Multiple Pods Evicted 문제 Trouble Shooting

쿠버네티스 환경에서 이미지를 변환해주는 웹 사이트 https://image-converter.kkamji.net 를 로컬 클러스터에서 운영하던 도중 여러 Pod가 동시에 Evicted 되는 문제가 발생했습니다. 이번 포스팅에서는 당시 상황과 원인을 분석하고 해결 방법과 재발 방지 방법에 대해 알아보겠습니다.
1. 상황
GitHub Actions과 ArgoCD를 이용해 자동으로 CI/CD 배포 환경을 구성하고 있습니다. 코드가 배포되면 ArgoCD가 자동으로 배포 작업을 수행하며, Slack을 통해 알람을 받는 구조로 운영 중입니다.
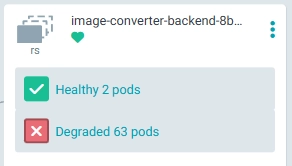
그런데 특정 배포 직후부터 약 3분 간격으로 ArgoCD가 Sync 되었다는 알람을 반복적으로 받았습니다. ArgoCD 대시보드에서 확인해보니 무려 63개의 Pod가 Degraded 상태였고, kubectl 명령어로 상세 조회해보니 Pod들이 Evicted 상태이며 일부는 ContainerStatusUnknown으로 나타났습니다.
1.1. ArgoCD Slack Alarms
1.2. ArgoCD Degraded Pods
1.3. Evicted Pods
1
2
3
4
5
6
7
8
9
10
❯ kubectl get pod -n image-converter
image-converter-frontend-845799b798-qbz67 1/1 Running 0 143m
image-converter-backend-8bc77f4c4-kc65d 1/1 Running 0 143m
image-converter-backend-8bc77f4c4-sf456 0/1 ContainerStatusUnknown 1 143m
image-converter-backend-8bc77f4c4-n7prp 0/1 Evicted 0 143m
image-converter-backend-8bc77f4c4-n98jj 0/1 Evicted 0 143m
image-converter-backend-8bc77f4c4-nm55k 0/1 Evicted 0 143m
image-converter-backend-8bc77f4c4-swwhm 0/1 Evicted 0 143m
...
...
2. 원인 분석
PV를 사용하는 Pod의 디스크 사용량 증가에 따른 노드 디스크 부족
2.1. Describe Pod
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
❯ kubectl describe pod -n image-converter image-converter-backend-8bc77f4c4-swwhm
Name: image-converter-backend-8bc77f4c4-swwhm
Namespace: image-converter
Priority: 0
Service Account: default
Node: k8s-w2/
Start Time: Wed, 18 Jun 2025 06:16:54 +0900
Labels: app.kubernetes.io/component=backend
app.kubernetes.io/instance=image-converter
app.kubernetes.io/name=image-converter
pod-template-hash=8bc77f4c4
Annotations: kubectl.kubernetes.io/restartedAt: 2025-06-17T21:10:40+09:00
Status: Failed
Reason: Evicted
Message: Pod was rejected: The node had condition: [DiskPressure].
...
...
Events: <none>
2.2. Describe Node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
❯ kubectl describe node k8s-w2
Name: k8s-w2.1849d7e4ed750a73
Namespace: default
Labels: <none>
Annotations: <none>
API Version: v1
Count: 17
Event Time: <nil>
First Timestamp: 2025-06-17T13:35:08Z
Involved Object:
Kind: Node
Name: k8s-w2
UID: k8s-w2
Kind: Event
Last Timestamp: 2025-06-18T00:40:15Z
Message: (combined from similar events): Failed to garbage collect required amount of images. Attempted to free 1295179776 bytes, but only found 240991912 bytes eligible to free.
Metadata:
Creation Timestamp: 2025-06-17T23:55:14Z
Resource Version: 43163292
UID: 8b5756bf-1804-4a09-a5c6-9c5492f82c6d
Reason: FreeDiskSpaceFailed
Reporting Component:
Reporting Instance:
Source:
Component: kubelet
Host: k8s-w2
Type: Warning
Events: <none>
2.3. Node Disk Usage 확인
1
2
3
4
5
6
7
❯ ansible k8s_nodes -m shell -a "df -h | grep lv"
k8s-m1 | CHANGED | rc=0 >>
/dev/mapper/ubuntu--vg-ubuntu--lv 27G 14G 12G 54% /
k8s-w2 | CHANGED | rc=0 >>
/dev/mapper/ubuntu--vg-ubuntu--lv 27G 22G 4.3G 84% /
k8s-w1 | CHANGED | rc=0 >>
/dev/mapper/ubuntu--vg-ubuntu--lv 27G 19G 6.8G 74% /
2.4. Kubelet 로그 확인
1
2
3
4
5
6
7
8
9
10
Jun 18 00:00:14 k8s-w2 kubelet[391617]: I0618 00:00:14.229011 391617 image_gc_manager.go:383] "Disk usage on image filesystem is over the high threshold, trying to free bytes down to the low threshold" usage=85 highThreshold=85 amountToFree=1290842112 lowThreshold=80
Jun 18 00:00:14 k8s-w2 kubelet[391617]: E0618 00:00:14.229086 391617 kubelet.go:1551] "Image garbage collection failed multiple times in a row" err="Failed to garbage collect required amount of images. Attempted to free 1290842112 bytes, but only found 0 bytes eligible to free."
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.157478 391617 kubelet.go:2484] "SyncLoop DELETE" source="api" pods=["image-converter/image-converter-backend-8bc77f4c4-v8w7m"]
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.157720 391617 kuberuntime_container.go:809] "Killing container with a grace period" pod="image-converter/image-converter-backend-8bc77f4c4-v8w7m" podUID="1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435" containerName="backend" containerID="containerd://c6a5c9ea95e7674f67a4cccab573f533ac148039033b3b845a32607fb305b363" gracePeriod=30
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.680540 391617 util.go:48] "No ready sandbox for pod can be found. Need to start a new one" pod="image-converter/image-converter-backend-8bc77f4c4-v8w7m"
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.682934 391617 reconciler_common.go:162] "operationExecutor.UnmountVolume started for volume \"kube-api-access-4rpzn\" (UniqueName: \"kubernetes.io/projected/1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435-kube-api-access-4rpzn\") pod \"1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435\" (UID: \"1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435\") "
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.685055 391617 operation_generator.go:780] UnmountVolume.TearDown succeeded for volume "kubernetes.io/projected/1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435-kube-api-access-4rpzn" (OuterVolumeSpecName: "kube-api-access-4rpzn") pod "1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435" (UID: "1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435"). InnerVolumeSpecName "kube-api-access-4rpzn". PluginName "kubernetes.io/projected", VolumeGIDValue ""
Jun 18 00:01:36 k8s-w2 kubelet[391617]: I0618 00:01:36.783654 391617 reconciler_common.go:299] "Volume detached for volume \"kube-api-access-4rpzn\" (UniqueName: \"kubernetes.io/projected/1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435-kube-api-access-4rpzn\") on node \"k8s-w2\" DevicePath \"\""
Jun 18 00:01:37 k8s-w2 kubelet[391617]: I0618 00:01:37.088931 391617 generic.go:358] "Generic (PLEG): container finished" podID="1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435" containerID="c6a5c9ea95e7674f67a4cccab573f533ac148039033b3b845a32607fb305b363" exitCode=0
Jun 18 00:01:37 k8s-w2 kubelet[391617]: I0618 00:01:37.088970 391617 kubelet.go:2500] "SyncLoop (PLEG): event for pod" pod="image-converter/image-converter-backend-8bc77f4c4-v8w7m" event={"ID":"1e53a7ad-acc8-4bb3-b6b4-af1b06bfd435","Type":"ContainerDied","Data":"c6a5c9ea95e7674f67a4cccab573f533ac148039033b3b845a32607fb305b363"}
2.5. 디스크 사용량 확인 (리소스 확인)
1
2
3
4
5
6
7
8
9
10
11
❯ ncdu /
--- / --------------------------
9.2 GiB [########################################] /var
7.5 GiB [################################ ] /opt
5.8 GiB [######################### ] /run
2.6 GiB [########### ] /usr
2.0 GiB [######## ] swap.img
859.8 MiB [### ] /snap
194.3 MiB [ ] /boot
---
ncdu명령어를 사용해 확인한 결과 아래 3개의 디렉터리에서 디스크를 많이 사용하고 있었습니다.
/opt/local-path-provisioner (7.3 GiB)
- Persistent Volume 생성 및 로컬 데이터를 저장하는 공간
/run/containerd/io.containerd.runtime.v2.task/k8s.io (5.8 GiB)
- 실행 중인 컨테이너의 임시 작업 데이터 및 상태 정보 저장
/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs (4.5 GiB)
- 컨테이너 이미지의 스냅샷 및 레이어 정보 저장
3. 문제 발생 과정 정리
- 디스크 사용량이 highThreshold(85%) 초과 -> kubelet Garbage Collection 시도
Disk usage on image filesystem is over the high threshold, trying to free bytes down to the low threshold
- GC 대상 이미지 없음 -> DiskPressure 상태로 Pod Eviction
Failed to garbage collect required amount of images. Attempted to free 1290842112 bytes, but only found 0 bytes eligible to free.
- ReplicaSet 컨트롤러가 Evicted Pod 대체 생성 -> 디스크 사용 증가 -> 반복 Eviction
- ArgoCD Auto Sync가 Sync 상태 점검 -> 계속 OutOfSync 감지 후 재배포 시도
ArgoCD의 Auto Sync 기능이 이 반복적인 상황을 지속적으로 감지하여 계속 재배포를 시도하며 Sync 알람을 반복해서 전송
4. 해결 방법
4.1. 노드 디스크 용량 확장
- 디스크 볼륨 자체의 용량을 추가 확장하여 근본적인 문제를 해결
- VM(Virtual Machine)의 디스크 크기를 조정하거나 추가 디스크를 연결
4.2. 노드 디스크 정리 (containerd)
이미지 Garbage Collection을 수동으로 수행하여 사용하지 않는 이미지를 삭제
1
sudo crictl rmi --prune
4.3. Evicted 상태의 Pod 삭제
1
kubectl delete pods --field-selector=status.phase=Failed -n image-converter
5. 문제 재발 방지 방법
5.1. 모니터링 강화
- Prometheus와 Grafana를 활용하여 DiskPressure, Pod Eviction 현황을 실시간 모니터링하고 경고를 설정하여 미리 예방 조치
5.2. ephemeral-storage 리소스 설정
- ephemeral-storage는 Pod가 사용하는 임시 저장 공간으로, Pod 내에서 로그, 캐시, 임시 파일 등을 저장하는 데 사용
- Pod가 예상보다 많은 디스크를 사용하지 않도록 제한하고 관리하는 용도로 사용
1
2
3
4
5
resources:
requests:
ephemeral-storage: 200Mi
limits:
ephemeral-storage: 500Mi
5.3. 정기적인 디스크 관리
- 디스크 공간 점검 및 관리 스크립트를 사용해 주기적으로 이미지 정리 수행 (CronJob)
6. 마무리
디스크 공간 관리는 Kubernetes 운영의 기본이면서도 쉽게 놓칠 수 있는 부분입니다. 사소해 보이는 디스크 공간 부족도 서비스 장애로 이어질 수 있으니, 꾸준한 모니터링과 관리로 안정적인 클러스터 운영을 유지하시길 바랍니다.
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi