데이터 웨어하우스 vs 데이터 레이크 vs 레이크하우스

데이터 분석 스택을 다루다 보면 데이터 웨어하우스(Data Warehouse), 데이터 레이크(Data Lake), 레이크하우스(Data Lakehouse) 라는 용어가 자주 등장합니다. 셋 다 “데이터를 모아 분석한다”는 점은 같지만, 어디에 어떻게 저장하고 언제 스키마를 적용하느냐가 다릅니다. 이 차이를 모르면, 어떤 저장 방식을 택해야 하는지, 그리고 최근의 레이크하우스가 무엇을 해결하려는 것인지 감을 잡기 어렵습니다.
이번 글에서는 세 가지 데이터 저장 패러다임을 비교하고, 각각이 AWS에서 어떤 서비스로 구현되는지를 정리합니다. 이는 Athena, S3 Tables, Lake Formation 같은 구성요소를 이해하기 위한 토대이기도 합니다.
TL;DR
- Data Warehouse: 적재 전에 스키마를 강제(schema-on-write)하는 정형 데이터 분석 저장소. 빠른 쿼리와 거버넌스가 강점, 비용과 경직성이 약점입니다.
- Data Lake: 원본을 그대로 담고 읽을 때 스키마를 적용(schema-on-read)하는 저비용 유연 저장소. 거버넌스가 약해 관리 없이는 “데이터 늪”이 됩니다.
- Data Lakehouse: 레이크의 저장 방식 위에 웨어하우스의 기능(ACID/스키마/트랜잭션)을 테이블 포맷(Iceberg/Delta/Hudi)으로 얹은 결합형입니다.
- AWS 매핑: Warehouse=Redshift, Lake=S3+Glue+Athena, Lakehouse=S3 Tables+Athena+Lake Formation.
아래 그림이 세 패러다임의 핵심 차이와 AWS 매핑을 한눈에 보여 줍니다.
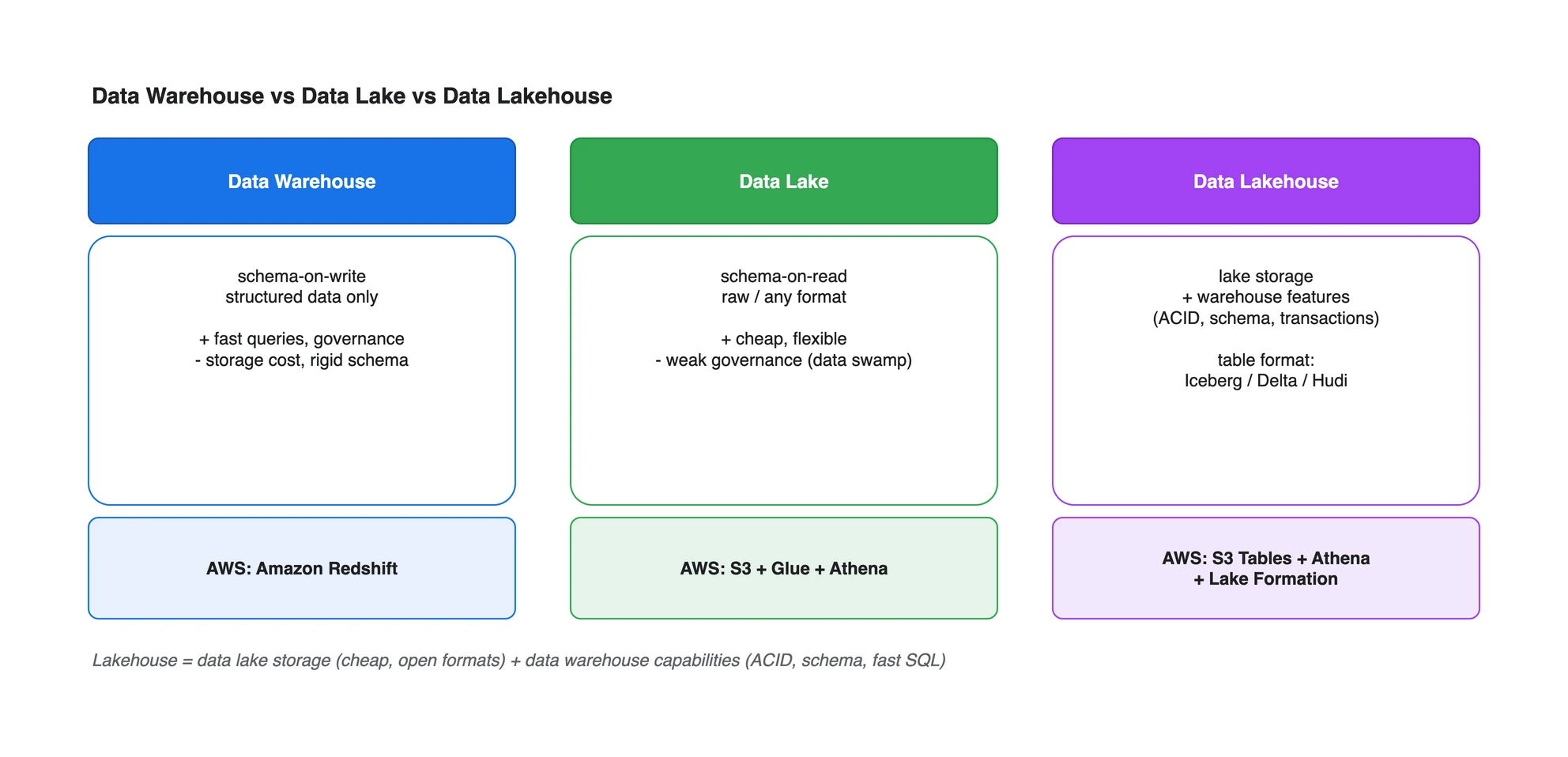 세 패러다임의 스키마 적용 시점(schema-on-write vs schema-on-read), 데이터 형식, 트랜잭션 지원과 AWS 서비스 매핑 비교
세 패러다임의 스키마 적용 시점(schema-on-write vs schema-on-read), 데이터 형식, 트랜잭션 지원과 AWS 서비스 매핑 비교
1. 데이터를 한곳에 모으는 이유
서비스 데이터는 보통 여러 운영 데이터베이스와 로그, 외부 소스에 흩어져 있습니다. 분석이나 리포팅을 하려면 이 데이터를 한곳에 모아 일관된 방식으로 조회할 수 있어야 합니다. 운영 DB에 직접 분석 쿼리를 던지면 서비스 트래픽에 영향을 주고, 소스마다 형식이 달라 조인도 어렵습니다.
1.1. OLTP와 OLAP는 다르다
이 차이의 바탕에는 두 종류의 워크로드가 있습니다.
- OLTP(Online Transaction Processing): 주문 생성, 회원 가입처럼 짧고 빈번한 트랜잭션. 행 단위로 적은 데이터를 빠르게 읽고 쓰는 데 최적화됩니다. 운영 DB(MySQL, PostgreSQL 등)가 여기에 해당합니다.
- OLAP(Online Analytical Processing): 기간별 매출 집계, 코호트 분석처럼 많은 행을 스캔해 집계하는 분석 쿼리. 컬럼 단위로 대량 데이터를 읽는 데 최적화됩니다.
운영 DB는 OLTP에 맞게 설계돼 있어, 대량 스캔이 필요한 OLAP 쿼리를 그대로 돌리면 성능이 나오지 않고 서비스에도 영향을 줍니다. 그래서 분석용으로 데이터를 따로 모아 OLAP에 맞게 저장하는 저장소가 필요합니다.
이 저장소를 어떤 형태로 구성하느냐가 세 패러다임을 가르는 출발점입니다. 정제된 정형 데이터만 담을지, 원본을 그대로 담을지, 둘의 장점을 합칠지에 따라 웨어하우스, 레이크, 레이크하우스로 나뉩니다.
2. Data Warehouse - 정형 데이터의 분석 본진
데이터 웨어하우스는 가장 오래된 패러다임으로, 정형 데이터(structured data) 를 분석에 최적화된 형태로 저장합니다. 1980~90년대에 기업의 의사결정 지원을 위해 정립됐고, 여러 운영 시스템의 데이터를 통합해 주제별로 정리한 “단일 진실 공급원(single source of truth)”을 목표로 합니다.
2.1. schema-on-write
웨어하우스의 핵심 특성은 schema-on-write입니다. 데이터를 적재하기 전에 스키마(테이블 구조, 타입)를 먼저 정의하고, ETL(Extract-Transform-Load) 과정에서 데이터를 그 스키마에 맞게 정제한 뒤 적재합니다. 즉 저장 시점에 이미 깔끔하게 정돈된 상태가 됩니다.
1
2
운영 DB / 로그 -> [Extract] -> [Transform: 정제/정규화] -> [Load] -> Warehouse
(스키마를 여기서 강제)
이 덕분에 조회가 매우 빠르고 예측 가능합니다. 대부분의 웨어하우스는 컬럼형(columnar) 저장과 MPP(Massively Parallel Processing) 를 사용해, 많은 행을 스캔하는 집계 쿼리를 여러 노드로 분산 처리합니다. 분석에서 자주 쓰는 star schema(사실 테이블 + 차원 테이블) 같은 모델링도 정형 스키마 위에서 잘 동작합니다. BI 도구로 대시보드와 리포트를 만들기에 적합합니다.
대표적인 제품으로 Amazon Redshift, Snowflake, Google BigQuery 등이 있습니다.
2.2. 장단점
| 항목 | 내용 |
|---|---|
| 강점 | 빠른 쿼리 성능, 강한 거버넌스, BI/리포팅 최적 |
| 약점 | 스토리지 비용이 높음, 정형 데이터에 한정, 스키마 변경이 경직적 |
비정형 데이터(로그 원본, 이미지, JSON 덩어리)를 그대로 담기 어렵고, 스키마를 먼저 확정해야 하므로 새로운 데이터 소스를 빠르게 실험하기에는 부담이 있습니다.
3. Data Lake - 원본 그대로 적재
데이터 레이크는 웨어하우스의 경직성을 풀기 위해 2010년대 빅데이터(Hadoop) 흐름과 함께 등장했습니다. 형식을 가리지 않고 원본 그대로 저장합니다. 정형 데이터뿐 아니라 로그, JSON, 이미지 같은 반정형/비정형 데이터까지 한곳에 담습니다.
3.1. schema-on-read
레이크의 핵심 특성은 schema-on-read입니다. 데이터를 적재할 때는 스키마를 강제하지 않고 원본(CSV, JSON, Parquet, 로그 등)을 그대로 저장합니다. 스키마는 읽는 시점에 적용합니다. 예를 들어 S3에 쌓인 파일에 Glue Data Catalog로 테이블 정의를 입혀 Athena로 조회하는 방식이 schema-on-read입니다.
1
2
운영 DB / 로그 -> [Extract] -> [Load: 원본 그대로] -> Lake (S3)
-> [Transform: 읽을 때 스키마 적용]
이 순서 차이가 곧 ETL과 ELT의 차이입니다. 웨어하우스는 적재 전에 변환(ETL)하지만, 레이크는 일단 적재한 뒤 필요할 때 변환(ELT)합니다. 덕분에 어떤 형식이든 일단 저렴하게 담아 두고, 나중에 필요할 때 구조를 부여해 분석할 수 있습니다. 적재가 가볍고 유연하며, 저장은 보통 S3 같은 저비용 객체 스토리지에 Parquet/ORC 같은 컬럼형 파일로 둡니다.
3.2. 장단점 - 데이터 늪 주의
| 항목 | 내용 |
|---|---|
| 강점 | 저비용 스토리지, 형식 무관, 유연한 적재 |
| 약점 | 거버넌스/품질 관리가 약함, 트랜잭션 부재 |
레이크의 약점은 관리가 없으면 통제가 빠르게 무너진다는 점입니다. 무엇이 어디에 있는지, 어떤 데이터가 믿을 만한지 추적되지 않으면, 데이터가 쌓이기만 하고 쓸 수 없는 데이터 늪(data swamp) 이 됩니다. 또한 파일 더미 위에서는 ACID 트랜잭션이나 부분 수정 같은 “진짜 테이블” 기능이 어렵습니다.
4. Data Lakehouse - 레이크 위에 웨어하우스 기능
레이크하우스는 이름 그대로 레이크(lake)와 웨어하우스(house)의 결합입니다. 레이크의 저렴하고 유연한 저장 방식을 유지하면서, 웨어하우스가 제공하던 기능(ACID 트랜잭션, 스키마 관리, 빠른 SQL)을 그 위에 얹습니다. 2020년 전후로 본격화된 비교적 최근의 패러다임으로, 레이크와 웨어하우스를 따로 운영하며 데이터를 복제하던 부담을 줄이려는 흐름에서 나왔습니다.
4.1. 테이블 포맷이 핵심
이 결합을 가능하게 하는 것이 테이블 포맷(table format) 입니다. Apache Iceberg, Delta Lake, Apache Hudi 같은 포맷은 S3 같은 객체 스토리지 위에 메타데이터 계층을 얹어, 파일 더미를 “진짜 테이블”처럼 다루게 해 줍니다.
테이블 포맷이 제공하는 대표 기능은 다음과 같습니다.
- ACID 트랜잭션: 동시 쓰기 충돌 없이 일관된 읽기/쓰기
- 스키마 진화: 기존 데이터를 다시 쓰지 않고 컬럼 추가/삭제
- 시간여행(time travel): 과거 스냅샷 조회
- 부분 수정: 행 단위 update/delete
4.2. 무엇을 해결하나
레이크하우스는 “싸고 유연하지만 통제가 어려운” 레이크의 약점과 “통제는 강하지만 비싸고 경직적인” 웨어하우스의 약점을 동시에 줄이려는 시도입니다. 데이터는 개방형 포맷으로 객체 스토리지에 그대로 두되, 그 위에서 정형 데이터베이스처럼 트랜잭션과 스키마를 보장받습니다. 데이터를 웨어하우스로 따로 옮기지 않고도 신뢰할 수 있는 분석을 할 수 있다는 것이 핵심입니다.
또 하나의 장점은 개방형 포맷(open format) 이라는 점입니다. Iceberg 같은 테이블 포맷은 특정 엔진에 묶이지 않으므로, 같은 데이터를 Athena, Spark, Trino, Redshift 등 여러 엔진이 함께 읽을 수 있습니다. 데이터를 한 벤더의 독점 포맷에 가두지 않아 lock-in을 줄입니다.
5. 한눈에 비교
지금까지의 차이를 한 표로 정리하면 다음과 같습니다.
| 항목 | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| 스키마 시점 | schema-on-write | schema-on-read | schema-on-read + 강제 가능 |
| 데이터 형식 | 정형 | 정형/반정형/비정형 | 정형/반정형/비정형 |
| 변환 순서 | ETL | ELT | ELT |
| 트랜잭션 | 있음 | 없음1 | 있음(테이블 포맷) |
| 거버넌스 | 강함 | 약함 | 강함 |
| 스토리지 비용 | 높음 | 낮음 | 낮음 |
| 쿼리 성능 | 높음 | 보통 | 높음 |
| 대표 용도 | BI/리포팅 | 원본 적재/탐색 | 통합 분석 |
6. AWS 매핑
세 패러다임은 AWS에서 각각 다음 서비스 조합으로 구현됩니다.
| 패러다임 | AWS 구현 | 비고 |
|---|---|---|
| Data Warehouse | Amazon Redshift | 컬럼형 MPP 웨어하우스, 정형 분석 |
| Data Lake | Amazon S3 + AWS Glue + Amazon Athena | S3=저장, Glue=메타데이터, Athena=쿼리 |
| Data Lakehouse | Amazon S3 Tables + Athena + AWS Lake Formation | S3 Tables=관리형 Iceberg, LF=거버넌스 |
위 표는 각 패러다임의 가장 대표적인 한 가지 조합일 뿐, 유일한 정답은 아닙니다. 예를 들어 웨어하우스는 Redshift 외에 Snowflake/BigQuery로, 레이크하우스의 쿼리 엔진은 Athena 외에 Spark/Trino/Redshift Spectrum으로 얼마든지 바꿔 끼울 수 있습니다. 여기서는 AWS 기준의 표준적인 출발점을 한 줄로 보여 주는 데 초점을 둡니다.
Amazon S3 Tables는 관리형 Apache Iceberg 테이블 버킷으로, 레이크하우스의 테이블 포맷 계층을 AWS가 운영해 주는 형태입니다. 여기에 AWS Lake Formation이 fine-grained 권한과 거버넌스를 더하면, 레이크의 저장 위에서 웨어하우스 수준의 통제를 갖춘 레이크하우스가 됩니다. S3 Tables와 Lake Formation은 이 시리즈의 뒤쪽 글에서 각각 자세히 다룹니다.
7. 언제 무엇을
세 패러다임은 서로를 완전히 대체한다기보다, 데이터의 성격과 요구에 따라 선택하거나 함께 쓰는 대상입니다.
- 정형 데이터로 BI/리포팅을 빠르게: Data Warehouse(Redshift)가 강점입니다.
- 형식이 다양한 원본을 저비용으로 모아 탐색: Data Lake(S3+Glue+Athena)가 적합합니다.
- 레이크의 유연함과 웨어하우스의 신뢰성을 동시에: Data Lakehouse(S3 Tables+Athena+Lake Formation)가 균형점입니다.
실제 환경에서는 운영 데이터를 레이크에 모으고, 일부를 레이크하우스 테이블로 관리하며, 고성능 BI가 필요한 영역만 웨어하우스로 보내는 식으로 혼합해 쓰는 경우가 많습니다. 중요한 것은 각 패러다임이 무엇을 위해 어떤 트레이드오프를 택했는지를 이해하고, 데이터와 요구에 맞게 선택하는 것입니다.
8. Reference
- AWS - What is a Data Warehouse?
- AWS - What is a Data Lake?
- AWS - What is a Data Lakehouse?
- Amazon S3 Tables
- Apache Iceberg
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi
정확히는 트랜잭션 부재가 “Data Lake”라는 패러다임의 본질적 한계는 아닙니다. S3 같은 객체 스토리지에 쌓인 raw 파일 더미 자체가 트랜잭션을 모를 뿐이고, 같은 레이크 스토리지 위에 Apache Iceberg 같은 테이블 포맷을 얹으면 ACID 트랜잭션이 생깁니다. Iceberg는 “brings the reliability and simplicity of SQL tables to big data”라고 스스로를 설명합니다. 즉 트랜잭션 유무를 가르는 경계는 저장 위치(레이크 vs 웨어하우스)가 아니라 그 위에 테이블 포맷이 있는지 여부이며, 이 경계 위에 선 형태가 곧 4절의 레이크하우스입니다. ↩︎