Apache Iceberg 테이블 포맷 Deep Dive - 메타데이터 계층과 ACID, 그리고 진화

앞선 Amazon Athena & Glue Data Catalog 글에서는 일반 Glue 테이블(S3 + Parquet 파일 + Glue Catalog)을 기준으로 쿼리 흐름과 권한을 정리했습니다. 그런데 다음 편에서 다룰 S3 Tables는 “관리형 Iceberg 레이크하우스”입니다. 즉 S3 Tables를 제대로 이해하려면 그 바탕에 깔린 Apache Iceberg 테이블 포맷이 무엇인지 먼저 알아야 합니다.
Iceberg는 AWS 전용 기능이 아니라, S3 같은 객체 스토리지 위의 파일을 테이블로 관리하는 오픈 테이블 포맷(open table format) 입니다. 파일 위치와 현재 메타데이터 위치는 카탈로그(catalog) 가 관리하고, 메타데이터가 어떤 파일이 현재 테이블에 속하는지 결정합니다. 이번 글에서는 AWS 맥락을 잠시 내려놓고, Iceberg 자체의 구조와 동작 원리를 깊이 들여다봅니다. 메타데이터가 어떤 계층으로 쌓이는지, 시간여행과 스키마 및 파티션 진화가 어떻게 가능한지, 그리고 Copy-on-Write와 Merge-on-Read의 차이까지 정리합니다.
TL;DR
- Iceberg는 디렉터리가 아니라 개별 파일을 추적하는 테이블 포맷입니다. 메타데이터는 metadata file -> manifest list -> manifest file -> data file 4계층으로 쌓입니다.
- 테이블 상태 변경은 새 metadata file을 만들고 포인터를 원자적으로 교체합니다. 이 교체는 완결된 snapshot을 읽게 하는 기반이며, 쓰기 격리 수준은 작업과 카탈로그 구현의 검증 조건에 따라 결정됩니다.
- snapshot 단위로 과거 상태를 그대로 조회(time travel)하거나 되돌릴(rollback) 수 있습니다.
- 컬럼을 field id로 추적해 스키마 진화가 안전하고, partition evolution은 기존 데이터를 다시 쓰지 않습니다.
- 수정/삭제 반영 방식은 Copy-on-Write(파일 재작성)와 Merge-on-Read(delete file 기록 후 읽을 때 병합) 두 가지입니다.
1. 왜 Iceberg인가
1.1. 디렉터리가 곧 테이블이던 시절
초기 데이터 레이크에서 “테이블”은 사실상 S3 디렉터리(prefix) 하나였습니다. Hive 방식이 대표적입니다. s3://bucket/orders/dt=2026-04-14/ 아래에 쌓인 Parquet 파일들의 묶음을 하나의 파티션으로, 그 상위 디렉터리 전체를 하나의 테이블로 간주했습니다. 메타스토어(예: Glue Data Catalog)는 “이 디렉터리가 이런 스키마의 테이블”이라는 정의와 파티션 목록만 들고 있었습니다.
이 모델은 단순하지만 여러 한계가 있습니다.
| 문제 | 내용 |
|---|---|
| 디렉터리 나열 비용 | 어떤 파일을 읽을지 알려면 S3 prefix를 LIST 해야 한다. 파일이 수십만 개면 나열 자체가 느리고 비싸다. |
| 원자성 부재 | 여러 파일을 동시에 바꾸는 작업 중간에 쿼리가 끼어들면, 일부만 반영된 상태를 읽을 수 있다. 트랜잭션 경계가 없다. |
| 스키마 변경의 고통 | 컬럼 이름/순서를 바꾸면 기존 파일과 어긋난다. 위치(ordinal) 기반으로 읽는 포맷에서는 컬럼이 밀려 깨지기 쉽다. |
| 파티션 변경의 고통 | 파티션 키를 바꾸려면 디렉터리 레이아웃을 다시 만들어야 하고, 보통 전체 데이터를 재적재해야 한다. |
핵심은 “디렉터리에 무엇이 들어 있는지”를 매번 스토리지에 물어봐야 한다는 점입니다. 테이블의 상태가 파일 시스템 레이아웃에 암묵적으로 흩어져 있으니, 일관성과 변경 관리가 어렵습니다.
1.2. Iceberg의 접근 - 파일을 추적한다
Apache Iceberg는 이 문제를 정반대로 풉니다. 디렉터리를 스캔하는 대신, 테이블에 속한 데이터 파일 목록을 메타데이터로 직접 관리합니다.
This table format tracks individual data files in a table instead of directories.
“이 테이블은 정확히 이 파일들로 이루어져 있다”를 메타데이터가 명시적으로 들고 있으므로, 쿼리 엔진은 테이블 스캔을 계획할 때 디렉터리 구조가 아니라 메타데이터를 기준으로 파일을 선택합니다. 카탈로그는 현재 metadata file의 위치를 제공하고, 이후의 파일 선택은 manifest의 통계와 필터 조건을 사용합니다. 그 구조를 다음 장에서 봅니다.
2. Iceberg의 메타데이터 계층
Iceberg의 모든 능력은 메타데이터 구조에서 나옵니다. 메타데이터는 네 단계로 쌓입니다.
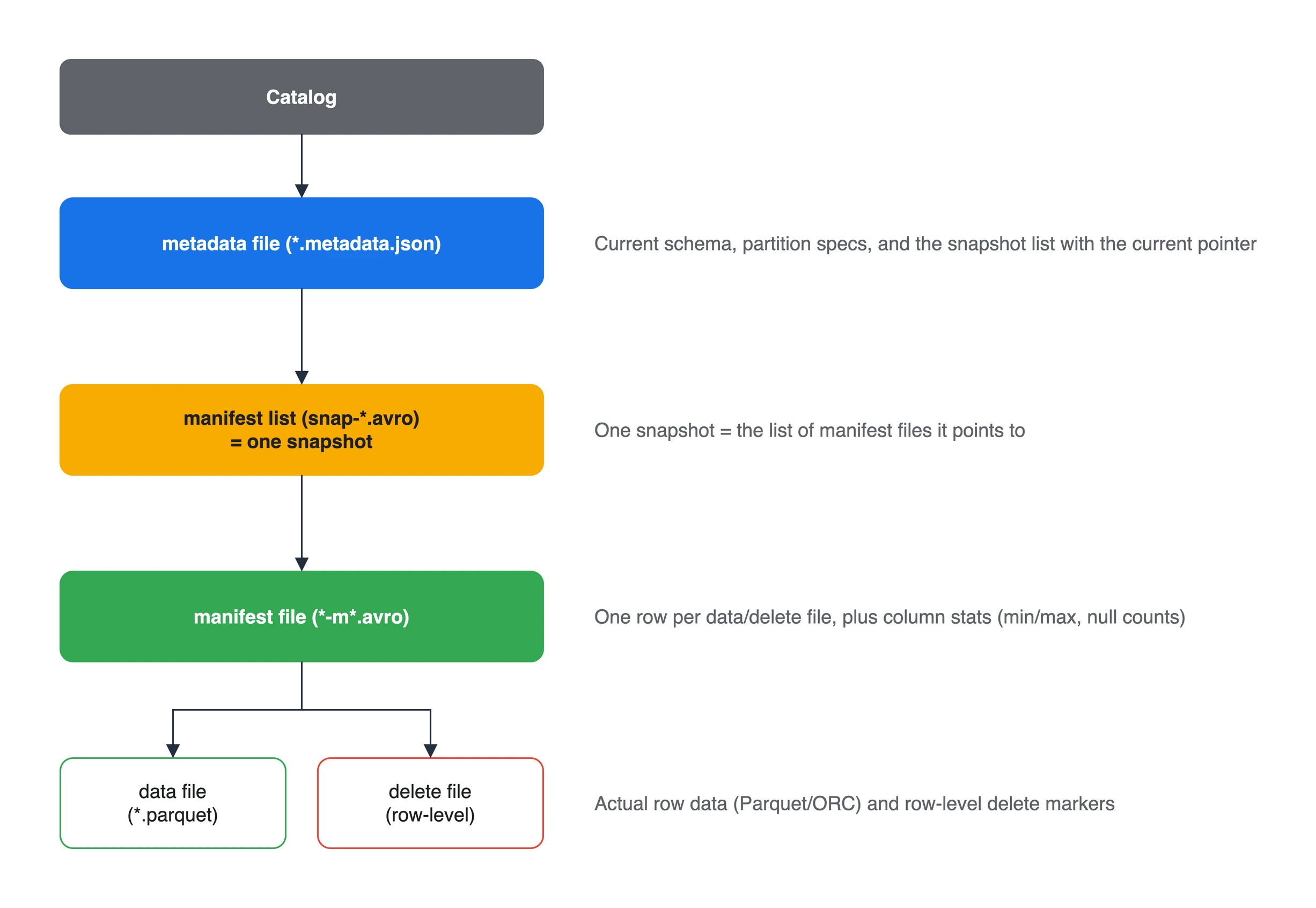
실제 스토리지에 펼쳐 보면 대략 다음과 같은 모습입니다.
1
2
3
4
5
6
7
8
9
10
s3://warehouse/sales_db/orders/
├─ metadata/
│ ├─ v3.metadata.json # metadata file: 스키마, 파티션 스펙, 스냅샷 목록
│ ├─ snap-8273...-1.avro # manifest list: 한 스냅샷이 가리키는 매니페스트 목록
│ ├─ 7f9a...-m0.avro # manifest file: 데이터/삭제 파일 목록 + 통계
│ └─ ...
└─ data/
├─ 00000-0-...parquet # data file
├─ 00001-0-...parquet
└─ ...
2.1. metadata file - 테이블의 최상위 상태
*.metadata.json은 테이블의 현재 상태를 담는 최상위 파일입니다. 현재 스키마, 파티션 스펙(들), 정렬 순서, 그리고 스냅샷 목록과 현재 스냅샷 포인터를 가지고 있습니다. 테이블에 변경이 생기면 기존 파일을 수정하지 않고 새 metadata file을 만든 뒤 카탈로그가 가리키는 위치를 교체합니다.
All changes to table state create a new metadata file and replace the old metadata with an atomic swap.
이 “atomic swap”은 완결된 테이블 상태를 가리키게 하는 출발점입니다(3장에서 다시 다룹니다).
2.2. manifest list - 하나의 snapshot
특정 시점의 테이블 상태가 곧 snapshot이고, 그 snapshot이 가리키는 매니페스트들의 목록이 manifest list(snap-*.avro)입니다.
The manifests that make up a snapshot are stored in a manifest list file.
manifest list에는 각 manifest file의 경로뿐 아니라, 그 매니페스트가 다루는 파티션 값의 범위 같은 요약 정보가 들어 있습니다. 덕분에 쿼리 엔진은 파티션 필터에 맞지 않는 매니페스트를 통째로 건너뛸 수 있습니다(첫 단계 가지치기).
2.3. manifest file - 데이터 파일의 인덱스
manifest file(*-m*.avro)은 실제 데이터/삭제 파일을 한 줄씩 추적합니다.
Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table.
각 행에는 파일 경로, 레코드 수, 파일 크기뿐 아니라 필드별 메트릭(값 범위, null 수 등)이 포함될 수 있습니다. 엔진은 이 메트릭과 쿼리 필터를 사용해 읽을 필요가 없는 파일을 제외할 수 있습니다. 어떤 통계를 기록하고 어떻게 가지치기하는지는 파일 포맷, writer, 엔진 구현에 따라 달라집니다.
2.4. data file - 실제 데이터
가장 아래는 실제 데이터가 담긴 data file(보통 Parquet, ORC, Avro)입니다. Iceberg는 파일 포맷 자체를 새로 만든 것이 아니라, 기존 컬럼 포맷 위에 “어떤 파일이 테이블에 속하는가”라는 메타데이터 계층을 얹은 것입니다. 행 단위 삭제에 쓰는 delete file은 Iceberg format version 2에서 정의되며, 사용하는 catalog와 engine이 해당 기능을 지원하는지도 확인해야 합니다.
| 계층 | 파일 | 역할 |
|---|---|---|
| metadata file | *.metadata.json | 스키마/파티션 스펙/스냅샷 목록, 현재 포인터 |
| manifest list | snap-*.avro | 하나의 snapshot = 매니페스트 목록 |
| manifest file | *-m*.avro | 데이터/삭제 파일 목록 + 컬럼 통계 |
| data file | *.parquet | 실제 행 데이터 |
2.5. 읽기와 쓰기는 어디서 만나는가
Iceberg table의 catalog는 현재 metadata file location을 제공하고, reader는 그 metadata file부터 manifest list, manifest file 순서로 내려가 필요한 data file만 고릅니다. 이 과정에서 catalog는 단순 파일 목록이 아니라 table의 현재 상태를 가리키는 동시성 경계가 됩니다.
writer는 새 data 또는 delete file과 manifest를 먼저 작성한 뒤, 자신이 읽었던 metadata version을 기준으로 catalog commit을 시도합니다. commit이 충돌하면 새 current metadata를 읽고 작업별 validation을 다시 수행해야 합니다. 따라서 객체 스토리지에 원자적 rename이 있다는 가정이 아니라 catalog가 제공하는 atomic pointer update 또는 locking 방식이 Iceberg commit의 핵심입니다.
3. Snapshot과 ACID
3.1. snapshot과 sequence number
snapshot은 특정 시점의 테이블 전체 상태입니다.
A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
커밋이 일어날 때마다 새 snapshot이 생기고, Iceberg는 매 커밋에 sequence number를 부여합니다. 이 번호가 데이터 파일과 삭제 파일의 상대적 나이를 정합니다.
The relative age of data and delete files relies on a sequence number that is assigned to every successful commit.
sequence number는 7장의 Merge-on-Read에서 중요해집니다. “어떤 삭제 파일이 어떤 데이터 파일에 적용되는가”를 이 번호의 선후 관계로 판단하기 때문입니다.
3.2. atomic commit과 optimistic concurrency
Iceberg의 커밋은 결국 metadata file 포인터를 새 버전으로 바꾸는 단 한 번의 원자적 연산으로 수렴합니다. 쓰기 작업은 새 데이터 파일과 매니페스트를 먼저 만들어 두고, 마지막에 “현재 메타데이터 버전이 내가 시작할 때 본 그 버전이 맞으면 새 버전으로 교체”를 시도합니다.
Writers create table metadata files optimistically, assuming that the current version will not be changed before the writer’s commit.
이것이 optimistic concurrency(낙관적 동시성 제어) 입니다. 두 writer가 동시에 커밋을 시도하면, 먼저 성공한 쪽이 포인터를 바꾸고, 나중 쪽은 자신이 기준으로 삼은 버전이 바뀌었음을 감지합니다. 재시도가 가능한 작업은 최신 상태에서 변경을 다시 검증한 뒤 커밋합니다. 독자는 메타데이터를 읽은 시점의 snapshot을 사용하다가 새 metadata location을 읽을 때 새 상태를 봅니다. Iceberg 명세는 원자적 교체를 직렬화 격리의 기반으로 설명하지만, 실제 쓰기 작업의 격리 보장은 작업별 검증 조건과 카탈로그 구현을 함께 확인해야 합니다.
4. Time travel과 rollback
snapshot이 메타데이터에 남아 있으므로, 과거 시점을 그대로 조회할 수 있습니다. 이것이 time travel입니다. 엔진별 SQL은 조금씩 다르지만 개념은 동일합니다.
1
2
3
4
5
-- 특정 시각 기준 조회 (Athena/Trino)
SELECT * FROM sales_db.orders FOR TIMESTAMP AS OF TIMESTAMP '2026-05-01 00:00:00';
-- 특정 snapshot id 기준 조회 (Athena/Trino)
SELECT * FROM sales_db.orders FOR VERSION AS OF 8273419283742;
과거를 읽는 데 그치지 않고, 지원하는 엔진과 카탈로그에서는 테이블을 과거 snapshot으로 되돌리는(rollback) procedure도 제공합니다. 이는 새 데이터 파일을 다시 쓰는 복구와 다르며, 기존 snapshot을 현재 상태로 커밋하는 방식입니다. 실제 지원 SQL과 권한은 엔진별로 확인해야 합니다.
1
2
-- 잘못된 커밋 이전 snapshot으로 롤백 (Spark 예시)
CALL spark_catalog.system.rollback_to_snapshot('sales_db.orders', 8273419283742);
단, time travel은 보관 중인 snapshot에 한해서 가능합니다. 8장에서 다룰 snapshot 만료(expire)로 오래된 snapshot을 정리하면 그 시점으로는 더 이상 돌아갈 수 없습니다.
5. Schema evolution - field id의 힘
Iceberg에서 스키마 변경(컬럼 추가/삭제/이름 변경/순서 변경)이 안전한 이유는 컬럼을 이름이 아니라 고유한 field id로 추적하기 때문입니다.
Columns in Iceberg data files are selected by field id.
컬럼 이름을 바꿔도 내부 id는 그대로 유지됩니다.
Renaming an existing field must change the name, but not the field ID.
이름이 아니라 id로 데이터를 찾으므로, 허용되는 이름 변경이나 순서 변경은 기존 데이터 파일을 다시 쓰지 않고 처리할 수 있습니다. 컬럼을 추가하면 과거 파일에는 그 id가 없으므로 NULL로 읽히고, 컬럼을 삭제하면 그 id를 더 이상 읽지 않습니다. 단, 타입 변경은 Iceberg가 허용하는 안전한 승격 범위와 사용하는 엔진의 지원 여부를 확인해야 합니다.
1
2
3
4
-- 모두 메타데이터 변경만으로 끝난다 (데이터 재작성 없음)
ALTER TABLE sales_db.orders ADD COLUMN coupon_id bigint;
ALTER TABLE sales_db.orders RENAME COLUMN amount TO gross_amount;
ALTER TABLE sales_db.orders DROP COLUMN legacy_flag;
Hive 방식에서 컬럼을 위치(ordinal)로 읽는 포맷은, 가운데 컬럼을 추가/삭제하면 이후 컬럼이 한 칸씩 밀려 값이 어긋날 수 있습니다. field id 기반 추적이 이 문제를 원천적으로 없앱니다.
6. Partition evolution과 hidden partitioning
6.1. hidden partitioning
Hive 방식에서는 파티션 컬럼을 별도로 만들어 채워 넣고(dt='2026-04-14'), 쿼리도 그 파티션 컬럼을 직접 걸어야 했습니다. 즉 물리적 디렉터리 레이아웃을 쿼리 작성자가 알고 있어야 합니다.
Iceberg는 hidden partitioning으로 이 결합을 끊습니다. 원본 컬럼에 partition transform(예: month(sale_date), day(ts), bucket(16, id))을 선언해 두면, 파티션 값을 테이블이 자동으로 계산하고 추적합니다. 쿼리는 파티션 컬럼을 따로 알 필요 없이 원본 컬럼으로 필터링하면 됩니다.
1
2
3
4
5
6
7
8
9
10
CREATE TABLE sales_db.daily_sales (
sale_date date,
category string,
sales_amount double
)
USING iceberg
PARTITIONED BY (month(sale_date));
-- 파티션 키를 따로 알 필요 없이 원본 컬럼으로 필터링
SELECT * FROM sales_db.daily_sales WHERE sale_date = DATE '2026-04-14';
5편에서 다룰 일반 Glue 테이블의 partition projection은 “키를 미리 정의하고 쿼리가 그 키를 직접 거는” 모델입니다. hidden partitioning은 “원본 컬럼에 transform을 걸어두면 파티션 컬럼을 따로 관리하거나 물리 레이아웃을 알 필요가 없는” 모델로, 결합 방향이 반대입니다.
6.2. partition evolution
더 나아가, Iceberg는 파티션 스킴 자체를 바꾸는 것(partition evolution) 을 지원합니다. 기존 파일은 기존 스펙과 함께 남고 새 파일에 새 스펙을 적용하므로, 단순히 스펙을 바꾸는 과정에서 기존 데이터를 재작성할 필요는 없습니다.
Table partitioning can be evolved by adding, removing, renaming, or reordering partition spec fields.
파티션 스펙을 바꾸면 새 spec id가 부여되고, 테이블은 여러 파티션 스펙을 동시에 들고 있게 됩니다.
Changing a partition spec produces a new spec identified by a unique spec ID that is added to the table’s list of partition specs.
비결은 매니페스트가 파티션 스펙 단위로 파일을 보관한다는 점입니다.
A manifest stores files for a single partition spec. When a table’s partition spec changes, old files remain in the older manifest and newer files are written to a new manifest.
즉 예전 파티션 스킴으로 쌓인 데이터는 옛 매니페스트에 그대로 두고, 새 데이터만 새 스킴으로 쌓습니다. 한 테이블 안에 일(day) 단위 파티션과 월(month) 단위 파티션이 시기별로 공존할 수 있고, 쿼리 엔진은 각 파일이 어느 스펙에 속하는지 알기에 둘을 함께 가지치기합니다. evolution은 기존 파일 재작성을 피하지만, 새 spec이 실제 query filter에서 충분히 가지치기되는지는 workload와 engine의 planning 결과로 검증해야 합니다.
1
2
3
-- 일 단위에서 월 단위로 파티션 스킴 변경 (과거 데이터 재작성 없음)
ALTER TABLE sales_db.daily_sales ADD PARTITION FIELD month(sale_date);
ALTER TABLE sales_db.daily_sales DROP PARTITION FIELD day(sale_date);
7. Copy-on-Write vs Merge-on-Read
행 단위 수정/삭제(UPDATE, DELETE, MERGE)는 데이터 파일을 다시 쓰는 방식과 delete file을 추가하는 방식으로 설명할 수 있습니다. Iceberg의 write mode 설정과 기본값, 지원 범위는 엔진과 테이블 포맷 버전에 따라 달라지므로, 사용하는 엔진 문서에서 확인해야 합니다.
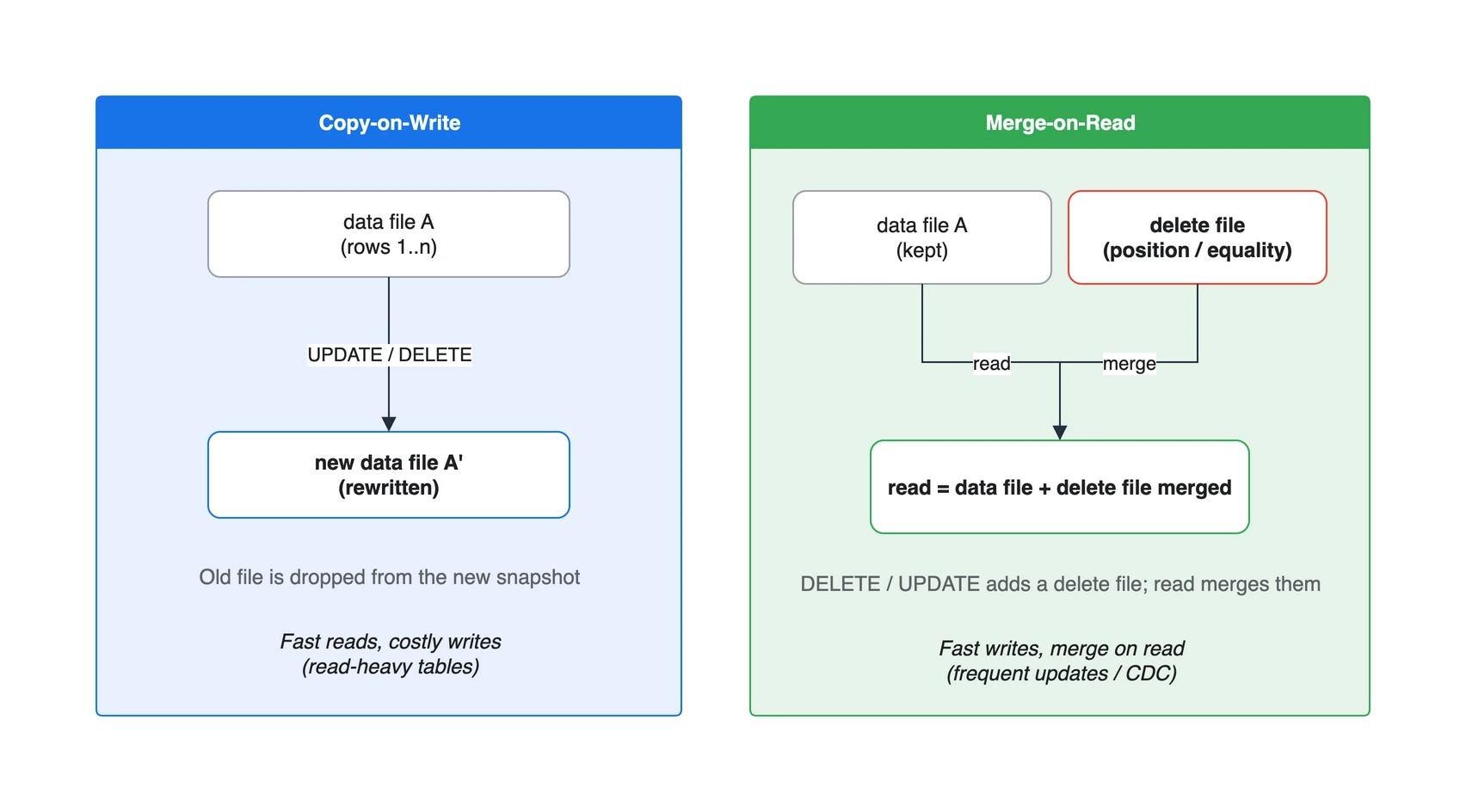
7.1. Copy-on-Write (CoW)
수정/삭제 대상 행이 포함된 데이터 파일을 통째로 다시 씁니다. 변경된 행을 반영한 새 파일을 만들고, 옛 파일은 새 snapshot에서 빠집니다. 읽을 때는 추가 병합이 없어 조회가 빠르지만, 한 행만 바꿔도 파일 전체를 재작성하므로 쓰기 비용이 큽니다. 수정이 드물고 조회가 잦은 테이블에 맞습니다.
7.2. Merge-on-Read (MoR)
원본 데이터 파일은 그대로 두고, “이 행은 삭제됨”이라는 정보를 delete file로 따로 기록합니다. 쓰기는 가볍지만, 읽을 때 데이터 파일과 delete file을 병합해야 하므로 조회에 비용이 듭니다. 잦은 수정/삭제(예: CDC, upsert)에 맞습니다. delete file은 두 종류입니다.
Position deletes: Mark a row deleted by data file path and the row position in the data file.
Equality deletes: Mark a row deleted by one or more column values, like id = 5.
position delete는 “어느 파일의 몇 번째 행”을 콕 집어 삭제하고, equality delete는 “id = 5인 행”처럼 조건으로 삭제합니다. 어느 delete file이 어느 data file에 적용되는지는 3장의 sequence number 선후로 정해집니다. MoR의 delete file은 쌓일수록 읽기 비용을 키우므로, 다음 장의 compaction으로 주기적으로 정리해 줘야 합니다.
| 항목 | Copy-on-Write | Merge-on-Read |
|---|---|---|
| 쓰기 방식 | 대상 데이터 파일 재작성 | delete file 추가 |
| 쓰기 비용 | 높음 | 낮음 |
| 읽기 비용 | 낮음 | 병합 필요(높음) |
| 적합 워크로드 | 읽기 위주, 드문 수정 | 잦은 수정/삭제, CDC |
8. 유지보수 - compaction, expire snapshots, orphan files
Iceberg는 변경할 때마다 새 파일을 만드는 구조라, 그대로 두면 작은 파일과 오래된 snapshot이 누적됩니다. 그래서 주기적인 유지보수가 필요합니다.
Compaction(작은 파일 병합) 은 작은 데이터 파일과 delete file을 더 적절한 파일로 다시 써 메타데이터와 파일 열기 비용을 줄이는 작업입니다.
This will combine small files into larger files to reduce metadata overhead and runtime file open cost.
Expire snapshots(스냅샷 만료) 는 오래된 snapshot을 메타데이터에서 제거합니다. 만료된 snapshot만 참조하던 파일은 엔진의 유지보수 작업과 보존 정책에 따라 삭제 대상이 될 수 있습니다.
Regularly expiring snapshots is recommended to delete data files that are no longer needed.
다만 만료된 snapshot으로는 더 이상 time travel을 할 수 없습니다.
Expiring old snapshots removes them from metadata, so they are no longer available for time travel queries.
Remove orphan files(고아 파일 정리) 는 어떤 현재 메타데이터도 참조하지 않는 파일을 청소합니다. 작업 실패 등으로 남은 잔여물이 대상이지만, 실행 시점과 보존 기간을 잘못 잡으면 진행 중인 작업의 파일을 대상으로 삼을 위험이 있으므로 엔진 권장 보존 기간을 따라야 합니다.
task or job failures can leave files that are not referenced by table metadata.
Spark 같은 엔진에서는 이를 procedure로 직접 실행합니다.
1
2
3
4
5
6
7
8
9
10
11
-- 작은 파일 병합
CALL spark_catalog.system.rewrite_data_files(table => 'sales_db.orders');
-- 7일 이전 snapshot 만료
CALL spark_catalog.system.expire_snapshots(
table => 'sales_db.orders',
older_than => TIMESTAMP '2026-05-12 00:00:00'
);
-- 고아 파일 정리
CALL spark_catalog.system.remove_orphan_files(table => 'sales_db.orders');
바로 이 유지보수를 사용자가 직접 스케줄링하지 않도록 대신 처리하는 것이 다음 편의 Amazon S3 Tables입니다. table bucket은 compaction과 snapshot 관리를 관리형으로 수행합니다.
9. 다른 테이블 포맷 - Delta Lake, Hudi
Iceberg와 같은 문제(객체 스토리지 위의 ACID 테이블)를 푸는 오픈 테이블 포맷이 더 있습니다. 셋 다 ACID, time travel, schema evolution을 제공한다는 공통점이 있고, 메타데이터를 기록하는 방식과 강점이 다릅니다.
| 항목 | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| 메타데이터 | metadata file + manifest 계층 | 트랜잭션 로그(_delta_log) | timeline + 인덱스 |
| 수정 모델 | 데이터 파일 재작성 또는 delete file 기반 | 구현과 테이블 기능에 따라 다름 | 구현과 테이블 기능에 따라 다름 |
| 강점 | 엔진 중립성, partition evolution | Spark/Databricks 생태계 밀착 | upsert/CDC, 레코드 인덱싱 |
어느 하나가 절대적으로 우월하다기보다, 사용하는 엔진 생태계와 워크로드(분석 위주 vs 잦은 upsert)에 따라 선택이 갈립니다. AWS 분석 스택은 그중 Iceberg를 1급으로 채택해 Athena, Glue, S3 Tables가 모두 Iceberg를 지원합니다.
세 포맷의 상호 운용을 노리는 Apache XTable 같은 프로젝트도 있지만, 이 글의 범위를 벗어나므로 다루지 않습니다.
10. 엔진 생태계와 AWS
Iceberg가 특정 벤더에 묶이지 않는다는 점은, 하나의 테이블을 여러 엔진이 함께 읽고 쓸 수 있다는 뜻입니다. Spark, Trino, Flink가 같은 Iceberg 테이블을 공유하고, AWS에서는 Athena(쿼리), Glue(카탈로그/ETL), EMR(Spark/Flink)이 같은 테이블을 바라봅니다. 메타데이터 표준이 공유되므로, 적재는 Flink로 하고 분석은 Athena로 하는 식의 조합이 자연스럽습니다. 다만 format version, catalog implementation, write isolation, row-level operation 지원 범위가 다르면 같은 table이라도 모든 작업이 호환되는 것은 아닙니다.
다만 메타데이터 파일이 어디에 있는지 알려 주는 카탈로그가 필요합니다. AWS에서 이 역할을 하는 것이 Glue Data Catalog이고, Iceberg 테이블을 관리형으로 통째로 제공하는 것이 다음 편의 Amazon S3 Tables입니다. S3 Tables는 이 글에서 본 메타데이터 계층과 compaction/snapshot 관리를 AWS가 대신 운영해 주는 형태로 이해하면 됩니다.
11. 정리와 다음 글
이번 편에서는 Apache Iceberg 테이블 포맷 자체를 메타데이터 계층, snapshot 기반 ACID, time travel, 스키마/파티션 진화, Copy-on-Write/Merge-on-Read, 유지보수 순으로 정리했습니다.
다음 글에서는 이 Iceberg를 AWS가 관리형으로 감싼 Amazon S3 Tables & Catalog Federation을 다룹니다. table bucket이 무엇이고, 이 글에서 본 compaction/snapshot 관리를 어떻게 대신 처리하는지, 그리고 Glue Data Catalog 안에 s3tablescatalog로 어떻게 중첩되어 ARN이 깊어지는지를 이어서 풀어갑니다.
12. Reference
- Apache Iceberg - Open Table Spec
- Apache Iceberg - Schemas
- Apache Iceberg - Evolution
- Apache Iceberg - Maintenance
- Apache Iceberg - Spark Queries and Procedures
- AWS Docs - Using Apache Iceberg tables in Athena
- Delta Lake - Documentation
- Apache Hudi - Documentation
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi