RAG 지연 최적화와 평가 - 캐싱, 인덱스 튜닝, Ragas [RAG 6]

지금까지의 시리즈에서 검색 품질을 높이는 인덱싱, 벡터 DB, hybrid search와 접근제어를 다뤘습니다. 실제 서비스에 올리면 그다음으로 마주치는 문제는 응답이 느리다는 점입니다. RAG는 매 질문마다 검색과 생성을 모두 수행하므로 단계마다 지연이 쌓이고, 정확도를 높이려 붙인 reranking이나 접근제어가 다시 지연을 늘립니다. 이번 글에서는 RAG의 지연을 어디서 줄이는지(캐싱, 인덱스 튜닝, top-k), 그리고 그렇게 줄이는 과정에서 정확도가 떨어지지 않는지를 어떻게 측정하는지(Ragas)를 살펴봅니다.
- RAG 지연은
retrieval + (reranking) + generation으로 쌓입니다. 평균만 보지 말고 서비스 SLO에 맞는 p95 또는 p99와 단계별 시간을 함께 기록합니다.- ANN 인덱스 파라미터(HNSW
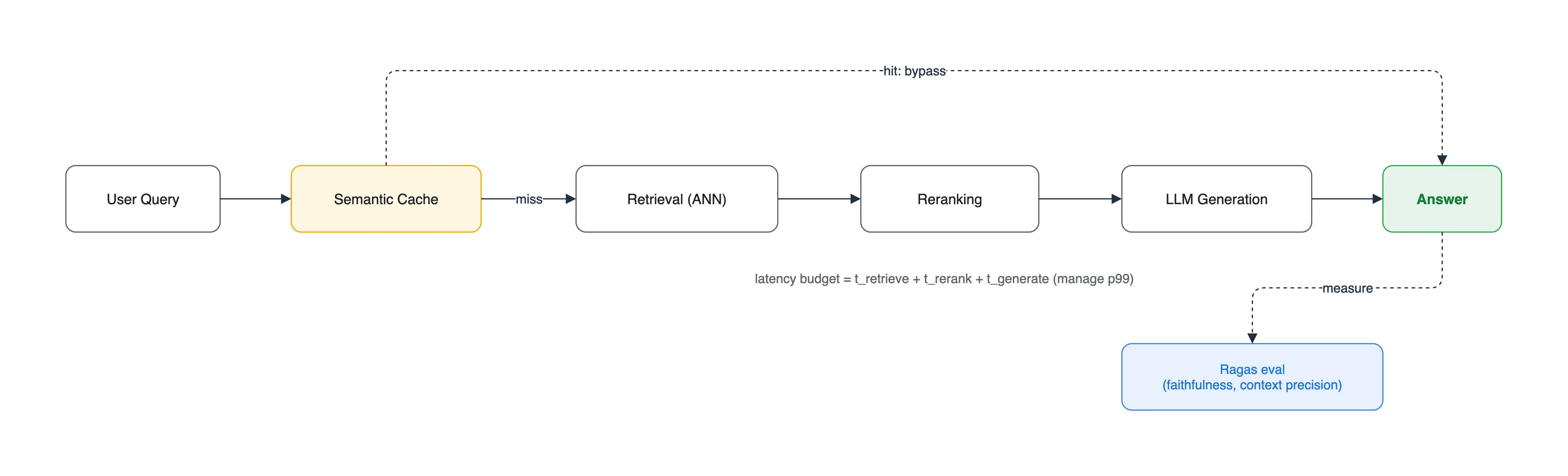
ef_search, IVFnprobe)와 top-k는 recall과 지연을 맞바꾸는 손잡이입니다. 목표 recall을 먼저 정하고 그 안에서 지연을 최소화합니다.- Semantic cache는 유사 질의의 검색 결과 또는 응답을 재사용하지만, 반환 전 현재 요청의 인가를 다시 확인해야 합니다.
- Prompt caching은 지정한 breakpoint까지의 동일한 prefix를 재사용합니다. 정적 문맥은 앞에, 질의처럼 바뀌는 내용은 그 뒤에 둡니다.
- 평가는 검색과 생성으로 나눕니다. Ragas의 Faithfulness와 Context Precision 같은 지표는 회귀 신호이며, 정답 셋과 사람 검토를 대체하지 않습니다.
1. 지연 예산(latency budget) 분해
RAG의 응답 지연은 단일 값이 아니라 여러 단계의 합입니다.
1
응답 지연 = retrieval + (reranking) + generation
일반 LLM 호출과 달리 RAG는 매 질문마다 검색을 먼저 수행하고, 정확도를 위해 reranking을 붙이면 검색 결과를 다시 한번 모델에 통과시키며, 그다음 생성이 이어집니다. 단계마다 지연이 누적되므로, 어느 단계가 병목인지 분리해서 봐야 최적화 지점을 찾을 수 있습니다.
지연을 관리할 때는 평균만으로 충분하지 않습니다. 평균이 정상이어도 일부 요청이 크게 느리면 사용자 경험과 timeout 오류가 나빠집니다. SLO가 정한 p95 또는 p99 같은 tail 지표를 선택하고, retrieval, reranking, generation을 각각 측정해 병목을 찾습니다. 생성 토큰 수, 후보 수, 캐시 hit 여부, 모델과 인덱스 버전도 같은 로그에 남겨야 비교할 수 있습니다.
2. ANN 인덱스 튜닝: recall vs latency
RAG 3편에서 다룬 ANN 인덱스는 정확도(recall)와 지연을 맞바꾸는 파라미터를 제공합니다.
- HNSW의
ef_search: 탐색 시 유지하는 후보 리스트 크기입니다. 키우면 더 많은 후보를 살펴 recall이 오르지만 지연도 늘고, 줄이면 반대로 빨라지지만 recall이 떨어집니다. - IVF의
nprobe: 조회할 클러스터(cell) 수입니다. 키우면 더 많은 영역을 뒤져 recall이 오르지만 지연이 늘고, 줄이면 반대가 됩니다.
두 파라미터 모두 탐색 범위를 넓히는 손잡이지만, 실제 효과는 데이터 분포와 구현에 따라 달라집니다. 목표 recall을 먼저 정하고, 그 recall을 만족하는 값 중 지연이 가장 낮은 지점을 찾습니다. 인덱스 파라미터를 바꿀 때는 같은 질의와 같은 정답 문서로 recall@k, 검색 시간, 메모리 사용량을 함께 비교합니다.
3. top-k 조정
검색에서 몇 개의 청크를 가져올지(top-k)도 지연과 정확도를 함께 움직입니다.
- 너무 많이 가져오면: 이후 reranking과 generation이 처리할 양이 늘어 지연과 비용이 커집니다. 특히 reranker는 후보 수에 비례해 느려집니다.
- 너무 적게 가져오면: 정작 필요한 청크가 후보에 들어오지 못해 recall이 손실됩니다.
RAG 4편에서 다룬 흐름이 이 딜레마의 해법입니다. 검색 단계에서는 넉넉히 가져오되(over-retrieve), reranker로 관련도 높은 순서로 재정렬한 뒤 상위 top-N만 생성에 넘깁니다. 검색은 빠르고 넓게, reranking은 정밀하게, 생성에는 소수만 전달하는 구조로 recall과 지연을 동시에 잡습니다.
4. Semantic cache (approximate)
같은 질문이나 의미가 가까운 질문이 반복되면, 매번 벡터 DB를 조회하는 것은 낭비일 수 있습니다. Semantic cache는 질의 임베딩과 유사도 임계값으로 검색 결과 또는 응답을 재사용합니다. 임계값을 넓히면 hit rate는 오를 수 있지만 의미가 다른 질문에 이전 결과를 쓰는 오류가 늘 수 있습니다. 따라서 hit rate만 보지 말고 cache hit 질의의 정답률과 근거 적합성도 별도로 평가합니다.
semantic cache의 지연 이득은 질의 반복률, 임계값, 캐시할 값, 저장소 성능에 따라 달라집니다. 일반화된 절감률 대신 배포 환경에서 hit rate, hit 경로 지연, miss 경로 지연, cache hit 품질을 함께 측정합니다.
4.1. 접근제어와의 충돌 (보안 경고)
semantic cache는 RAG 5편에서 다룬 접근제어와 결합해야 합니다. 캐시가 사용자 권한을 구분하지 않으면, 다른 권한으로 얻은 검색 결과나 응답이 유사 질의에 재사용될 수 있습니다. tenant와 인가 문맥을 cache namespace에 포함하고, 반환 전 현재 요청의 인가를 다시 확인합니다. 문서 폐기나 정책 변경 때 캐시를 무효화하는 절차도 필요합니다.
격리 범위를 세분화하면 재사용 모집단이 줄어 hit rate가 낮아질 수 있습니다. 민감한 문서를 다루는 RAG에서는 이 비용을 감수하고 권한 경계를 기본값으로 둡니다.
5. Prompt caching과 cache breakpoint 함정
Semantic cache가 검색 단계를 줄인다면, prompt caching은 생성 단계의 LLM 입력 처리를 줄입니다. Anthropic의 prompt caching은 cache_control breakpoint까지의 tools, system, messages 순서의 전체 prefix를 재사용합니다. 시스템 프롬프트나 반복되는 문서처럼 매 요청 같은 블록에 적합합니다. 가격과 지원 모델은 바뀔 수 있으므로 배포 시점의 provider 문서를 확인합니다.
핵심은 cache breakpoint 위치입니다. 캐시는 앞에서부터 같은 prefix를 비교하므로, 매 요청 바뀌는 timestamp나 사용자 질의가 breakpoint 앞에 있으면 이후의 정적 문맥도 재사용되지 않습니다. 정적 시스템 지시와 반복 문서를 앞에 두고, 가변 질의는 breakpoint 뒤에 둡니다. 실제 요청의 cache read와 write token을 관측해 기대한 hit가 발생하는지 확인합니다.
정적 프롬프트와 문서는 prefix에 두고, 가변 query는 suffix에 둡니다. cache breakpoint는 정적 부분의 끝에 배치해야 그 앞부분이 재사용됩니다.
6. 평가(Evaluation)와 정확도 회귀 방지
지연 최적화는 recall이나 답변 품질을 낮출 수 있으므로, 변경마다 회귀 게이트가 필요합니다. 평가는 검색과 생성으로 나눕니다.
- 검색 평가: 사람이 검증한 정답 문서 또는 청크로 recall@k, MRR, nDCG, Context Precision을 봅니다. Context Precision은 관련 청크가 상위에 오는지를 평가하므로 정답 또는 기준 답변의 품질에 의존합니다.
- 생성 평가: Faithfulness는 응답이 제공된 문맥으로 지지되는지를 평가합니다. Ragas의 LLM 기반 지표는 하나 이상의 모델 호출을 사용하므로, 점수 자체도 평가 모델과 프롬프트의 영향을 받습니다. 정확한 정책 해석이나 고위험 답변은 표본 사람 검토를 함께 둡니다.
- 운영 평가: 같은 버전의 평가 셋에서 cache hit와 miss를 구분해 tail 지연, 오류율, 비용, 인가 실패를 기록합니다.
예를 들어 ef_search를 낮추거나 semantic cache를 켠 뒤 검색 recall, Context Precision, Faithfulness, 사람 검토 표본이 기준선 아래로 떨어지면 변경을 반려합니다. 이렇게 하면 지연 최적화가 정확도를 조용히 갉아먹는 것을 막을 수 있습니다.
7. 정리
지연과 품질은 함께 최적화해야 합니다. 인덱스 튜닝, top-k 축소, semantic cache, prompt caching은 지연을 줄일 수 있지만 검색 recall, 근거 적합성, 답변 품질을 바꿀 수 있습니다. 지연을 줄이는 변경마다 동일한 평가 셋에서 retrieval, generation, authorization 결과를 함께 확인하고, SLO와 품질 기준을 모두 만족할 때만 배포합니다. 다음 편에서는 검색 결과에 citation과 grounding을 붙이고, GraphRAG와 Agentic RAG 같은 고급 구성을 LLM API와 연동하는 방법을 다룹니다.
8. 시리즈 맵
- (1) RAG 개념과 파이프라인 Overview
- (2) 청킹/임베딩과 Contextual Retrieval
- (3) 벡터 DB와 인덱스
- (4) 검색 정확도: Hybrid Search + Reranking
- (5) 보안과 접근제어(DevSecOps)
- (6) 지연 최적화와 평가 (현재 글)
- (7) LLM API 연동과 고급
9. Reference
- Malkov and Yashunin - Efficient and Robust Approximate Nearest Neighbor Search Using HNSW Graphs
- Ragas Docs - Context Precision
- Ragas Docs - Available Metrics
- Anthropic Docs - Prompt caching
- arXiv - Proximity: Approximate Semantic Caching for RAG
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi