AWS 데이터 분석 스택 Overview

S3 버킷에는 로그, 이벤트, 각종 추출 데이터가 끊임없이 쌓입니다. 그런데 막상 “이 데이터를 SQL로 한 번 들여다보자”고 하면, 어디서부터 손대야 할지 막막할 때가 많습니다. 별도 DB로 적재(ETL)해야 하나? 권한은 어디서 거나? 카탈로그는 또 뭔가?
AWS는 이 “S3에 쌓인 데이터를 분석하는 일”을 여러 서비스의 조합으로 풉니다. Athena, Glue, S3 Tables, Lake Formation, Redshift가 각자 한 가지 역할을 맡고 맞물려 돌아갑니다. 이번 글에서는 이 조합, 즉 AWS 데이터 분석 스택의 전체 그림을 알아보겠습니다.
이 글은 AWS 데이터 분석 스택을 본격적으로 다루는 첫 편으로, 각 구성요소가 무엇이고 어떻게 맞물리는지 큰 그림을 잡는 데 집중합니다. (그 배경이 되는 데이터 분석 패러다임과 역사, 분산 SQL 엔진은 앞선 개념 편들에서 다뤘습니다. 추천 읽기 순서는 글 끝의 시리즈 맵에 정리해 두었습니다.) 개별 서비스의 깊은 이야기와, 실제로 권한을 다 줬는데도 쿼리가 안 되던 트러블슈팅은 다음 편들에서 하나씩 풀어갑니다.
TL;DR
- 분석 스택의 핵심 아이디어는 데이터를 옮기지 않고(query-in-place) S3에 둔 채로 SQL 하는 것입니다.
- 역할 분리: 엔진(Athena/Redshift) 이 쿼리, Glue Data Catalog 가 메타데이터(스키마), S3/S3 Tables 가 데이터, IAM + Lake Formation 이 권한을 맡습니다.
- 권한은 두 축입니다. IAM은 API/리소스 호출 권한, Lake Formation은 데이터 접근 권한. 레이크하우스 데이터는 둘 다 통과해야 합니다.
- Athena는 서버리스 ad-hoc 쿼리, Redshift는 지속적인 대규모 DW 워크로드에 강합니다.
1. 분석 스택의 등장 배경
1.1. 적재 방식에서 query-in-place로
전통적인 분석은 데이터를 데이터 웨어하우스(DW)로 적재한 뒤 쿼리하는 방식이었습니다. 정형화된 분석엔 깔끔하지만, 비용이 따릅니다. 원본(S3, RDB 등)에서 DW로 옮기는 ETL 파이프라인을 만들고 운영해야 하고, 원본이 바뀔 때마다 동기화 지연과 스토리지 중복이 생깁니다.
데이터 레이크 접근은 발상을 뒤집습니다. 데이터를 S3에 그대로 두고, 그 위에서 바로 SQL을 실행합니다(query-in-place). 적재 단계를 줄이고, 같은 데이터를 여러 엔진(Athena, Redshift, EMR 등)이 공유합니다. 새로운 분석이 필요해도 “또 적재 파이프라인부터” 만들 필요가 없습니다.
1.2. 데이터 레이크에서 레이크하우스로
다만 초기 데이터 레이크(S3 + Parquet/JSON 파일 더미)는 약점이 있었습니다. 파일을 직접 다루다 보니 트랜잭션(ACID)이 없고, 스키마 변경이 까다롭고, 잘못된 부분 수정(update/delete)이 어렵습니다. “그냥 읽기 전용 로그 분석”엔 충분해도, 정합성이 필요한 데이터엔 부족했습니다.
그래서 등장한 게 레이크하우스(lakehouse) 입니다. S3 위에 Apache Iceberg 같은 테이블 포맷을 얹어, 파일 더미를 “진짜 테이블”처럼 다룹니다. ACID 트랜잭션, 스키마 진화(schema evolution), 시간여행(time travel, 과거 스냅샷 조회) 같은 DW의 장점을 데이터 레이크의 유연함 위에서 얻습니다. AWS에서는 S3 Tables가 이 Iceberg 테이블을 관리형으로 제공합니다(이후 글에서 자세히 설명합니다).
1.3. 자연스럽게 갈라지는 역할
데이터를 S3에 두고 쿼리한다는 발상을 따라가면, 역할이 자연스럽게 나뉩니다.
- 데이터는 어디에 있나? -> S3 (요즘은 Iceberg 기반 S3 Tables까지)
- 이 데이터의 스키마(테이블/컬럼)는 누가 아나? -> Glue Data Catalog
- 실제로 SQL을 실행하는 건? -> Athena(서버리스) 또는 Redshift
- 아무나 다 보면 안 되는데, 권한은? -> IAM + Lake Formation
이 다섯 조각이 맞물린 게 분석 스택입니다. 하나씩 직접 만들지 않아도, 각 서비스가 표준 인터페이스로 연결돼 있어 조합만 이해하면 됩니다.
핵심은 “데이터 / 메타데이터 / 엔진 / 권한” 이 분리돼 있다는 점입니다. 이 분리를 머릿속에 그려두면 나머지가 전부 그 자리에 들어맞습니다.
2. 구성요소 한눈에 보기
먼저 큰 그림부터 봅니다.
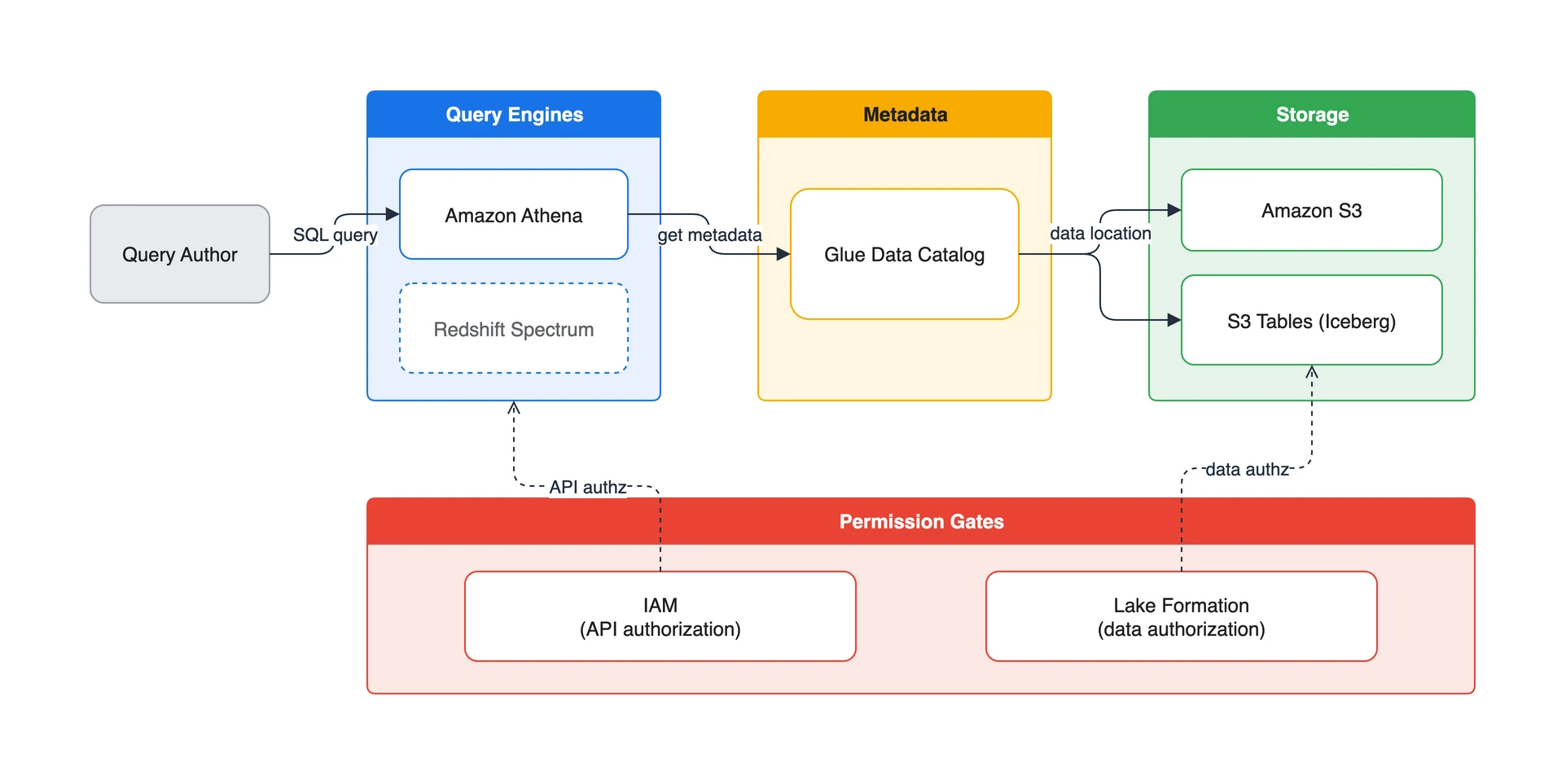
각 구성요소를 한 줄로 정의하면 다음과 같습니다.
| 계층 | 구성요소 | 한 줄 정의 |
|---|---|---|
| 엔진 | Amazon Athena | 서버리스 SQL 쿼리 엔진 (Trino/Presto 계보), 쿼리당 과금 |
| 엔진 | Amazon Redshift | 클라우드 데이터 웨어하우스, Spectrum으로 S3 외부 데이터도 쿼리 |
| 메타데이터 | AWS Glue Data Catalog | DB/테이블/컬럼 스키마의 중앙 메타스토어 (여러 엔진이 공유) |
| 저장 | Amazon S3 | 원본 데이터 (Parquet/JSON/CSV 등) |
| 저장 | Amazon S3 Tables | 관리형 Apache Iceberg 테이블 버킷 (레이크하우스) |
| 권한 | AWS IAM | AWS API/리소스 호출 권한 |
| 권한 | AWS Lake Formation | Data Catalog 리소스와 데이터에 대한 fine-grained 접근 권한 |
여기서 메타데이터(Glue Data Catalog)의 위상을 한 번 더 짚어둘 필요가 있습니다. 분석 스택에서 “테이블”이란 곧 Glue Data Catalog의 엔트리입니다. S3의 파일 그 자체가 아니라, “이 위치의 파일들은 이런 스키마의 테이블”이라는 정의가 Catalog에 들어 있고, Athena/Redshift/EMR이 그 정의를 공유합니다. 그래서 한 곳(Catalog)에서 테이블을 정의하면 여러 엔진이 같은 테이블을 봅니다.
위 그림에서는 Glue Data Catalog 를 하나로 단순화했습니다. 실제로는 기본 카탈로그(default) 안에 S3 Tables용 federated 카탈로그(
s3tablescatalog)가 중첩되는데, 이 구조는 S3 Tables와 Catalog Federation을 다루는 글에서 자세히 설명합니다. 이 글에서는 “메타데이터는 Glue Catalog가 맡는다” 정도로 충분합니다.
3. 쿼리 한 번이 지나는 길 (데이터 & 권한 흐름)
분석 스택을 이해하는 가장 빠른 길은 SQL 쿼리 한 번이 어떤 경로를 지나는지 따라가 보는 것입니다.
1
2
3
4
5
-- Athena 쿼리 에디터에서
SELECT user_id, count(*) AS cnt
FROM logs_db.app_events
WHERE dt = '2026-03-17'
GROUP BY user_id
3.1. 쿼리가 지나는 4단계
이 쿼리가 실행되면 대략 이런 일이 벌어집니다.
- 쿼리 제출: 사용자가 Athena에 SQL을 던집니다 (
StartQueryExecution). 이때 어느 workgroup에서 실행할지가 정해지고, 결과 저장 위치와 스캔 한도 같은 정책이 적용됩니다. - 메타데이터 조회: Athena가
logs_db.app_events테이블이 어디 있는지 Glue Data Catalog에 묻습니다. Catalog는 스키마(컬럼/타입)와 실제 데이터의 S3 위치(LOCATION), 파티션 정보를 돌려줍니다. - 데이터 읽기: Catalog가 알려준 위치의 S3(또는 S3 Tables) 데이터를 스캔합니다. 이때
WHERE dt = ...같은 파티션 필터가 있으면 해당 파티션만 읽어 스캔량(=비용)을 줄입니다. - 결과 반환: Athena는 쿼리 결과를 클라이언트에 바로 흘려보내는 것이 아니라, 1번에서 정해진 workgroup의 query result location(S3)에 먼저 기록한 뒤 그곳에서 읽어 반환합니다. 그래서
GetQueryResults호출과 별개로, 결과 위치의 S3 객체에 직접 접근하면 같은 결과를 받을 수 있습니다.
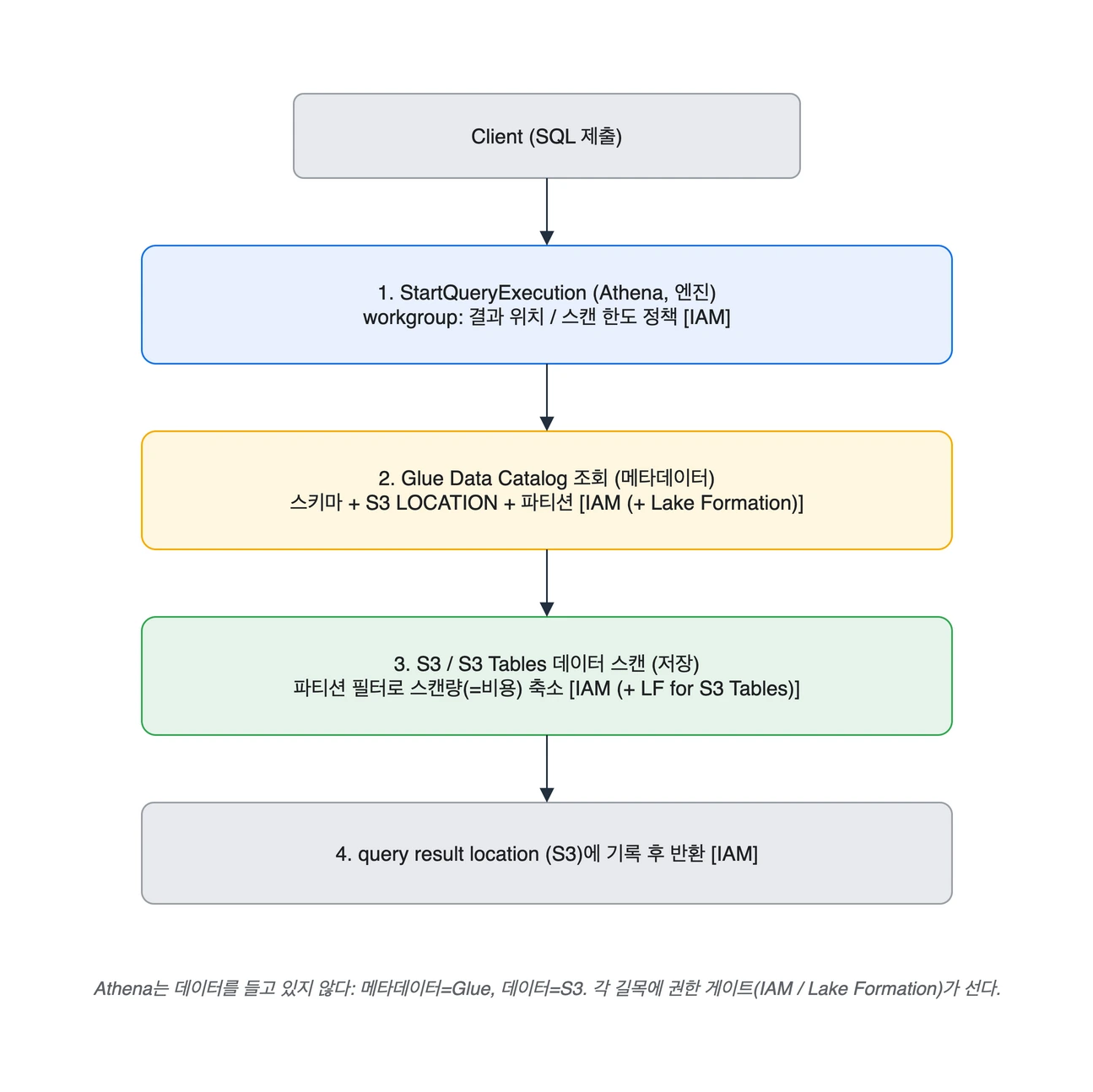 쿼리 제출(Athena, 엔진) -> 메타데이터 조회(Glue Catalog) -> 데이터 스캔(S3/S3 Tables) -> 결과 위치(S3) 기록. 각 길목에 IAM(+ Lake Formation) 권한 게이트가 선다.
쿼리 제출(Athena, 엔진) -> 메타데이터 조회(Glue Catalog) -> 데이터 스캔(S3/S3 Tables) -> 결과 위치(S3) 기록. 각 길목에 IAM(+ Lake Formation) 권한 게이트가 선다.
즉 Athena 자체는 데이터를 들고 있지 않습니다. 메타데이터는 Glue Catalog에, 데이터는 S3에 있고, Athena는 그 둘을 엮어 실행할 뿐입니다. 결과 역시 Athena가 보관하는 것이 아니라 S3의 결과 위치에 떨어집니다.
Amazon Athena automatically stores query results and query execution result metadata for each query that runs in a query result location that you can specify in Amazon S3.
– Amazon Athena User Guide, Work with query results and recent queries
3.2. 모든 길목의 권한 게이트 (두 축)
그리고 이 흐름의 모든 길목에 권한 게이트가 있습니다. 여기가 분석 스택에서 가장 헷갈리는 지점이라, 시리즈 내내 반복해서 다룰 주제입니다. 권한은 두 축으로 나뉩니다.
| 축 | 무엇을 통제하나 | 예시 |
|---|---|---|
| IAM | AWS API/리소스 호출 권한 | athena:StartQueryExecution, glue:GetTable |
| Lake Formation | Data Catalog 리소스/데이터 접근 권한 | 특정 테이블에 SELECT/DESCRIBE grant |
IAM 쪽은 “이 주체가 이 API를 이 리소스에 호출할 수 있는가”를 봅니다. 위 표의 두 예시(athena:StartQueryExecution로 쿼리를 제출하고, glue:GetTable로 테이블 메타데이터를 읽는 것)를 그대로 정책으로 옮기면, 호출 주체에게 다음과 같은 IAM 권한이 있어야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RunAthenaQuery",
"Effect": "Allow",
"Action": ["athena:StartQueryExecution", "athena:GetQueryExecution", "athena:GetQueryResults"],
"Resource": "arn:aws:athena:ap-northeast-2:<account-id>:workgroup/primary"
},
{
"Sid": "ReadGlueMetadata",
"Effect": "Allow",
"Action": ["glue:GetTable", "glue:GetTables", "glue:GetDatabase", "glue:GetDatabases", "glue:GetPartitions"],
"Resource": [
"arn:aws:glue:ap-northeast-2:<account-id>:catalog",
"arn:aws:glue:ap-northeast-2:<account-id>:database/logs_db",
"arn:aws:glue:ap-northeast-2:<account-id>:table/logs_db/*"
]
}
]
}
athena:StartQueryExecution은 표의 IAM 축 첫 예시 그대로 1번 단계(쿼리 제출)를 통과시키고, glue:GetTable을 포함한 Glue read 액션은 2번 단계(메타데이터 조회)를 통과시킵니다. 결과를 다시 읽으려면 여기에 결과 위치 S3 버킷의 s3:GetObject가 추가로 필요합니다.
Lake Formation 쪽은 결이 다릅니다. IAM 정책이 아니라 grant 모델로, “이 주체에게 이 테이블의 SELECT를 부여한다”는 식입니다.
1
2
3
4
aws lakeformation grant-permissions \
--principal '{"DataLakePrincipalIdentifier":"arn:aws:iam::<account-id>:role/analytics-workload-role"}' \
--resource '{"Table":{"DatabaseName":"sales_db","Name":"orders"}}' \
--permissions SELECT DESCRIBE
핵심 규칙은 이렇습니다.
- Lake Formation에 등록되지 않은 일반 데이터(예: 평범한 Glue 테이블 + S3)는 IAM만으로 접근이 결정됩니다.
- Lake Formation에 등록된 데이터(예: S3 Tables 레이크하우스)는 IAM 통과 + Lake Formation grant를 둘 다 만족해야 합니다.
이 “IAM만으로 결정”이 동작하는 메커니즘이 IAMAllowedPrincipals 그룹입니다. Lake Formation에 등록되지 않은 리소스에는 이 가상 그룹의 permission이 붙어 있어, Lake Formation이 접근 판단을 IAM 정책에 위임합니다. 즉 “LF 미등록 = IAM only”는 LF가 권한을 안 보는 게 아니라, IAMAllowedPrincipals 덕분에 LF 검사를 통과시켜 IAM에 넘기는 것입니다.
AWS Glue resource
A resources that is not registered with Lake Formation. Users require only IAM permissions to access the resource because it hasIAMAllowedPrincipalsgroup permissions. Lake Formation permissions are not enforced.
그래서 한 리소스의 상태는 “IAM only(LF 미등록)”와 “LF 강제(둘 다 필요)”의 양극단만 있는 게 아니라, 그 사이에 hybrid access mode라는 중간 단계가 있습니다. hybrid로 등록한 S3 위치는, opt-in한 주체에게는 IAM + LF grant를 둘 다 요구하고, opt-in하지 않은 기존 주체는 그대로 IAM만으로 접근하게 둡니다. 기존 워크로드를 끊지 않고 Lake Formation을 점진 도입할 때 쓰는 경로이며, 자세한 동작은 Lake Formation 편에서 다룹니다.
이 “두 축” 때문에 실무에서 가장 흔한 함정이 생깁니다. IAM 권한을 완벽하게 줬는데도 쿼리가 안 되는 상황입니다. Lake Formation grant가 빠졌기 때문이며, 이 이야기는 시리즈 마지막 편에서 실제 디버깅 과정으로 다룹니다.
4. Athena vs Redshift - 언제 무엇을
분석 스택에는 SQL 엔진이 둘 있습니다. “뭘 써야 하나” 고민하기 전에, 각각이 무엇인지부터 짚습니다.
4.1. Amazon Athena란
Amazon Athena는 서버리스 SQL 쿼리 엔진입니다. 분산 SQL 엔진인 Trino/Presto 계보로, 클러스터를 프로비저닝하거나 운영할 필요 없이 S3에 있는 데이터에 바로 표준 SQL을 실행합니다. 과금은 쿼리가 스캔한 데이터량 기준이라, 띄워두는 고정비 없이 쓴 만큼만 냅니다. “S3 데이터를 적재 없이, 가끔, 빠르게” 보는 데 최적입니다.
4.2. Amazon Redshift란
Amazon Redshift는 클라우드 데이터 웨어하우스(DW)입니다. 데이터를 컬럼 기반 스토리지에 적재해 두고 MPP(massively parallel processing) 로 대규모 조인과 집계를 빠르게 처리합니다. provisioned 클러스터 또는 Redshift Serverless로 운영하며, 정형화된 BI 리포트나 동시성이 높은 워크로드에 강합니다. Redshift Spectrum을 쓰면 적재하지 않은 S3 데이터도 외부 테이블로 쿼리할 수 있습니다.
4.3. 둘의 차이
둘은 경쟁 관계라기보다 쓰임새가 다릅니다.
| 기준 | Amazon Athena | Amazon Redshift |
|---|---|---|
| 실행 모델 | 서버리스 | 클러스터 또는 Serverless |
| 과금 | 스캔한 데이터량(TB) 기준 | 노드 용량 또는 Serverless RPU 기준 |
| 적합한 워크로드 | ad-hoc 분석, 로그 탐색, 간헐적 쿼리 | 지속적 BI, 대규모 조인/집계, 높은 동시성 |
| 데이터 위치 | 주로 S3 직접 | 자체 스토리지 + Spectrum으로 S3 |
| 운영 부담 | 없음 | (provisioned 시) 클러스터 관리 |
가장 실질적인 차이는 과금과 데이터 위치입니다. Athena는 스캔량 과금이라 파티션 필터로 범위를 좁히는 것이 곧 비용 절감이고, 고정비가 없어 간헐적 워크로드에 경제적입니다. Redshift는 용량 기반이라 켜둔 만큼 비용이 들지만, 자체 스토리지와 MPP로 무거운 정형 워크로드를 안정적으로 빠르게 처리합니다.
4.4. 공존 - 같은 카탈로그 위에서
Redshift Spectrum은 Athena처럼 Glue Data Catalog의 외부 테이블(S3/S3 Tables)을 쿼리하며, 같은 Lake Formation 권한 체계를 따릅니다. 그래서 둘은 배타적이지 않습니다. 같은 Glue Data Catalog와 Lake Formation 위에서, Athena로 탐색하고 Redshift로 정형 워크로드를 돌리는 구성이 흔합니다. 간단한 선택 기준은 다음과 같습니다.
- “S3에 있는 데이터를 가끔, 빠르게 들여다보고 싶다” -> Athena
- “정형화된 대시보드/리포트를 매일 무겁게 돌린다” -> Redshift
이 시리즈는 Athena를 중심으로 진행합니다. 서버리스라 진입장벽이 낮고, 분석 스택의 모든 구성요소(Glue/S3 Tables/Lake Formation)와 맞물리는 모습을 가장 잘 보여주기 때문입니다.
5. 실습 맛보기 - Athena로 S3 데이터 쿼리하기
개념을 잡았으니, 분석 스택이 실제로 어떻게 맞물리는지 최소 예시로 감을 잡아봅니다. (서비스별 깊은 실습은 이후 글에서 다룹니다.)
전제: S3 버킷 s3://amzn-s3-demo-bucket/app-events/ 아래에 날짜 파티션으로 데이터가 쌓여 있다고 가정합니다.
5.1. 테이블 정의 (Glue Catalog에 등록)
데이터의 스키마와 위치를 Glue Data Catalog에 “테이블”로 등록합니다. Athena에서 DDL로 바로 만들 수 있습니다.
1
2
3
4
5
6
7
8
CREATE EXTERNAL TABLE IF NOT EXISTS logs_db.app_events (
user_id string,
event string,
ts timestamp
)
PARTITIONED BY (dt string)
STORED AS PARQUET
LOCATION 's3://amzn-s3-demo-bucket/app-events/';
이 DDL은 데이터를 옮기지 않습니다. “이 S3 위치의 Parquet 파일들을 이런 스키마로 본다”는 정의만 Catalog에 등록할 뿐입니다. 파티션을 인식시키려면 한 번 로드해 줍니다.
1
MSCK REPAIR TABLE logs_db.app_events;
5.2. 쿼리 실행 (파티션 필터 필수)
이제 SQL로 분석합니다. 큰 테이블은 반드시 파티션 필터를 걸어 스캔량(=비용)을 줄입니다.
1
2
3
4
5
6
SELECT event, count(*) AS cnt
FROM logs_db.app_events
WHERE dt = '2026-03-17' -- 파티션 필터로 해당 날짜만 스캔
GROUP BY event
ORDER BY cnt DESC
LIMIT 20;
결과는 다음과 같은 형태로 돌아오고, 동시에 결과 버킷(s3://<athena-results>/)에도 CSV로 저장됩니다.
1
2
3
4
5
event | cnt
--------------+-------
page_view | 48213
click | 12044
purchase | 932
5.3. 방금 무슨 일이 일어났나
이 짧은 실습에 분석 스택이 다 들어 있습니다.
CREATE EXTERNAL TABLE-> Glue Data Catalog에 메타데이터 등록 (데이터는 S3 그대로)SELECT-> Athena가 Catalog에서 위치를 받아 S3 데이터를 스캔WHERE dt = ...-> 파티션 프루닝으로 스캔량/비용 절감- 이 모든 호출이 IAM(API) 권한을 통과해야 하고, 데이터가 Lake Formation 관리 대상이면 LF grant까지 필요
MSCK REPAIR TABLE은 파티션이 많아지면 느려집니다. 운영에서는 partition projection(파티션을 패턴으로 계산)이나 Glue Crawler로 파티션을 관리하는 방식을 더 씁니다. 이 부분은 Glue를 다루는 글에서 설명합니다.
6. 시리즈 맵
이 시리즈는 개념 토대를 먼저 다지고, 그 위에서 AWS 스택을 깊이 들어갑니다. 추천 읽기 순서는 다음과 같습니다.
개념 토대
- 데이터 분석 아키텍처의 역사와 변천사 - 웨어하우스 -> 레이크 -> 레이크하우스로 진화한 흐름
- 데이터 웨어하우스 vs 데이터 레이크 vs 레이크하우스 - 세 패러다임의 차이
- 분산 SQL 엔진이란 - Trino/Presto - 쿼리 엔진의 동작 원리
AWS 데이터 분석 스택
- (이번 글) AWS 데이터 분석 스택 Overview - 구성요소와 전체 흐름
- Amazon Athena & Glue Data Catalog - 서버리스 쿼리 엔진과 메타스토어, fine-grained IAM
- S3 Tables & Catalog Federation - 관리형 Iceberg 레이크하우스, default vs federated 카탈로그
- AWS Lake Formation - IAM 위에 얹히는 데이터 접근 권한, grant와 credential vending
- Lake Formation 권한 Deep Dive - “권한을 다 줬는데 왜
CATALOG_NOT_FOUND일까” 실전 디버깅
개념을 차곡차곡 쌓은 뒤, 마지막 편에서 실제로 막히고 풀어낸 권한 트러블슈팅으로 시리즈를 닫습니다. AWS 공식 문서에는 잘 안 나오는, 실무에서만 만나는 종류의 이야기입니다.
7. Reference
- Amazon Athena - What is Amazon Athena?
- Athena - Using the AWS Glue Data Catalog
- Athena - Partition projection
- Amazon S3 Tables
- AWS Lake Formation - What is Lake Formation?
- Lake Formation - Access control for underlying data
- Amazon Redshift - What is Amazon Redshift?
- Apache Iceberg
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi