S3 Tables & Catalog Federation 알아보기 - 관리형 Iceberg 레이크하우스

앞선 Amazon Athena & Glue Data Catalog 글에서 일반 Glue 테이블(S3 + Glue Catalog)을 기준으로 쿼리 흐름과 권한을 정리하고, 이어 Apache Iceberg 테이블 포맷 글에서 Iceberg 자체의 구조와 동작 원리를 살펴봤습니다. 이번 글에서는 그 Iceberg를 AWS가 관리형으로 감싼 Amazon S3 Tables와, 그것이 Glue Data Catalog에 연결되는 방식인 Catalog Federation을 알아봅니다.
이 편을 이해하면, 같은 Athena 쿼리인데도 sales_db.orders처럼 평범해 보이는 테이블이 사실은 s3tablescatalog 아래 깊은 경로에 있고, 그래서 권한 ARN이 왜 길어지는지가 보입니다. 다음 편(Lake Formation)의 권한 이야기를 위한 토대이기도 합니다.
TL;DR
- S3 Tables는 관리형 Apache Iceberg 테이블 버킷입니다. compaction/스냅샷 관리를 AWS가 맡고, ACID/스키마 진화/시간여행을 제공합니다.
- S3 Tables를 Glue Data Catalog에 통합하면 기본 카탈로그(default) 안에
s3tablescatalog라는 federated 카탈로그가 생깁니다.- 매핑: table bucket -> catalog, namespace -> database, table -> table. 즉 카탈로그가 중첩됩니다.
- 그래서 Glue Data Catalog에서 본 카탈로그 경로는
catalog/s3tablescatalog/{bucket}처럼 일반 테이블보다 한 단계 깊어집니다.
1. Amazon S3 Tables - 관리형 Iceberg
1.1. 왜 Iceberg인가
1편에서 짚었듯이, 초기 데이터 레이크(S3 + Parquet 파일 더미)는 트랜잭션이 없고 부분 수정이 어렵습니다. Apache Iceberg는 S3 위에 테이블 포맷을 얹어 이 한계를 해결합니다. ACID 트랜잭션, 스키마 진화(컬럼 추가/삭제), 시간여행(과거 스냅샷 조회) 같은 기능을 파일 더미가 아닌 “진짜 테이블” 수준으로 제공합니다.
1.2. S3 Tables가 더하는 것
Iceberg를 직접 운영하려면 메타데이터 파일 관리, compaction(작은 파일 병합), 스냅샷 정리(garbage collection) 같은 유지보수를 직접 해야 합니다. Amazon S3 Tables는 이 유지보수를 관리형으로 처리하는 전용 스토리지(table bucket)입니다.
일반 S3 버킷과의 차이는 다음과 같습니다.
| 항목 | 일반 S3 버킷 | S3 Tables (table bucket) |
|---|---|---|
| 저장 단위 | 객체(파일) | 테이블(Iceberg) |
| 테이블 관리 | 직접(또는 Glue) | 관리형(compaction/스냅샷 자동) |
| 트랜잭션 | 없음 | ACID |
| 접근 | S3 객체 API | 테이블 API + 분석 엔진 |
table bucket 안에는 namespace(논리적 그룹)가 있고, 그 안에 table이 있습니다. 이 구조가 곧 Glue Catalog에 매핑되는 단위입니다.
S3 Tables의 실데이터는 관리형 스토리지에 보관됩니다. 일반 S3 객체 ARN으로 직접 다루는 모델이 아니라, 분석 엔진이 카탈로그를 통해 접근한다는 점이 일반 S3와 다릅니다.
1.2.1. 관리형 유지보수 - compaction과 snapshot 관리
S3 Tables의 “관리형”이 구체적으로 어떤 동작인지가 직접 Iceberg를 운영하는 것과의 핵심 차이입니다. table bucket의 모든 테이블에는 두 가지 유지보수가 기본 활성화되어 있습니다.
Compaction은 작은 객체 여러 개를 큰 객체 적은 수로 병합해 쿼리 성능을 높이고, 병합 과정에서 row-level delete의 효과도 함께 반영합니다. 기본 target 파일 크기는 512MB이며, 64MB에서 512MB 사이로 조정할 수 있습니다.
Compaction is enabled by default for all tables, with a default target file size of 512MB, or a custom value you specify between 64MB to 512MB. The compacted files are written as the most recent snapshot of your table.
Snapshot 관리는 테이블의 활성 스냅샷 개수를 MinimumSnapshots(기본 1)와 MaximumSnapshotAge(기본 120시간) 기준으로 만료/제거합니다. 스냅샷이 만료되면 그 스냅샷만 참조하던 객체는 noncurrent로 표시되고, unreferenced file removal 정책의 NoncurrentDays 일수가 지나면 삭제됩니다. 직접 Iceberg를 돌릴 때 손수 스케줄링해야 하는 OPTIMIZE/VACUUM을 S3 Tables가 대신 처리하는 셈입니다. 실제로 Athena는 S3 Tables에 대해 OPTIMIZE/VACUUM DDL을 지원하지 않으며, 이 작업은 S3의 관리형 maintenance에 맡깁니다.
You can manage compaction and snapshot management in S3.
두 동작 모두 테이블 단위로 PutTableMaintenanceConfiguration으로 끄거나 임계값을 바꿀 수 있지만, 기본값만으로도 별도 운영 없이 파일이 정리됩니다.
1.3. Iceberg가 주는 것 - 스키마 진화와 시간여행
Iceberg 테이블이라, 일반 파일 테이블에서는 까다롭던 작업이 SQL로 가능합니다.
1
2
3
4
5
-- 컬럼 추가(스키마 진화) - 기존 데이터를 다시 쓰지 않아도 된다
ALTER TABLE sales_db.orders ADD COLUMNS (coupon_id bigint);
-- 시간여행(time travel) - 과거 스냅샷 조회
SELECT * FROM sales_db.orders FOR TIMESTAMP AS OF (current_timestamp - interval '1' day);
스키마를 바꿔도 과거 데이터를 재적재할 필요가 없고, 특정 시점의 스냅샷을 그대로 조회할 수 있습니다. 이런 기능이 S3 Tables(관리형 Iceberg)를 단순한 파일 더미와 구분 짓는 지점입니다.
1.4. partition projection vs Iceberg hidden partitioning
1편에서 일반 Glue 테이블은 partition projection으로 파티션을 다뤘습니다. year/month/day/hour 같은 파티션 키를 테이블 properties에 미리 정의해 두고, 쿼리는 WHERE year='2026' AND month='04'처럼 그 키를 직접 걸어 스캔 범위를 좁히는 방식입니다. 즉 물리적 디렉터리 레이아웃(s3://.../year=2026/month=04/)을 쿼리 작성자가 알고 있어야 합니다.
Iceberg 테이블은 hidden partitioning으로 이 결합을 끊습니다. 파티션을 별도 컬럼으로 저장해 매번 채워 넣는 대신, 원본 컬럼에 partition transform(예: month(sale_date), day(ts), bucket(16, id))을 적용해 파티션 값을 테이블이 자동으로 만들어 냅니다. 테이블을 만들 때 transform을 선언하는 모습은 다음과 같습니다.
1
2
3
4
5
6
7
CREATE TABLE sales_db.daily_sales (
sale_date date,
product_category string,
sales_amount double
)
PARTITIONED BY (month(sale_date))
TBLPROPERTIES ('table_type' = 'iceberg');
쿼리는 파티션 키를 따로 알 필요 없이 원본 컬럼(sale_date)으로 필터링하면 되고, Iceberg가 transform을 통해 알아서 파티션을 건너뜁니다. Athena도 이 동작을 그대로 지원합니다.
Athena supports Iceberg’s hidden partitioning.
정리하면, partition projection은 “키를 미리 정의하고 쿼리가 그 키를 직접 건다”는 모델이고, hidden partitioning은 “원본 컬럼에 transform을 걸어두면 파티션 컬럼을 따로 관리하거나 물리 레이아웃을 알 필요가 없다”는 모델입니다. 파티션 스킴을 바꾸는 partition evolution도 기존 데이터를 다시 쓰지 않고 적용할 수 있다는 점이 일반 Glue 테이블과의 차이입니다.
2. Catalog Federation - default vs federated
2.1. 기본 카탈로그(default)
지금까지 다룬 일반 Glue 테이블은 기본 카탈로그(default Data Catalog) 에 있습니다. 이 카탈로그의 ID는 계정 ID이며, Athena에서는 AwsDataCatalog 라는 이름으로 보입니다. logs_db 같은 일반 데이터베이스가 여기에 직접 속합니다.
2.2. federated 카탈로그(s3tablescatalog)
S3 Tables를 Glue Data Catalog에 통합하면, 기본 카탈로그 안에 s3tablescatalog라는 federated 카탈로그가 만들어집니다. 이 통합은 Glue 서비스가 계정/리전 단위로 한 번 수행하며, 이후 같은 리전의 table bucket은 모두 자동으로 하위 카탈로그로 마운트됩니다. AWS 문서는 다음과 같이 설명합니다.
When you integrate the S3 tables catalog with the Data Catalog and Lake Formation, the AWS Glue service creates a single federated catalog called
s3tablescatalogin your account’s default Data Catalog specific to your AWS Region.
그리고 S3 Tables의 리소스가 다음과 같이 매핑됩니다.
- table bucket -> 카탈로그(multi-level)
- namespace -> 데이터베이스
- table -> 테이블
즉 카탈로그 안에 카탈로그가 들어가는 중첩 구조가 됩니다. 그림으로 보면 다음과 같습니다.
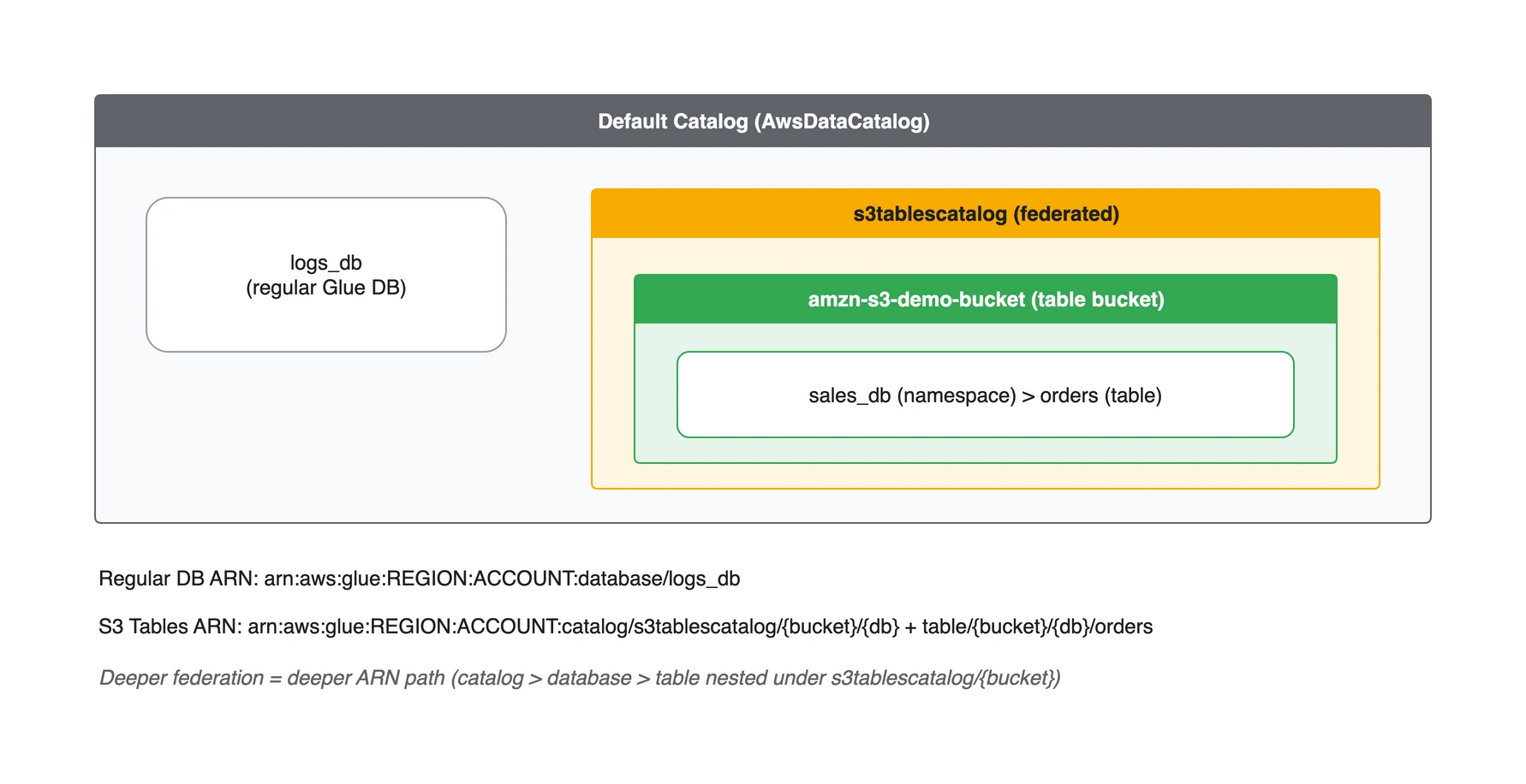
왼쪽의 logs_db는 기본 카탈로그에 직접 속한 일반 데이터베이스입니다. 오른쪽은 s3tablescatalog -> table bucket -> namespace -> table 순으로 중첩된 S3 Tables 경로입니다. 같은 “테이블”이지만 한쪽은 평면, 한쪽은 깊은 계층에 있습니다.
2.3. 통합은 어떻게 등록되나
이 federated 카탈로그는 table bucket을 만들 때 한 번 등록됩니다. 콘솔에서는 table bucket을 생성하면서 Enable integration 체크박스를 켜면 자동으로 처리됩니다.
When you enable the integration using the console, AWS creates a federated catalog named
s3tablescatalogthat automatically discovers and mounts all S3 table buckets in your AWS account and Region.
리전에서 처음 통합할 때 s3tablescatalog가 생기고, 그 뒤로는 같은 계정/리전의 table bucket이 모두 자식 카탈로그로 자동 마운트됩니다. CLI로 직접 만들 때는 glue create-catalog에 federated 연결을 지정합니다. aws:s3tables 커넥션과 table bucket ARN 패턴(arn:aws:s3tables:<region>:<account-id>:bucket/*)을 가리키는 것이 핵심입니다.
1
2
3
4
5
6
7
8
9
aws glue create-catalog \
--name "s3tablescatalog" \
--catalog-input '{
"Description": "Federated catalog for S3 Tables",
"FederatedCatalog": {
"Identifier": "arn:aws:s3tables:<region>:<account-id>:bucket/*",
"ConnectionName": "aws:s3tables"
}
}'
즉 s3tablescatalog는 일반 Glue 데이터베이스가 아니라 S3 Tables 쪽을 가리키는 federated 카탈로그이고, table bucket 하나하나가 그 아래 자식 카탈로그로 노출됩니다. 자식 카탈로그가 제대로 마운트됐는지는 aws glue get-catalogs --parent-catalog-id s3tablescatalog로 확인할 수 있습니다.
3. ARN이 깊어지는 이유
이 중첩이 실무에서 체감되는 지점이 바로 ARN입니다. 2편에서 본 일반 테이블 ARN과 비교해 봅니다.
1
2
3
4
5
6
7
8
9
10
11
12
# 일반 Glue 테이블 (default catalog)
arn:aws:glue:<region>:<account-id>:database/logs_db
arn:aws:glue:<region>:<account-id>:table/logs_db/app_events
# S3 Tables의 native 리소스 (s3tables 네임스페이스)
arn:aws:s3tables:<region>:<account-id>:bucket/{bucket}
arn:aws:s3tables:<region>:<account-id>:bucket/{bucket}/table/{table-id}
# Glue/Lake Formation에서 본 federated 카탈로그 (catalog 단계가 중첩)
arn:aws:glue:<region>:<account-id>:catalog/s3tablescatalog/{bucket}
# Lake Formation grant의 Catalog Id 표기
<account-id>:s3tablescatalog/{bucket}
두 가지를 구분하는 것이 중요합니다. 첫째, S3 Tables의 native ARN은 s3tables 네임스페이스를 쓰며 bucket/{bucket}, bucket/{bucket}/table/{table-id} 형태입니다. IAM 권한 참조에서 정의하는 native 리소스 ARN 템플릿은 다음과 같습니다.
arn:${Partition}:s3tables:${Region}:${Account}:bucket/${TableBucketName}
arn:${Partition}:s3tables:${Region}:${Account}:bucket/${TableBucketName}/table/${TableID}
테이블이 이름이 아니라 TableID로 식별된다는 점에 주의합니다. 둘째, 같은 데이터를 Glue Data Catalog에서 볼 때는 catalog 단계에 s3tablescatalog/{bucket}가 한 겹 더 들어가는 중첩 카탈로그가 됩니다. Lake Formation grant도 이 카탈로그 단위를 가리키며, grant의 Catalog.Id는 <account-id>:s3tablescatalog/{bucket} 형태입니다.
그래서 IAM 정책에서 S3 Tables 테이블에 권한을 줄 때는, 일반 테이블보다 카탈로그 레벨 ARN까지 함께 지정해야 합니다. 이 부분은 권한을 다루는 다음 편(Lake Formation)에서 더 구체적으로 이어집니다.
4. Athena에서 federated 테이블 쿼리
Athena에서 S3 Tables 테이블을 쿼리할 때는 카탈로그를 지정해야 합니다. 콘솔의 쿼리 에디터라면 Catalog 필드를 s3tablescatalog/{bucket} 형태로 선택하고, Database에 namespace를 지정합니다.
SQL에서 명시적으로 카탈로그를 적을 수도 있습니다. 일반 카탈로그와 federated 카탈로그를 함께 조인할 때 특히 유용합니다.
1
2
3
4
SELECT o.order_id, o.amount
FROM "s3tablescatalog/amzn-s3-demo-bucket".sales_db.orders o
WHERE o.dt = '2026-04-14'
LIMIT 100;
1
2
3
4
5
6
7
-- 일반 테이블(logs_db)과 S3 Tables(sales_db)를 함께 조인
SELECT e.user_id, sum(o.amount) AS spent
FROM logs_db.app_events e
JOIN "s3tablescatalog/amzn-s3-demo-bucket".sales_db.orders o
ON e.user_id = o.buyer_id
WHERE e.dt = '2026-04-14'
GROUP BY e.user_id;
logs_db는 기본 카탈로그라 짧은 이름으로, sales_db.orders는 federated 카탈로그라 "s3tablescatalog/{bucket}" 접두어로 참조합니다.
카탈로그가 Athena 데이터 소스로 인식되지 않으면
CATALOG_NOT_FOUND가 납니다. 이는 단순 오타일 수도, 권한 문제일 수도 있습니다. 권한 쪽 원인은 다음 편에서 자세히 다룹니다.
5. 실습 - S3 Tables 만들고 쿼리하기
S3 table bucket이 Glue Data Catalog에 통합돼 있다는 전제 아래, Athena에서 namespace와 테이블을 만들고 쿼리해 봅니다. 콘솔이라면 Catalog 필드를 s3tablescatalog/{bucket}로 선택한 뒤 아래를 실행합니다.
5.1. namespace와 테이블 생성
1
2
3
4
5
6
7
8
9
10
11
-- namespace(=database) 생성
CREATE DATABASE sales_db;
-- Iceberg 테이블 생성 (S3 Tables는 LOCATION을 지정하지 않는다 - 관리형)
CREATE TABLE sales_db.orders (
order_id bigint,
buyer_id bigint,
amount double,
dt date
)
TBLPROPERTIES ('table_type' = 'iceberg');
일반 외부 테이블과 달리 LOCATION을 적지 않습니다. S3 Tables가 스토리지 위치를 관리하기 때문입니다.
5.2. 데이터 적재와 조회
1
2
3
4
5
6
7
INSERT INTO sales_db.orders VALUES
(1, 1001, 12000.0, DATE '2026-04-14'),
(2, 1002, 8000.0, DATE '2026-04-14');
SELECT dt, count(*) AS cnt, sum(amount) AS revenue
FROM sales_db.orders
GROUP BY dt;
5.3. 방금 무슨 일이 일어났나
CREATE DATABASE/CREATE TABLE->s3tablescatalog아래 namespace/table이 만들어지고 Glue Catalog에 federated로 노출됩니다.LOCATION없음 -> S3 Tables가 관리하는 스토리지에 데이터가 저장됩니다.INSERT/SELECT-> Iceberg 테이블이라 트랜잭션과 스냅샷이 적용됩니다.- SQL 자체는 일반 Glue 테이블과 거의 같지만, 카탈로그 경로(federated)와 관리형 스토리지라는 점이 다릅니다.
6. 다음 글
이번 편에서는 S3 Tables가 무엇이고, Catalog Federation으로 기본 카탈로그 안에 어떻게 중첩되는지, 그래서 ARN이 왜 깊어지는지를 정리했습니다.
다음 글에서는 이 federated 데이터에 한 겹 더 얹히는 권한 계층, AWS Lake Formation을 다룹니다. S3 Tables 레이크하우스 데이터는 IAM만으로는 접근할 수 없고, Lake Formation의 grant가 함께 있어야 합니다. 왜 그런지, 어떻게 부여하는지를 이어서 풀어갑니다.
7. Reference
- AWS Documentation - Amazon S3 Tables (개요): https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables.html
- AWS Documentation - Maintenance for tables (compaction/snapshot 관리형 동작): https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-maintenance.html
- AWS Documentation - Enabling S3 Tables integration with the Data Catalog (federation 등록): https://docs.aws.amazon.com/glue/latest/dg/enable-s3-tables-catalog-integration.html
- AWS Documentation - Register S3 table bucket catalogs and query Tables from Athena: https://docs.aws.amazon.com/athena/latest/ug/gdc-register-s3-table-bucket-cat.html
- AWS Documentation - Amazon S3 Tables integration with AWS Glue Data Catalog and Lake Formation (s3tablescatalog 매핑): https://docs.aws.amazon.com/lake-formation/latest/dg/create-s3-tables-catalog.html
- AWS Documentation - Create Iceberg tables (partition transform/hidden partitioning): https://docs.aws.amazon.com/athena/latest/ug/querying-iceberg-creating-tables.html
- AWS Documentation - Actions, resources, and condition keys for Amazon S3 Tables (native ARN 템플릿): https://docs.aws.amazon.com/service-authorization/latest/reference/list_amazons3tables.html
- Apache Iceberg - Documentation: https://iceberg.apache.org/
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi