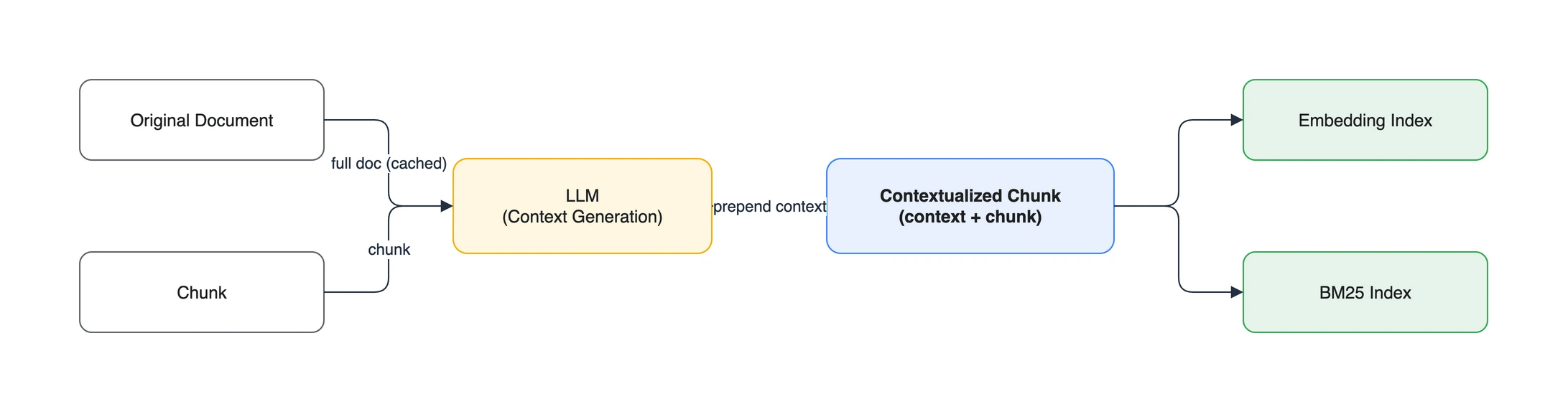
Anthropic이 제안한 Contextual Retrieval은 이 맥락 손실을 정면으로 다룹니다. 핵심은 각 청크를 색인하기 전에, 그 청크가 원문에서 갖는 맥락을 짧게 생성해 청크 앞에 덧붙이는(prepend) 것입니다. 공개 구현 설명에서 맥락은 보통 50-100 토큰이며, LLM에 원문 전체와 해당 청크를 함께 주어 생성합니다. 여기서 BM25(Best Matching 25)는 정확한 단어와 구문 일치를 점수화하는 키워드 검색 함수입니다.
앞의 예시 청크는 다음과 같이 보강됩니다.
1
2
3
4
5
# 생성된 맥락(prepend)
이 청크는 "2026년 국내 출장 규정"의 숙박비 한도 조정 조항에 속한다.
# 원본 청크
본 한도는 직전 분기 대비 10% 이내로 조정한다.
이렇게 맥락이 덧붙은 텍스트를 임베딩과 BM25 색인 양쪽 모두에 사용합니다. 그러면 “출장 숙박비 한도 조정” 같은 질문에서 청크 자체에 없던 문서 및 섹션 정보도 검색 신호로 쓸 수 있습니다.
5.1. 효과
Anthropic은 코드베이스, 소설, arXiv 논문, 과학 논문을 포함한 평가에서, 상위 성능 임베딩 구성과 top-20 검색을 사용해 1 - recall@20을 검색 실패율로 보고했습니다. 그 공개 결과는 다음과 같습니다.
| 구성 | 검색 실패율(top-20) | 감소폭 |
|---|---|---|
| 기본 임베딩(baseline) | 5.7% | - |
| + Contextual Embeddings | 3.7% | 35% |
| + Contextual BM25 | 2.9% | 49% |
| + Reranking | 1.9% | 67% |
이 수치는 각 구성의 효과가 해당 평가 조건에서 누적된 결과입니다. 다른 임베딩 모델, 청크 경계, 코퍼스, top-k에서는 같은 폭을 기대할 수 없습니다.
위 수치는 Anthropic이 공개한 다도메인 평가의 top-20 관측값입니다. 사내 정책 문서의 질의와 정답 근거로 baseline, Contextual Retrieval, reranking을 같은 조건에서 비교해야 도입 효과를 판단할 수 있습니다.
5.2. 비용과 상쇄
청크마다 LLM을 호출해 맥락을 생성하므로 인덱싱 비용과 시간이 듭니다. 같은 원문에서 여러 청크를 만들 때는 prompt caching으로 원문 입력을 재사용할 수 있습니다. 다만 캐시 정책, 문서 길이, 청크 수, 모델 가격이 모두 비용을 바꾸므로, 현재 모델 가격과 실제 문서 표본으로 일회성 인덱싱 비용을 계산해야 합니다.
6. 메타데이터 설계
인덱싱의 마지막 산출물은 벡터만이 아닙니다. 청크 텍스트와 벡터에 문서 식별자 및 권한 정보를 연결해야, 다음 검색 단계가 올바른 범위를 찾고 답변이 출처를 되짚을 수 있습니다.
- 필터링/성능: 부서/문서 유형으로 검색 범위를 좁혀 정확도와 속도를 높입니다(3편).
- 접근제어: 문서별 권한(열람 가능 역할)을 메타데이터로 두고, 검색 시점에 사용자 권한과 대조해 결과를 필터링합니다(5편의 핵심).
- 출처(citation): 문서 ID, 제목, 페이지/섹션을 저장해 답변에 근거를 붙입니다(7편).
- 최신성: 개정일을 저장해 오래된 규정과 최신 규정을 구분하거나 재색인 대상을 관리합니다.
정책 문서 RAG의 예시 메타데이터 스키마는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
chunk:
id: policy-travel-2026#c012
text: "..." # (Contextual Retrieval 적용 시 맥락 prepend된 텍스트)
embedding: [...]
metadata:
doc_id: policy-travel-2026
title: "2026 국내 출장 규정"
source: confluence # pdf | confluence | wiki
department: hr
access_roles: [employee, hr] # 접근제어 근거 (5편)
section: "제3조 숙박비"
updated_at: 2026-05-01
접근제어에 쓸 권한 메타데이터는 인덱싱 시점에 정확히 부여해야 합니다. 누락되거나 오래되면(stale) 권한 필터가 새거나 과하게 막습니다. 이 문제는 5편에서 자세히 다룹니다.
7. 정책 문서에 적용할 때
- 혼합 소스 파싱: PDF는 표/레이아웃 때문에 파싱이 까다롭고, Confluence/위키는 HTML 구조가 있어 recursive 분할에 유리합니다. 소스별로 파이프라인을 분기하는 편이 현실적입니다.
- 구조 보존: “조/항/호” 같은 조항 구조를 메타데이터(section)로 보존하면, 검색 정확도와 citation 품질이 함께 올라갑니다.
- 맥락 보강: 조항만 잘라내면 맥락이 약하므로, Contextual Retrieval이나 parent-child로 상위 맥락을 함께 확보합니다.
- 재색인 전략: 정책은 개정됩니다. 개정일 메타데이터와 문서 단위 재색인 파이프라인을 처음부터 설계해 둡니다.
8. 시리즈 맵
- (1) RAG 개념과 파이프라인 Overview - LLM 한계, 파이프라인, 세 가지 목표
- (2) 청킹/임베딩과 Contextual Retrieval - 청킹 전략, 임베딩 선택, 맥락 손실 보완, 메타데이터 (현재 글)
- (3) 벡터 DB와 인덱스 - HNSW/IVF, pgvector vs Qdrant, 메타데이터 필터링
- (4) 검색 정확도 - Hybrid Search(BM25 + dense), RRF 융합, reranking
- (5) 보안과 접근제어(DevSecOps) - RBAC/metadata filtering, PII 처리, prompt injection, 캐시-권한 충돌
- (6) 지연 최적화와 평가 - 캐싱, 인덱스 튜닝, top-k, Ragas
- (7) LLM API 연동과 고급 - citation/grounding, GraphRAG/Agentic RAG
9. Reference
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi