분산 SQL 엔진이란 - Trino/Presto와 단일 노드 SQL 엔진의 차이

데이터 레이크나 레이크하우스에 쌓인 대규모 데이터를 SQL로 빠르게 조회하는 일의 중심에는 분산 SQL 엔진이 있습니다. Amazon Athena가 데이터를 옮기지 않고도 여러 소스를 한 쿼리로 조인하고 빠르게 응답하는 것도, 그 바탕에 분산 SQL 엔진이 있기 때문입니다. 이번 글에서는 SQL 엔진이 무엇이고, 단일 노드 엔진과 분산 SQL 엔진(Trino/Presto)이 어떻게 다른지, 그리고 Athena가 그것을 어떻게 활용하는지를 알아봅니다.
TL;DR
- SQL 엔진(쿼리 엔진) 은 데이터를 저장하지 않고 쿼리를 실행하는 컴퓨트 계층입니다. 저장과 분리돼 외부 스토리지를 읽습니다.
- 단일 노드 엔진은 한 프로세스가 모든 일을 하므로 한 대의 자원에 묶입니다.
- 분산 SQL 엔진(MPP) 은 coordinator + worker 구조로 쿼리를 여러 worker에 쪼개 병렬 처리합니다.
- Presto(Facebook, 2012)가 이 계보를 열었고, 2019년 분기 후 Trino(2020년 리브랜드)로 이어집니다.
- Amazon Athena는 이 엔진을 서버리스로 감싼 관리형 서비스입니다. engine v3는 Trino 기반입니다.
1. SQL 엔진과 데이터베이스는 다르다
흔히 SQL을 떠올리면 MySQL, PostgreSQL 같은 데이터베이스를 생각합니다. 하지만 분석 스택에서 말하는 SQL 엔진(query engine) 은 그것과 결이 다릅니다.
- 데이터베이스: 데이터를 저장하면서 동시에 쿼리를 실행합니다. 저장(storage)과 엔진(compute)이 한 시스템에 묶여 있습니다.
- 쿼리 엔진: 데이터를 직접 저장하지 않습니다. 외부 스토리지(S3 등)에 있는 데이터를 읽어 쿼리만 실행하는 컴퓨트 계층입니다.
즉 쿼리 엔진은 storage와 compute가 분리된 모델입니다. Athena가 S3의 데이터를 적재 없이 조회할 수 있는 것도, 엔진이 스토리지와 분리돼 있기 때문입니다. Trino/Presto가 바로 이런 쿼리 엔진이고, Athena는 그것을 관리형으로 제공합니다.
2. 단일 노드 SQL 엔진의 한계
쿼리를 실행하는 가장 단순한 형태는 단일 노드(single-node) 엔진입니다. 한 프로세스가 쿼리를 파싱하고, 데이터를 읽고, 집계까지 모두 수행합니다. SQLite나 한 대로 운영하는 데이터베이스 인스턴스가 여기에 가깝습니다.
이 방식은 단순하지만, 처리량이 한 대의 CPU/메모리/디스크에 묶입니다. 데이터가 수 TB로 커지거나 무거운 집계가 들어오면, 한 프로세스가 모든 데이터를 순차적으로 스캔하느라 한계에 부딪힙니다. 더 큰 장비로 바꾸는 수직 확장(scale-up)에는 물리적 상한이 있습니다.
분석 워크로드는 많은 행을 스캔해 집계하는 특성이 있어, 이 한계가 특히 두드러집니다. 그래서 작업을 여러 대에 나눠 병렬로 처리하는 방식이 필요해졌습니다.
3. 분산 SQL 엔진 = MPP
분산 SQL 엔진은 MPP(Massively Parallel Processing) 구조로 이 한계를 풉니다. 하나의 쿼리를 여러 노드에 쪼개 동시에 처리하는 방식입니다.
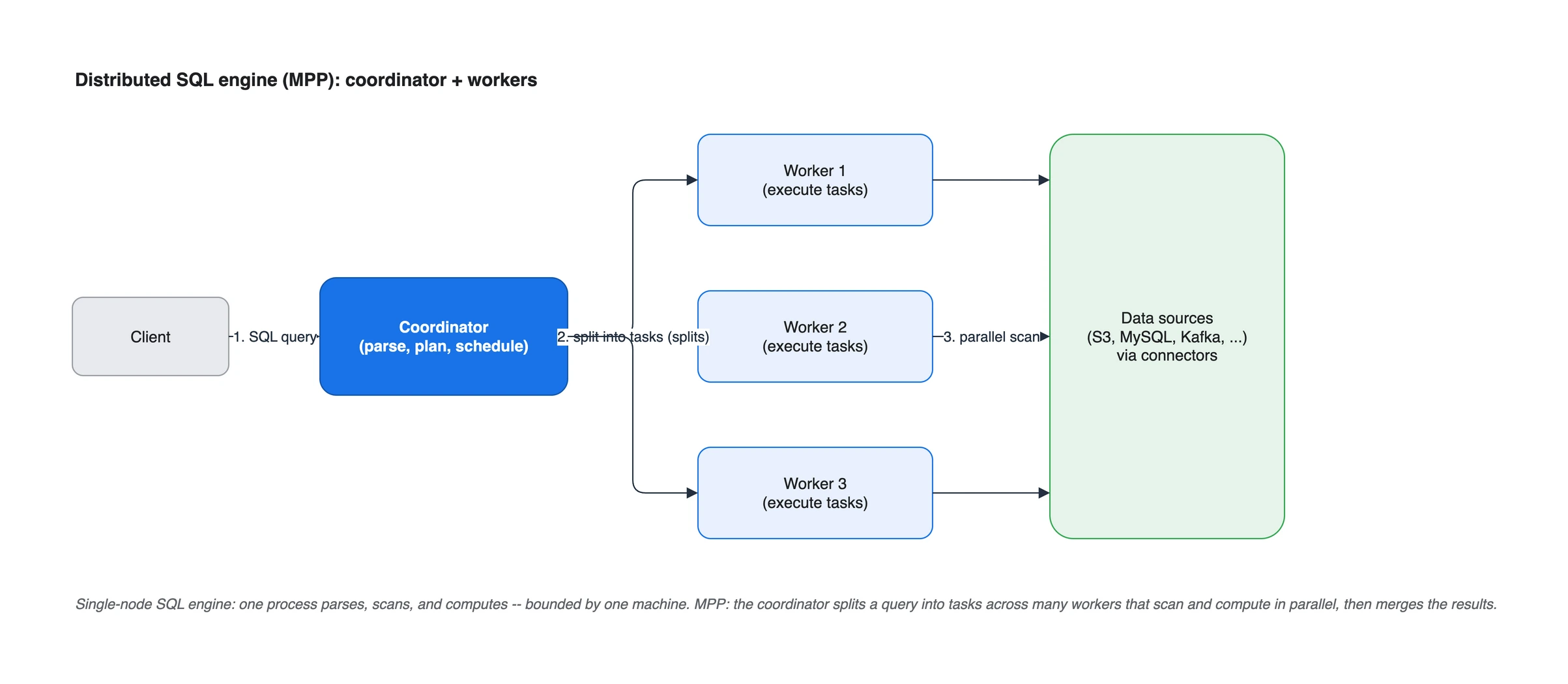 coordinator가 쿼리를 stage/task/split으로 쪼개 여러 worker에 분배하고, worker들이 동시에 데이터를 처리한 뒤 결과를 모아 클라이언트로 돌려주는 MPP 구조
coordinator가 쿼리를 stage/task/split으로 쪼개 여러 worker에 분배하고, worker들이 동시에 데이터를 처리한 뒤 결과를 모아 클라이언트로 돌려주는 MPP 구조
3.1. coordinator와 worker
분산 SQL 엔진은 두 종류의 노드로 구성됩니다.
- Coordinator: 클라이언트의 쿼리를 받아 파싱하고, 분석/최적화해 실행 계획을 세우고, 작업을 worker에 분배하고 스케줄링합니다.
- Worker: coordinator가 나눠 준 작업을 실제로 실행합니다. 데이터 소스에서 데이터를 읽어 처리합니다.
다이어그램처럼, 한 쿼리가 들어오면 coordinator가 그것을 잘게 나눠 여러 worker에 분배하고, worker들이 동시에 병렬로 데이터를 스캔/처리한 뒤 결과를 모아 클라이언트에 돌려줍니다. 노드를 늘리면 처리량이 늘어나는 수평 확장(scale-out) 이 가능합니다.
3.2. stage, task, split
쿼리는 여러 단계로 쪼개집니다. coordinator는 실행 계획을 stage로 나누고, 각 stage를 worker에서 실행할 task로, 데이터를 다시 split(읽을 데이터 조각) 단위로 나눕니다. Trino 공식 문서는 이 분해 구조를 다음과 같이 설명합니다.
When Trino executes a query, it does so by breaking up the execution into a hierarchy of stages.
A stage is implemented as a series of tasks distributed over a network of Trino workers.
Tasks operate on splits, which are sections of a larger data set.
즉 stage -> task -> split의 3계층입니다. stage는 논리적 실행 단계, task는 그 stage를 특정 worker에서 실행하는 실체, split은 task가 읽어 들이는 데이터 조각입니다. 각 task 안에는 또 여러 개의 driver가 병렬로 돌며 연산자(operator)를 묶어 데이터를 처리합니다.
Tasks contain one or more parallel drivers. Drivers act upon data and combine operators to produce output that is then aggregated by a task and then delivered to another task in another stage.
이 분해는 EXPLAIN으로 직접 들여다볼 수 있습니다. EXPLAIN (TYPE DISTRIBUTED)를 붙이면 쿼리가 어떤 stage(Fragment)들로 쪼개지고 각 stage가 데이터를 어떻게 분배(Output partitioning)받는지 출력합니다.
1
2
3
4
EXPLAIN (TYPE DISTRIBUTED)
SELECT region, count(*)
FROM sales.orders
GROUP BY region;
1
2
3
4
5
6
7
8
9
10
Fragment 0 [SINGLE]
Output[region, count]
└─ RemoteSource[1]
Fragment 1 [HASH]
Aggregate(FINAL)[region]
└─ LocalExchange[HASH]
└─ RemoteSource[2]
Fragment 2 [SOURCE]
Aggregate(PARTIAL)[region]
└─ TableScan[sales.orders]
Fragment 2(SOURCE stage)가 테이블을 스캔하며 부분 집계(PARTIAL)를 하고, Fragment 1이 같은 키끼리 모아 최종 집계(FINAL)를, Fragment 0이 결과를 모아 클라이언트로 돌려줍니다. 여러 worker가 여러 split을 동시에 처리하므로, 데이터가 커져도 worker를 늘려 대응할 수 있습니다.
3.3. 메모리 파이프라인 실행과 exchange
Trino/Presto가 빠른 또 다른 이유는 기본 실행 모드에서는 메모리 기반 파이프라인 실행을 한다는 점입니다. 초기 빅데이터 엔진인 Hive는 MapReduce 위에서 동작해, 단계마다 중간 결과를 디스크에 쓰고 다음 단계가 그것을 다시 읽었습니다. 이 디스크 왕복이 대화형 쿼리에는 큰 지연으로 작용했습니다.
분산 SQL 엔진은 이를 다르게 처리합니다. stage 사이에서 데이터를 worker 간으로 옮기는 단계를 exchange라고 부릅니다.
Exchanges transfer data between Trino nodes for different stages of a query.
기본 실행 모드에서 이 exchange는 중간 결과를 디스크에 쓰지 않고 메모리에서 worker 간으로 흘려보내며(streaming/pipelining) 처리합니다. 한 stage의 결과가 만들어지는 대로 다음 stage가 이어받아, 디스크 왕복 없이 파이프라인처럼 흐릅니다. 이 구조 덕분에 분산 SQL 엔진은 storage와 compute가 분리된 채로, 외부 스토리지의 대규모 데이터를 병렬로 빠르게 조회합니다.
다만 “메모리 기반”은 무조건 모든 중간 데이터를 메모리에만 둔다는 뜻은 아닙니다. 메모리에 다 담기 어려운 무거운 집계나 조인, 정렬은 일부를 디스크로 흘려보내는 spill-to-disk 옵션으로 처리할 수 있고, 아래의 fault-tolerant execution 모드에서는 exchange 데이터를 의도적으로 외부에 저장합니다. streaming 파이프라인은 어디까지나 기본(대화형) 실행 모드의 특징입니다.
3.4. fault-tolerant execution
기본 streaming 모드는 빠르지만, 중간 결과를 어디에도 보존하지 않으므로 worker 하나가 죽으면 쿼리 전체가 실패합니다. 짧은 대화형 쿼리에는 문제없지만, 수십 분씩 걸리는 큰 배치 쿼리에서는 거의 끝난 쿼리가 노드 하나 때문에 통째로 다시 도는 일이 생깁니다. Trino는 이를 위해 fault-tolerant execution이라는 별도 실행 모드를 제공합니다.
Fault-tolerant execution is a mechanism in Trino that enables a cluster to mitigate query failures by retrying queries or their component tasks in the event of failure.
핵심은 exchange 데이터를 메모리로만 흘리지 않고 외부에 저장(spool)해 두는 것입니다. 덕분에 한 worker가 죽어도 다른 worker가 그 중간 데이터를 이어받아 실패한 부분만 다시 실행할 수 있습니다.
With fault-tolerant execution enabled, intermediate exchange data is spooled and can be re-used by another worker in the event of a worker outage or other fault during query execution.
재시도 단위는 정책으로 고릅니다. QUERY 정책은 쿼리 전체를 다시 돌리는 방식으로 작은 쿼리가 많은 환경에 맞고, TASK 정책은 실패한 task만 다시 돌려 큰 배치 쿼리에 유리합니다. 단, fault-tolerant execution은 streaming 대비 spool 오버헤드가 있어 대화형 저지연 쿼리에는 적합하지 않습니다. 또한 SQL 파싱 실패 같은 사용자 오류는 재시도 대상이 아닙니다.
Fault tolerance does not apply to broken queries or other user error. For example, Trino does not spend resources retrying a query that fails because its SQL cannot be parsed.
4. Presto에서 Trino로
이 계보의 출발점은 Presto입니다.
4.1. Presto (Facebook, 2012)
Presto는 Facebook(현 Meta)에서 2012년에 개발됐고, 2013년 11월 오픈소스로 공개됐습니다. 당시 Facebook은 거대한 데이터 웨어하우스를 Apache Hive로 조회했는데, Hive(MapReduce 기반)가 대화형 분석에는 너무 느려 더 빠른 대안이 필요했습니다. 앞서 본 메모리 파이프라인 실행이 바로 이 문제를 푼 핵심이었습니다. Presto는 “빅데이터를 위한 분산 SQL 쿼리 엔진”으로, 여러 데이터 소스를 한 쿼리로 조회할 수 있도록 설계됐습니다. 창시자는 Martin Traverso, Dain Sundstrom, David Phillips, Eric Hwang입니다.
4.2. 분기와 Trino 리브랜드 (2019~2020)
Presto는 2019년에 갈라집니다. 2019년 1월 Presto Software Foundation이 만들어지면서 개발이 두 갈래로 나뉘었습니다.
- PrestoDB: Facebook이 유지. 2019년 9월 Linux Foundation에 기부되어 Presto Foundation으로 이관됐습니다.
- PrestoSQL: 원 창시자들(Martin Traverso, Dain Sundstrom, David Phillips 등)이 유지하던 갈래로, 2020년 12월 Trino로 리브랜드됐습니다.
오늘날 “Trino”와 “Presto”는 같은 뿌리에서 갈라진 두 프로젝트입니다. 둘 다 분산 SQL 쿼리 엔진이라는 정체성은 같습니다.
5. connector 모델 - federation
분산 SQL 엔진의 강력한 특징 중 하나가 connector 모델입니다. 엔진 자체는 데이터를 저장하지 않으므로, 어떤 데이터 소스든 connector를 통해 연결해 읽을 수 있습니다.
Trino/Presto는 S3 같은 객체 스토리지뿐 아니라 MySQL, PostgreSQL, Cassandra, Kafka, MongoDB, Elasticsearch 등 다양한 소스용 connector를 제공합니다. 덕분에 서로 다른 소스의 데이터를 한 쿼리로 조인하는 federation(연합 쿼리)이 가능합니다. 데이터를 한곳으로 옮기지 않고도, 엔진이 각 소스에서 필요한 데이터를 읽어 합칩니다.
1
2
3
4
-- 개념 예시: 객체 스토리지의 테이블과 관계형 DB의 테이블을 한 쿼리로 조인
SELECT o.id, c.grade
FROM lake.sales.orders o
JOIN mysql.crm.customers c ON c.id = o.customer_id;
connector는 단순히 데이터를 읽어 오기만 하는 것이 아닙니다. 가능한 경우 필터와 컬럼 선택을 데이터 소스 쪽으로 내려보내는 pushdown(predicate/projection pushdown)을 수행합니다. 예를 들어 관계형 DB connector는 WHERE 조건을 소스 DB에서 먼저 거르게 하고, 컬럼 기반 파일에서는 필요한 컬럼만 읽습니다. 엔진으로 가져오는 데이터 양 자체를 줄여, 네트워크와 처리 비용을 함께 낮춥니다.
여기서 주의할 점은 어떤 pushdown을 지원하는지는 connector마다 다르다는 것입니다. predicate pushdown은 폭넓게 지원되지만, aggregation pushdown이나 join pushdown은 소스 시스템 능력에 따라 connector별로 지원 여부가 갈립니다. Trino 공식 문서도 이를 명시합니다.
Support for pushdown is specific to each connector and the relevant underlying database or storage system.
The specifics for the supported pushdown of table joins varies for each data source, and therefore for each connector.
따라서 같은 SQL이라도 어떤 소스에 붙느냐에 따라 실제로 소스로 내려가는 연산이 달라지고, 그만큼 성능 차이가 생깁니다. federation을 설계할 때는 대상 connector가 어떤 pushdown을 지원하는지 확인해 두는 편이 좋습니다.
이 connector 기반 federation이 분산 SQL 엔진을 단순한 쿼리 실행기를 넘어 여러 데이터 소스를 통합하는 계층으로 만들어 줍니다.
6. Amazon Athena는 관리형 Trino/Presto
Athena가 “서버리스 쿼리 엔진”인 이유가 여기서 분명해집니다. Athena는 이 분산 SQL 엔진을 서버리스로 감싼 관리형 서비스입니다. 사용자는 coordinator/worker 클러스터를 직접 운영하지 않고, 쿼리만 던지면 AWS가 그 아래에서 엔진을 실행합니다. Athena 자체의 쿼리 흐름과 메타스토어는 이 시리즈의 뒤쪽 글에서 자세히 다룹니다.
Athena의 엔진 버전은 오픈소스 프로젝트와 직접 연결됩니다.
- engine version 1/2: Presto 기반
- engine version 3: Trino 기반. AWS 문서에 따르면 engine version 3는 Trino, Presto 프로젝트와의 연속적 통합(CI) 방식을 도입해, 커뮤니티 개선을 더 빠르게 반영합니다.
For engine version 3, Athena has introduced a continuous integration approach to open source software management that improves concurrency with the Trino and Presto projects so that you get faster access to community improvements, integrated and tuned within the Athena engine.
이전 engine version 1, 2는 이미 제공이 종료되었으므로 신규 워크그룹은 engine version 3를 쓰는 것이 사실상 표준입니다. AWS는 더 이상 제공되지 않는 버전의 워크그룹을 자동 업그레이드한다고 밝히고 있습니다.
In both cases, Athena upgrades your workgroups when a version is no longer available.
다만 차이도 있습니다. Athena는 Trino/Presto의 native connector를 그대로 쓰지 않고, 외부 소스 연결에는 Amazon Athena Federated Query(Lambda 기반 커넥터)를 사용합니다. 즉 federation의 개념은 같지만 구현 방식이 AWS 환경에 맞춰져 있습니다. AWS는 engine version 3의 limitation에서 이 점을 분명히 합니다.
Neither Trino nor Presto connectors are supported. Use Amazon Athena Federated Query to connect data sources.
또 한 가지, 앞서 본 Trino의 fault-tolerant execution은 Athena에서는 사용할 수 없습니다. Athena의 쿼리 실행은 기본 streaming 모드 기반이라고 이해하면 됩니다.
Trino fault-tolerant execution (Trino Tardigrade) is not supported.
정리하면, Athena로 쿼리를 던질 때 그 아래에서는 Trino(engine v3) 엔진이 쿼리를 stage/task/split으로 나눠 병렬 처리하고 있습니다. “서버리스”는 이 엔진 클러스터를 사용자가 운영하지 않아도 된다는 의미입니다.
7. Spark SQL, Redshift와는 무엇이 다른가
분산 처리를 한다는 점에서 비슷해 보이는 다른 시스템과 간단히 구분해 둡니다.
| 구분 | 성격 |
|---|---|
| Trino / Presto | 대화형 분석에 최적화된 분산 SQL 쿼리 엔진. 저장과 분리, 여러 소스 federation |
| Spark SQL | 범용 분산 처리 프레임워크(Spark) 위의 SQL. ETL/배치/ML까지 포함하는 넓은 워크로드 |
| Amazon Redshift | 컬럼형 MPP 데이터 웨어하우스. 자체 스토리지에 적재한 정형 데이터 분석에 강함 |
Trino/Presto는 “이미 어딘가에 있는 데이터를 빠르게 조회/조인”하는 대화형 쿼리에 강하고, Spark는 더 넓은 데이터 처리 파이프라인에, Redshift는 적재된 정형 데이터의 고성능 분석에 적합합니다. 셋은 경쟁하기도 하지만 역할이 겹치면서도 달라, 환경에 따라 함께 쓰이는 경우가 많습니다.
8. Reference
- Trino - Overview
- Presto
- Trino concepts (coordinator, worker, connector)
- Trino - Pushdown
- Trino - Fault-tolerant execution
- Amazon Athena engine versioning
- Amazon Athena engine version 3
- Using Amazon Athena Federated Query
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi