RAG 검색 정확도 - Hybrid Search와 Reranking [RAG 4]

RAG 2편에서 청킹과 임베딩을, 3편에서 벡터 DB와 인덱스를 살펴봤습니다. 그런데 dense 벡터 검색만으로는 검색 품질에 한계가 있습니다. 임베딩은 의미가 비슷한 문장을 잘 찾지만, “제3조” 같은 정확한 조항 번호나 고유명사, 제품명 매칭에는 오히려 약합니다. 이번 글에서는 dense 검색과 키워드 검색을 결합하는 Hybrid Search, 두 검색 결과를 합치는 RRF, 그리고 후보를 정밀 재정렬하는 Reranking을 살펴봅니다.
- dense(임베딩) 검색은 동의어와 문맥 같은 의미를, sparse(BM25 등) 검색은 질의에 실제로 등장한 용어를 찾는 데 각각 강점이 있습니다. 정책 문서는 두 신호를 함께 평가해야 합니다.
- Hybrid Search는 dense와 sparse를 함께 실행해 결과를 합칩니다.
- RRF(Reciprocal Rank Fusion)는 점수 스케일 대신 순위 위치로 결과를 융합합니다. Elasticsearch의 기본
rank_constant는60이지만, 후보 창 크기인rank_window_size도 함께 결과와 비용에 영향을 줍니다.- Reranking은 1차 검색 후보만 cross-encoder로 다시 점수화해 생성에 전달할 문맥을 고르는 단계입니다. 후보 수와 최종 top-N은 정답 셋과 지연 SLO로 결정합니다.
- 도입 판단은 검색 recall, 재정렬 후 순위 품질, tail 지연을 같은 평가 셋에서 함께 측정해야 합니다.
1. 왜 dense 검색만으로는 부족한가
임베딩 기반 dense 검색은 “숙박 지원금 한도”로 물어도 “출장 시 잠자리 비용 상한”처럼 표현이 다른 문서를 찾아냅니다. 의미 공간에서 가까운 것을 찾기 때문입니다. 반면 정확한 문자열을 그대로 찾는 데는 약합니다.
- 고유명사/식별자: 제품 코드
A-2201, 조항 번호 “제3조”, 특정 API 이름처럼 정확히 일치해야 하는 토큰은 임베딩 공간에서 다른 유사 토큰과 뒤섞여 정밀하게 매칭되지 않을 수 있습니다. - 드문 단어: 코퍼스에 거의 없는 희귀 용어는 임베딩이 충분히 학습되지 않아 위치가 불안정합니다.
반대로 BM25는 질의 용어의 문서 내 빈도와 코퍼스에서의 희소성을 이용해 문서를 점수화하는 전통적 lexical 검색 함수입니다. 따라서 “제3조”나 A-2201처럼 같은 토큰이 들어간 문서를 찾는 데 유용하지만, “숙박 지원금”과 “잠자리 비용”의 의미 관계를 스스로 알지는 못합니다. 정책 문서 RAG는 정확한 식별자와 자연어 표현이 섞인 질의를 다루므로, lexical 신호와 semantic 신호를 모두 후보 생성에 반영할지 평가로 결정해야 합니다.
2. Hybrid Search
Hybrid Search는 이름 그대로 두 검색을 함께 돌립니다. 같은 질의를 dense 검색기(임베딩 + 벡터 인덱스)와 sparse 검색기(BM25 등 키워드 인덱스)에 각각 보내, 각자의 상위 결과를 받은 뒤 하나의 순위로 합칩니다.
| 방식 | 강점 | 약점 |
|---|---|---|
| Dense (임베딩) | 동의어/문맥 등 의미 매칭 | 정확 키워드/고유명사에 약함 |
| Sparse (BM25) | 정확 키워드/희귀어 매칭 | 의미(동의어/문맥)를 못 잡음 |
| Hybrid | 두 강점 결합 | 결과 융합 로직이 필요 |
2편에서 소개한 Contextual Retrieval이 임베딩과 BM25 색인 양쪽에 맥락을 덧붙였던 이유도 여기에 있습니다. hybrid를 전제로 두 색인을 모두 준비해 두는 것입니다.
문제는 두 검색기의 결과를 어떻게 합치느냐입니다. dense와 sparse는 점수 체계가 완전히 달라 그냥 더할 수 없습니다.
3. RRF (Reciprocal Rank Fusion)
두 결과를 합칠 때 가장 먼저 떠오르는 방법은 점수를 더하는 것입니다. 그러나 이는 곧바로 문제에 부딪힙니다.
BM25와 벡터 유사도는 같은 의미의 점수가 아닙니다. 구현마다 유사도 함수, 정규화, 부스팅이 달라 raw 점수를 선형 결합하려면 별도 정규화와 가중치 검증이 필요합니다. RRF는 이 문제를 점수 대신 순위(rank)만 사용해 피합니다. 각 검색 결과에서 문서의 순위 위치만 보고 다음 공식으로 기여도를 계산합니다.
1
score(doc) = sum over each result list of 1 / (k + rank(doc))
rank는 각 리스트에서 문서의 순위(1위, 2위, …)이고 k는 rank constant입니다. 한 문서가 dense와 sparse 양쪽에서 상위에 오르면 두 기여가 합산되어 최종 순위가 올라갑니다. raw 점수를 쓰지 않으므로 스케일 비호환 문제가 사라집니다.
k는 순위별 기여의 감쇠를 조절하는 상수입니다. Elasticsearch에서 rank_constant의 기본값은 60입니다. 다만 구현에는 각 검색기의 후보 창을 정하는 rank_window_size도 있습니다. 창을 넓히면 낮은 순위 후보도 융합할 수 있지만, 검색 작업과 조정 비용이 늘 수 있습니다.
1
2
3
4
5
6
7
8
9
# 예시: 질의 "제3조 숙박비 한도"
Dense 결과: [docB, docA, docC] # 의미로 찾음
Sparse 결과: [docA, docD, docB] # "제3조" 키워드로 찾음
# k=60 기준
docA = 1/(60+2) + 1/(60+1) = 0.0325 # 양쪽 상위 -> 최종 1위
docB = 1/(60+1) + 1/(60+3) = 0.0323
docC = 1/(60+3) = 0.0159
docD = 1/(60+2) = 0.0161
양쪽 검색기에서 모두 상위에 오른 docA가 최종 상위로 올라갑니다. RRF는 서로 다른 검색기의 raw score를 억지로 맞추지 않아도 되는 단순한 시작점입니다. 그러나 rank_constant, 후보 창, 검색기별 후보 품질은 실제 정답 셋으로 확인해야 합니다.
RRF가 특정 데이터셋에서 얼마나 NDCG를 올리는지는 코퍼스와 질의 분포에 따라 크게 달라집니다. 여기서는 구체적 개선 수치를 인용하지 않으며, 도입 시 자기 데이터로 baseline 대비 측정하는 것을 권합니다.
4. Reranking
Hybrid + RRF로 후보 순위를 얻었어도, 이 순위가 항상 “질의에 가장 잘 답하는 순서”는 아닙니다. dense 임베딩은 질의와 문서를 각각 따로 벡터로 만든 뒤 거리를 재기 때문에(bi-encoder 방식), 질의와 문서 사이의 미묘한 관계를 놓칠 수 있습니다. Reranking은 이 1차 검색 결과를 정밀 모델로 다시 채점해 순서를 바로잡는 단계입니다.
핵심 아이디어는 두 가지입니다.
- Over-retrieve: 1차 검색(hybrid)에서 최종 필요량보다 많은 후보를 가져옵니다. 이 후보 수는 정답 청크가 포함되는 recall과 reranker 처리량을 함께 보고 정합니다.
- Cross-encoder 재채점: cross-encoder는 질의와 문서를 함께 하나의 입력으로 인코딩해 관련도를 점수화합니다. 둘을 같이 보므로 bi-encoder보다 정밀하지만, 질의-문서 쌍마다 모델을 한 번씩 돌려야 해서 무겁습니다. 그래서 전체 코퍼스가 아니라 1차로 좁혀진 후보에만 적용합니다.
즉 “빠르지만 거친” 1차 검색으로 후보를 좁히고, “느리지만 정밀한” cross-encoder로 후보만 재정렬하는 역할 분담입니다. bi-encoder는 문서 임베딩을 색인 시점에 미리 계산해 두므로 검색 시점에는 질의만 인코딩하면 되지만, cross-encoder는 질의가 들어와야 비로소 질의-문서 쌍을 계산할 수 있어 미리 캐시할 수 없습니다. 이 구조적 차이가 cross-encoder를 후보 재정렬에만 쓰는 근본 이유입니다.
5. 다단계 검색 파이프라인
지금까지의 단계를 이으면 다음과 같은 파이프라인이 됩니다.
1
2
3
4
5
6
질의
-> Hybrid Search (dense + sparse) # 후보 넉넉히 (over-retrieve)
-> RRF 융합 # 두 결과를 하나의 순위로
-> Reranking (cross-encoder) # 후보 재채점/재정렬
-> top-N 선택
-> LLM 프롬프트에 컨텍스트로 주입
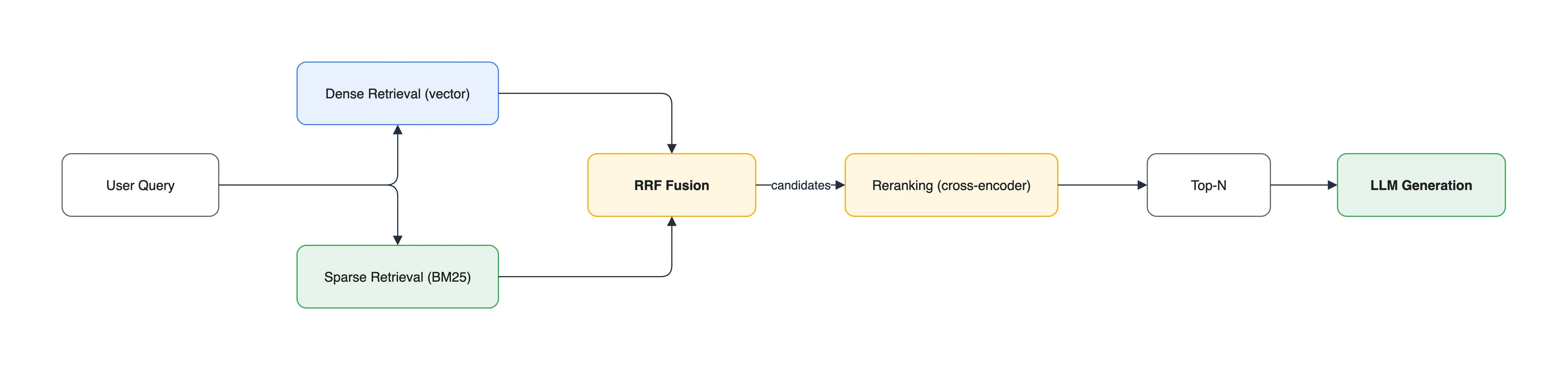
각 단계는 다음 단계의 후보 품질을 높이는 역할을 합니다. 다만 hybrid와 reranking의 이득은 코퍼스, 질의 유형, 정답 정의에 따라 달라집니다. 외부 벤치마크 수치를 일반화하지 말고, 배포 전에는 사내 평가 셋에서 1차 검색 recall과 최종 top-N의 순위 품질을 비교해야 합니다.
6. Reranking의 trade-off와 지연 예산
Reranking은 정확도를 크게 끌어올리지만 공짜가 아닙니다. cross-encoder가 후보 개수만큼 추가 연산을 하므로 검색 지연이 늘어납니다. 여기서 두 개의 손잡이를 함께 조절해야 합니다.
- Over-retrieve 폭: 후보를 많이 뽑을수록 정답 문서가 후보에 들어올 가능성은 커지지만, cross-encoder가 채점할 쌍도 늘어납니다.
- 지연 예산: 서비스 SLO에 맞는 tail 지연 지표를 정하고, 그 안에서 후보 수와 reranker 모델을 고릅니다.
reranking이 “몇 ms만 더한다”는 식의 일반화된 수치는 모델/하드웨어/후보 수에 따라 크게 달라지므로 신뢰하기 어렵습니다. 정확한 균형점은 자기 데이터와 자기 인프라에서 정확도 이득과 p99 지연을 함께 측정해 결정해야 합니다. 지연 최적화 자체는 6편에서 더 다룹니다.
reranking의 절대 지연(ms)이나 RRF의 NDCG 개선폭 같은 수치는 환경 의존성이 커서 이 글에서 인용하지 않습니다. 정확도 이득은 정성적으로 이해하되, 도입 결정은 자기 데이터 측정 결과로 내려야 합니다.
7. 질의 측 개선: Query Rewriting과 HyDE
지금까지는 검색 결과를 다루는 방법이었습니다. 질의 자체를 손보는 접근도 있습니다. 사용자의 질의와 색인된 문서 사이에는 표현 격차가 있기 마련인데(짧은 구어체 질의 vs 격식체 정책 문서), 이 격차를 줄이는 방향의 기법들입니다.
- Query Rewriting: 원 질의를 검색에 유리하게 재작성하거나 여러 변형으로 확장합니다. 모호한 질의를 구체화하거나 동의어를 덧붙여 recall을 높이는 식입니다.
- HyDE (Hypothetical Document Embeddings): 질의에 대한 가상의 답변 문서를 LLM으로 먼저 생성하고, 그 가상 문서의 임베딩으로 검색합니다. 질의보다 실제 문서에 형태가 가까운 텍스트로 검색하므로 질의-문서 표현 격차를 줄일 수 있습니다.
두 기법 모두 추가 LLM 호출 비용과 지연을 수반하고, 재작성된 질의나 가상 문서가 원 의도에서 벗어나면 오히려 검색 품질을 해칠 수 있습니다. 따라서 hybrid + reranking으로 부족할 때 선택적으로 얹는 개념으로 보고, 도입 시에는 원 질의만 쓴 경우와 정확도를 비교해 이득을 확인하는 편이 안전합니다.
8. 시리즈 맵
- (1) RAG 개념과 파이프라인 Overview
- (2) 청킹/임베딩과 Contextual Retrieval
- (3) 벡터 DB와 인덱스
- (4) 검색 정확도: Hybrid Search + Reranking (현재 글)
- (5) 보안과 접근제어(DevSecOps)
- (6) 지연 최적화와 평가
- (7) LLM API 연동과 고급
9. Reference
- Robertson et al. - Okapi at TREC-3
- Cormack et al. - Reciprocal Rank Fusion outperforms Condorcet and Individual Rank Learning Methods
- Elastic Docs - Reciprocal rank fusion
- Sentence Transformers Docs - Retrieve and re-rank
- Gao et al. - Precise Zero-Shot Dense Retrieval without Relevance Labels
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi