데이터 분석 아키텍처의 역사와 변천사

이 글은 AWS 데이터 분석 스택 시리즈의 출발점입니다. 데이터 웨어하우스, 데이터 레이크, 레이크하우스 같은 용어는 어느 날 동시에 등장한 것이 아니라, 각각 직전 방식의 한계를 풀면서 순서대로 진화한 결과입니다. 그 변천사를 시간 축으로 따라가며, 왜 이런 흐름이 생겼는지를 정리합니다. 세 패러다임의 정적인 비교는 이어지는 글 데이터 웨어하우스 vs 데이터 레이크 vs 레이크하우스에서 따로 다룹니다.
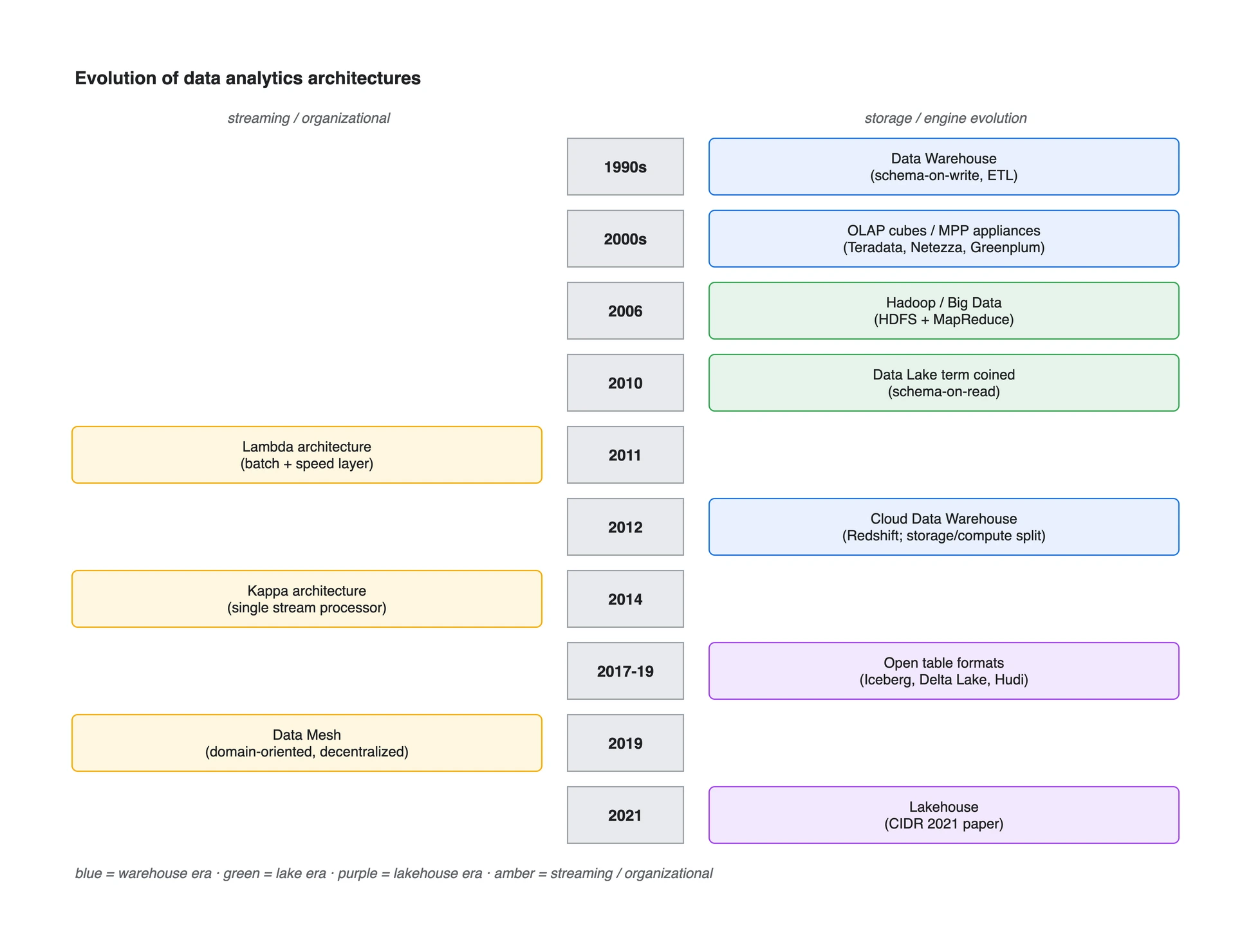
큰 줄기는 두 개의 축으로 볼 수 있습니다. 하나는 저장/엔진의 기술 축(먼저 정제하는 웨어하우스 -> 원본도 보관하는 레이크 -> 테이블 기능을 더한 레이크하우스)이고, 다른 하나는 조직/처리 방식의 축(중앙집중 -> 분산 거버넌스, 배치 -> 스트리밍)입니다. 이 글의 세대 구분은 업계의 절대적인 연표가 아니라, 각 선택이 어떤 운영 문제를 해결하려 했는지 설명하기 위한 관점입니다.
TL;DR
- 1세대(1990년대) 데이터 웨어하우스: 적재 전에 정제하는 schema-on-write. Inmon의 전사 모델과 Kimball의 차원 모델이 대표적입니다.
- 2세대(2000년대 후반) 빅데이터/데이터 레이크: Hadoop 생태계와 함께 원본을 보관하고, 읽을 때 구조를 적용하는 schema-on-read가 널리 쓰였습니다. “Data Lake”라는 비유는 James Dixon의 2010년 글로 널리 알려졌습니다.
- 클라우드 전환(2010년대): 관리형 웨어하우스와 객체 스토리지가 확산했고, Snowflake는 스토리지와 컴퓨트를 분리한 멀티클러스터 구조를 대표적으로 제시했습니다.
- 3세대(2017~2021) 레이크하우스: Iceberg, Delta Lake, Hudi 같은 테이블 포맷이 레이크의 파일을 트랜잭션 가능한 테이블로 관리했고, CIDR 2021 논문이 lakehouse 아키텍처를 체계적으로 설명했습니다.
- 직교 축으로 스트리밍(Lambda 2011, Kappa 2014)과 조직(Data Mesh 2019) 흐름이 있습니다.
아래 타임라인이 전체 흐름을 한눈에 보여 줍니다. 오른쪽이 저장/엔진의 기술 축, 왼쪽이 스트리밍/조직 축입니다.
1. 분석은 운영과 다르다
변천사의 출발점에는 두 종류의 워크로드가 있습니다. OLTP(Online Transaction Processing) 는 주문 생성처럼 짧고 빈번한 트랜잭션을 처리하는 운영 DB의 영역이고, OLAP(Online Analytical Processing) 는 대량의 행을 스캔해 집계하는 분석의 영역입니다. 운영 DB에 분석 쿼리를 그대로 돌리면 성능이 나오지 않고 서비스에도 영향을 줍니다.
이 간극을 메우기 위해 분석 전용 저장소가 필요해졌고, 그 저장소를 어떻게 구성하느냐가 시대별로 달라지면서 지금의 변천사가 만들어졌습니다.
2. 1세대: 데이터 웨어하우스 (1990s)
가장 먼저 자리 잡은 것은 데이터 웨어하우스입니다. 여러 운영 시스템의 데이터를 통합해 분석에 최적화된 형태로 저장하는 “단일 진실 공급원”을 목표로 했습니다.
이 시기를 정립한 두 인물이 있습니다.
- Bill Inmon: 1992년 저서 『Building the Data Warehouse』에서 top-down 접근을 제시했습니다. 정규화된 전사 데이터 웨어하우스(EDW)를 먼저 구축하고, 거기서 부서별 데이터 마트(data mart) 를 파생시키는 방식입니다.
- Ralph Kimball: 1996년 저서 『The Data Warehouse Toolkit』에서 bottom-up 접근과 dimensional modeling(star schema)을 제시했습니다. 분석 주제별 데이터 마트를 먼저 만들어 통합하는 방식입니다.
두 학파 모두 공통적으로 schema-on-write를 따릅니다. 데이터를 적재하기 전에 스키마를 확정하고 ETL(Extract, Transform, Load) 로 정제한 뒤 넣으므로, 저장 시점에 이미 정돈되어 있습니다. 이 방식은 반복 분석에 유리하지만, 새 데이터 소스와 변경을 적재 과정에서 조정해야 한다는 비용이 있습니다.
3. OLAP과 MPP 어플라이언스 (2000s)
웨어하우스 위에서 분석을 빠르게 하기 위한 기술도 발전했습니다. OLAP은 데이터를 미리 다차원 큐브(cube)로 집계해 두고 차원을 바꿔 가며 빠르게 조회하는 방식입니다. 핵심 메커니즘은 사전 집계(pre-aggregation) 입니다. “지역 x 월 x 상품군별 매출 합계” 같은 조합을 쿼리 시점이 아니라 적재 시점에 미리 계산해 큐브 셀에 채워 두면, 사용자가 차원을 바꿔 가며(drill-down/roll-up) 조회해도 원본 행을 다시 스캔하지 않고 셀 값을 읽어 오기만 하면 됩니다. 빠른 응답을 대량의 사전 계산과 저장 공간으로 사는 트레이드오프입니다.
저장 방식에 따라 MOLAP과 ROLAP으로 나뉘며, 둘은 정반대의 트레이드오프를 갖습니다. MOLAP은 집계 결과를 전용 다차원 배열에 물리적으로 저장합니다. 조회는 가장 빠르지만, 차원과 멤버 수가 늘수록 채워야 할 셀 조합이 곱셈적으로 폭증하는 데이터 폭발(data explosion) 과 사전 계산 시간, 그리고 정형 큐브에 갇히는 경직성이 약점입니다. ROLAP은 별도 큐브 없이 관계형 웨어하우스의 star schema에 SQL GROUP BY 집계를 그때그때 돌립니다. 큰 테이블도 스키마만 바꾸면 수용할 수 있어 확장성과 유연성은 좋지만, 사전 집계가 없으니 조회 때마다 대량 스캔이 일어나 응답이 느려집니다. 즉 MOLAP은 “미리 다 계산(빠르지만 무겁고 경직적)”, ROLAP은 “그때그때 계산(유연하지만 느림)”이라는 양 끝에 놓입니다.
규모가 커지면서 MPP(Massively Parallel Processing) 어플라이언스도 등장했습니다. MPP는 데이터를 여러 노드에 분산하고 하나의 쿼리를 병렬로 실행하는 구조입니다. Teradata, Netezza, Greenplum 같은 제품은 이 방식으로 대량 집계를 빠르게 수행했습니다. 당시의 많은 시스템은 컴퓨트와 스토리지가 같은 어플라이언스에 있어, 워크로드가 바뀌어도 두 자원을 함께 계획해야 했습니다.
4. 2세대: 빅데이터와 데이터 레이크 (2006~)
2000년대 후반, 웹 규모의 비정형 데이터가 폭증하면서 정형 웨어하우스만으로는 감당하기 어려워졌습니다. 여기서 빅데이터 시대가 열립니다.
4.1. Hadoop
Hadoop은 Doug Cutting과 Mike Cafarella가 만들었고, 첫 릴리스는 2006년입니다(Cutting은 당시 Yahoo 소속). Google의 GFS/MapReduce 논문(2003~2004)에서 영향을 받아, HDFS(분산 파일 시스템) + MapReduce(분산 처리) 조합으로 commodity 하드웨어 위에서 대규모 데이터를 처리했습니다. 정형 스키마를 강제하지 않고 원본을 그대로 담을 수 있다는 점이 결정적이었습니다.
4.2. “Data Lake” 용어와 schema-on-read
“Data Lake”라는 용어는 Pentaho의 창립자 James Dixon이 2010년 블로그 글에서 데이터 마트와 대비해 사용하면서 널리 알려졌습니다. 그는 데이터 마트를 “병에 담긴 물”에, 데이터 레이크를 더 자연 상태의 큰 물 덩어리에 비유했습니다. 핵심은 미래의 분석 요구를 모두 예측하기 어렵기 때문에 원본 데이터를 보관하고, 사용 시점에 목적에 맞는 구조를 적용하자는 것입니다.
이것이 웨어하우스와 반대되는 schema-on-read입니다. 적재할 때는 스키마를 강제하지 않고, 읽는 시점에 구조를 부여합니다. 적재가 빠르고 유연한 대신, 정합성을 보장하던 게이트(적재 전 ETL/검증)를 없앤 셈이라는 점이 양날의 검입니다.
데이터 늪(data swamp) 은 schema-on-read 자체의 필연적 결과가 아니라, 카탈로그, 데이터 품질 규칙, 소유자, 보존 정책 없이 레이크를 운영할 때 생기는 실패 상태입니다. 같은 개념의 데이터가 서로 다른 컬럼명, 타입, 단위로 쌓이고 원본과 가공본의 계보가 남지 않으면, 읽는 시점에 구조를 부여할 근거도 사라집니다. 적재 단계에서 줄인 비용이 거버넌스와 발견성 문제로 이동한 셈입니다. 또한 단순 파일 묶음만으로는 여러 파일을 바꾸는 작업의 원자적 가시성이나 일관된 동시 쓰기를 제공하기 어렵습니다.
5. 클라우드 전환과 스토리지-컴퓨트 분리 (2012~)
다음 변화는 클라우드에서 왔습니다. Amazon Redshift는 관리형 클라우드 데이터 웨어하우스의 대표 서비스가 되었고, Snowflake는 SIGMOD 2016 논문에서 멀티클러스터 구조를 기술했습니다.
이 시기의 핵심 키워드는 스토리지-컴퓨트 분리(separation of storage and compute) 입니다. 이는 데이터를 저장하는 계층과 SQL을 실행하는 컴퓨트 계층의 확장 단위를 분리하는 설계입니다. Snowflake 논문은 이를 멀티클러스터, 공유 데이터 구조의 핵심 선택으로 설명합니다. 같은 데이터 위에 워크로드별 컴퓨트 클러스터를 분리하면, ETL과 BI의 자원 경합을 줄이고 각 워크로드의 크기를 독립적으로 조정할 수 있습니다.
“the key design choice behind Snowflake: separation of storage and compute.”
“We call this novel architecture the multi-cluster, shared-data architecture.”
이 분리 덕분에 같은 데이터 위에 워크로드별로 컴퓨트를 격리된 클러스터로 띄우고(예: ETL용과 BI용을 분리), 필요할 때만 탄력적으로 키우거나 0으로 줄이는 것이 가능해졌습니다. 스토리지 비용과 컴퓨트 비용을 따로 지불한다는 점도 어플라이언스 시대와 달라진 부분입니다.
같은 흐름에서 데이터 레이크의 저장 계층도 객체 스토리지로 확장되었습니다. 많은 조직이 원본은 클라우드 레이크에 두고, 그중 일부를 다운스트림 웨어하우스로 옮겨 분석하는 2계층(two-tier) 구조를 사용했습니다.
이 구조의 중복 비용이 다음 세대의 직접적인 동기가 됩니다. 메커니즘을 풀어 보면, 같은 데이터가 레이크에 한 벌, 웨어하우스에 또 한 벌 존재하므로 스토리지 비용을 이중으로 지불하게 됩니다. 두 벌을 일치시키려면 레이크에서 웨어하우스로 끊임없이 복제 파이프라인(ETL/ELT)을 돌려야 하는데, 이 파이프라인을 유지하는 엔지니어링 비용 자체가 들고, 단계가 늘수록 실패와 버그로 데이터 품질이 깨질 여지도 커집니다. 게다가 웨어하우스 쪽 데이터는 다음 적재 주기가 돌기 전까지 레이크 원본보다 오래된(stale) 상태로 남습니다. CIDR 2021 논문은 이 2계층 구조의 문제를 reliability, data staleness, total cost of ownership 등으로 정리하며, 적재 경로 자체가 복잡해졌다고 지적합니다.
“In today’s architectures, data is first ETLed into lakes, and then again ELTed into warehouses, creating complexity, delays, and new failure modes.”
“users pay double the storage cost for data copied to a warehouse”
이 중복과 복잡성, 그리고 staleness를 줄이려는 것이 레이크하우스의 출발점입니다.
6. 3세대: 테이블 포맷과 레이크하우스 (2017~2021)
2계층 구조는 같은 데이터를 레이크와 웨어하우스에 이중으로 두고 동기화해야 하는 부담이 있었습니다. 이를 풀기 위해, 레이크의 저장 위에 웨어하우스의 기능을 직접 얹으려는 시도가 나옵니다.
6.1. 오픈 테이블 포맷
그 열쇠가 오픈 테이블 포맷입니다. S3 같은 객체 스토리지의 파일 더미(Parquet/ORC) 위에 메타데이터 계층을 얹어, 파일을 “진짜 테이블”처럼 다루게 합니다.
- Apache Iceberg: Netflix에서 시작됐으며(Ryan Blue, Dan Weeks), 기존 파일 위에 atomicity, snapshot isolation, 안전한 스키마 진화를 부여합니다. 공식 정의는 거대한 분석 테이블을 위한 고성능 포맷으로, SQL 테이블의 신뢰성과 단순함을 빅데이터에 가져오는 것을 목표로 합니다.
“Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.”
- Delta Lake: Databricks가 2019년 4월 24일 Apache 2.0으로 오픈소스화했습니다. 트랜잭션 로그 기반으로 ACID 트랜잭션과 데이터 버저닝(시간여행)을 제공합니다.
- Apache Hudi: Uber에서 시작된 또 다른 테이블 포맷으로, 같은 계열의 기능을 제공합니다.
이들 덕분에 레이크에서도 ACID 트랜잭션, 스키마 진화, 시간여행, 행 단위 수정이 가능해졌습니다.
6.2. Lakehouse 개념의 정립
이 결합을 하나의 아키텍처로 정립한 것이 Databricks의 CIDR 2021 논문 「Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics」입니다. 논문은 레이크하우스를 “저비용,직접접근 스토리지 위에 ACID 트랜잭션, 데이터 버저닝, 인덱싱, 쿼리 최적화 같은 전통적 분석 DBMS 기능을 더한 시스템”으로 정의합니다.
논문은 역사를 3세대로 설명합니다. 1세대는 schema-on-write 웨어하우스, 2세대는 Hadoop/HDFS에서 시작해 클라우드 객체 스토리지로 확장된 schema-on-read 레이크와 다운스트림 웨어하우스, 3세대는 둘을 통합하려는 레이크하우스입니다. 이 글의 연표도 이 관점을 빌리되, 실제 조직은 세 방식을 오랫동안 함께 사용한다는 점을 전제로 합니다.
“Lakehouse”라는 단어 자체는 2021년 이전에도 산발적인 마케팅 용례가 있었습니다. 다만 데이터 레이크와 웨어하우스를 통합하는 아키텍처 개념을 정립한 것은 위 CIDR 2021 논문으로 보는 것이 정확합니다.
7. 또 다른 축: 스트리밍 아키텍처
지금까지가 저장 방식의 축이라면, 직교하는 축으로 처리 방식의 변화가 있습니다. 배치에서 실시간으로 넘어가는 흐름입니다.
- Lambda 아키텍처: Nathan Marz가 2011년 글에서 제시했습니다. 전체 데이터를 정확히 처리하는 batch layer와 최근 데이터를 빠르게 처리하는 speed layer를 함께 두고, batch 결과가 speed 결과를 결국 덮어쓰는 구조입니다. 정확성과 실시간성을 둘 다 잡지만, 두 계층의 로직을 따로 작성해야 하는 부담이 있습니다.
- Kappa 아키텍처: Jay Kreps가 2014년 글 「Questioning the Lambda Architecture」에서 제안했습니다. batch 계층을 없애고 단일 스트림 처리 하나로 통합합니다. 재처리가 필요하면 Kafka 같은 로그에 보관된 데이터를 처음부터 다시 흘려보내는 방식으로, 두 시스템을 따로 유지하는 복잡성을 줄입니다.
8. 또 다른 축: 조직과 거버넌스
규모가 커지면서 기술뿐 아니라 누가 데이터를 소유하고 책임지느냐도 문제가 됐습니다. 중앙 팀 하나가 모든 데이터를 책임지는 모델이 병목이 되자, 분산 거버넌스 흐름이 나옵니다.
- Data Mesh: Zhamak Dehghani(ThoughtWorks)가 2019년에 처음 제안하고 2020년 글에서 4원칙으로 정리했습니다. (1) 도메인 중심의 분산 데이터 소유(domain-oriented decentralized ownership), (2) 데이터를 product로(data as a product), (3) 셀프서비스 데이터 플랫폼(self-serve data infrastructure as a platform), (4) 연합 거버넌스(federated computational governance). 중앙집중 대신 도메인 팀이 각자의 데이터를 product로 책임지는 모델입니다.
- Data Fabric: Gartner 등이 제시한 개념으로, 메타데이터를 기반으로 흩어진 데이터를 통합 조회하는 기술 계층에 가깝습니다. Data Mesh가 조직/소유권의 분산이라면, Data Fabric은 기술/통합의 자동화라는 점에서 결이 다릅니다.
9. 최근 흐름
레이크하우스 이후로도 변화는 이어지고 있습니다. 자주 언급되는 두 가지를 짚어 둡니다.
- Medallion architecture: 레이크/레이크하우스에서 데이터를 품질 단계별로 계층화하는 패턴입니다. 원본을 그대로 받는 bronze, 정제/검증한 silver, 분석/집계용으로 가공한 gold의 3단계로 나눠, 같은 저장소 안에서 데이터를 점진적으로 다듬습니다. 동작 메커니즘은 단계마다 별도 테이블 계층을 두고 한 방향으로 흘려보내는 것입니다. bronze는 소스에서 온 그대로(append-only)라 잘못되면 재처리의 기준점이 되고, silver는 bronze를 읽어 중복 제거/타입 정리/조인을 거친 정제 테이블, gold는 silver를 읽어 BI/리포트용으로 집계한 테이블입니다. 각 단계가 직전 단계만 입력으로 삼으므로 변환 로직과 데이터 품질의 책임 경계가 단계별로 나뉘고, 문제가 생기면 어느 계층에서 깨졌는지 좁히기 쉬워집니다. 앞서 본 2계층 구조처럼 레이크와 웨어하우스를 물리적으로 분리하는 대신, 같은 레이크하우스 저장소 안에서 “일단 적재(bronze)”와 “정제된 결과(gold)”를 테이블 계층으로 잇는다는 점이 핵심 차이입니다.
- Zero-ETL: 소스와 분석 저장소 사이의 복제 파이프라인을 직접 구축하고 운영하는 부담을 줄이려는 서비스별 통합 방식입니다. 구현에 따라 변경 데이터를 관리형 통합 계층이 전파하거나, 사용자가 관리해야 할 변환과 적재 단계를 줄입니다. “ETL이 사라진다”기보다 복제와 운영 책임의 일부를 플랫폼이 맡는다는 의미에 가깝습니다. 지연 시간, 지원 소스, 변환 범위는 서비스마다 다르므로 개별 제약을 확인해야 합니다.
두 흐름 모두 앞선 변천사의 연장선에 있습니다. 정제와 적재의 경계를 더 매끄럽게 잇고, 파이프라인 운영 부담을 줄이는 방향입니다.
10. 정리
두 축으로 변천사를 요약하면 다음과 같습니다.
- 기술 축(저장/엔진): 먼저 정제(웨어하우스, schema-on-write) -> 원본도 보관(레이크, schema-on-read) -> 레이크에 테이블 기능을 더함(레이크하우스). 그 사이에 클라우드 전환과 스토리지-컴퓨트 분리가 있었습니다.
- 조직/처리 축: 배치 -> 스트리밍(Lambda/Kappa), 그리고 중앙집중 -> 분산 거버넌스(Data Mesh).
각 단계는 직전 방식의 한계를 풀면서 등장했습니다. 웨어하우스의 경직성을 레이크가, 레이크의 통제 부재를 레이크하우스가, 중앙 병목을 데이터 메시가 풀어 온 흐름입니다. 새 패러다임이 옛 것을 완전히 대체했다기보다, 각자의 트레이드오프를 이해하고 상황에 맞게 선택하거나 함께 쓰는 것이 현실적인 접근입니다.
AWS 스택에서 이 흐름이 어떤 서비스로 구현되는지는 이 시리즈의 이어지는 글들에서 다룹니다.
11. Reference
- James Dixon - Pentaho, Hadoop, and Data Lakes (2010)
- Apache Hadoop - Releases
- Amazon Redshift - ten years of continuous reinvention
- Dageville et al. - The Snowflake Elastic Data Warehouse (SIGMOD 2016)
- Apache Iceberg
- Databricks - Open Sourcing Delta Lake (2019)
- Lakehouse: A New Generation of Open Platforms (CIDR 2021)
- Zhamak Dehghani - Data Mesh Principles (2020)
- Jay Kreps - Questioning the Lambda Architecture (2014)
- Databricks - What is a Medallion Architecture?
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi