프로세스 메모리 레이아웃과 stack vs heap

Series 1에서 “요청이 흐르는 길”을 위에서 아래로 따라왔고, 3편에서 “스레드 스택은 힙이 아니라 native 메모리”라고 했습니다. 이번 편에서는 그때 흘려보낸 stack과 heap이 각각 무엇이고 어떻게 다른지를 프로세스 메모리 레이아웃 관점에서 정리합니다.
Series 2는 한 계층 더 내려가 JVM과 메모리를 다룹니다. 그 첫걸음으로, JVM 이야기를 하기 전에 까먹기 쉬운 CS 기초 - 프로세스가 메모리를 어떻게 쓰는가부터 다시 잡습니다. JVM 메모리(다음 편)도 결국 이 위에 얹히기 때문입니다.
TL;DR
- 프로세스는 자기만의 가상 주소공간을 가지며, 용도별로 text(code) / data / bss / heap / stack 구역으로 나뉜다.
- stack: 함수 호출마다 프레임이 쌓이는 자동/LIFO 영역. 스레드마다 하나씩. 빠르고, 함수가 끝나면 자동 해제.
- heap:
new로 동적 할당하는 공유 영역. 느리고, 참조가 살아있는 동안 유지(해제는 수동 또는 GC).- 레이아웃과 성장 방향은 표준이 아니라 관례(x86 기준) 이며 아키텍처/OS마다 다르다.
1. 프로세스의 가상 주소공간
프로그램이 실행되면 OS는 그 프로세스에게 자기만의 가상 주소공간을 줍니다. 각 프로세스는 “나 혼자 이 메모리를 다 쓴다”고 보고, 실제 물리 RAM 매핑과 프로세스 간 격리는 OS와 MMU가 처리합니다.
그 공간은 용도별 구역으로 나뉩니다.
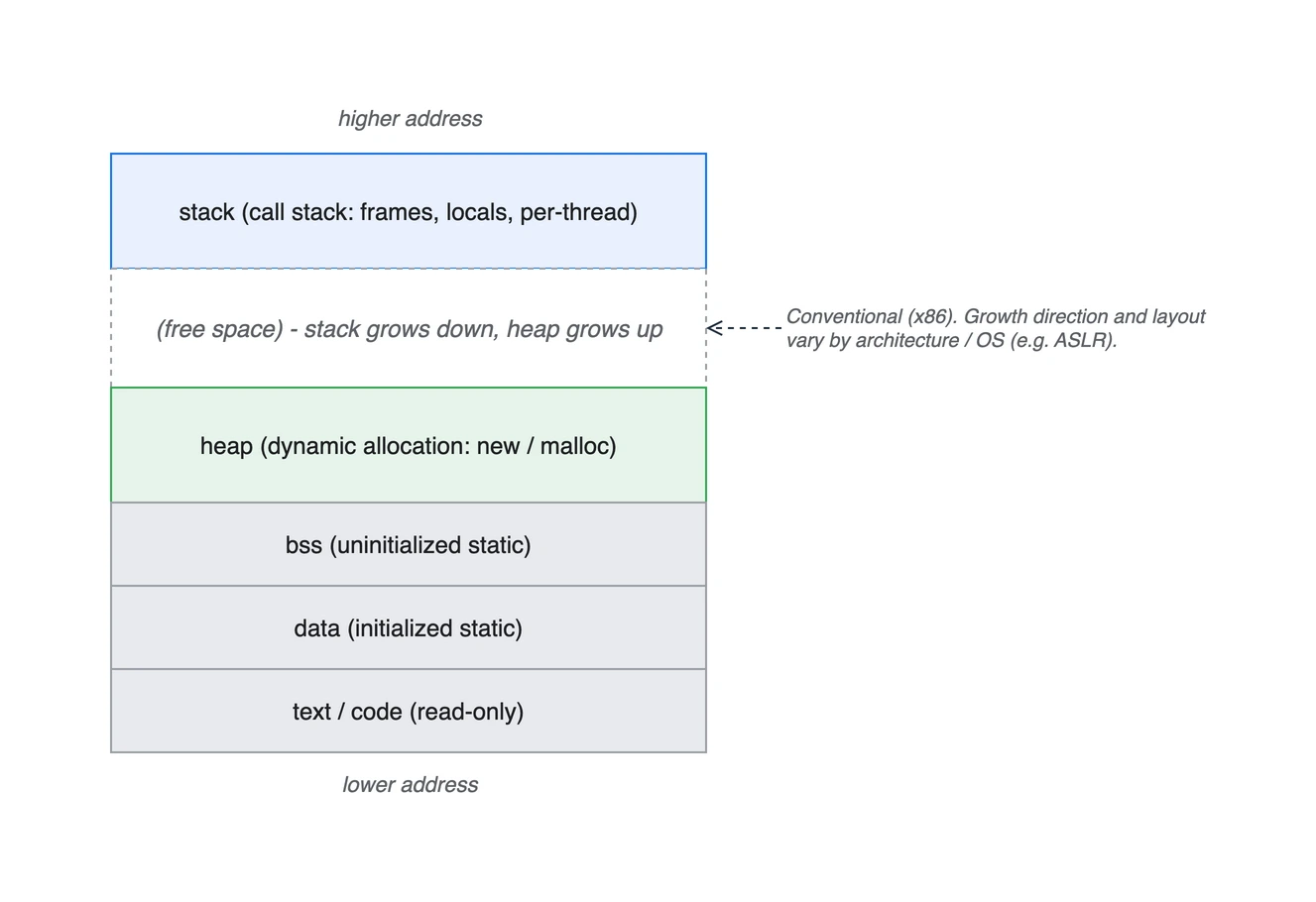 프로세스 가상 주소공간 (x86 기준 관례)
프로세스 가상 주소공간 (x86 기준 관례)
각 구역을 위키피디아 정의로 정리하면:
- text / code: “executable code and is generally read-only and fixed size” (프로그램 명령어, 읽기 전용)
- data: “initialized static variables … can be modified” (초기화된 전역/static)
- bss: “uninitialized static data” (초기화 안 된 전역/static)
- heap: “dynamically allocated memory, commonly begins at the end of the BSS segment and grows to larger addresses” (동적 할당, 위로 자람)
- stack: “the call stack, a LIFO structure, typically located in the higher parts of memory” (호출 스택, 위쪽)
data와 bss를 따로 두는 이유는 디스크에 저장되는 실행 파일 크기와 직결됩니다. data는 초기값을 그대로 들고 있어야 하므로 파일 안에 실제 바이트가 들어가지만, bss는 0으로 시작하는 변수라 값을 저장할 필요가 없고 “런타임에 이만큼 0으로 채워라”는 크기 정보만 기록됩니다. 위키피디아도 같은 구분을 명시합니다.
The size that BSS will require at runtime is recorded in the object file, but BSS (unlike the data segment) doesn’t take up any actual space in the object file.
즉 int table[1000000]; 처럼 큰 배열을 0 초기화로 선언하면 bss에 들어가 실행 파일이 거의 커지지 않지만, 같은 배열을 0이 아닌 값으로 초기화하면 data로 가서 그 값들이 통째로 파일에 박힙니다.
주의: 두 가지를 분리해서 봐야 합니다. (1) 성장 방향은 표준이 아니라 관례입니다. x86에서는 stack이 낮은 주소(heap 쪽)로 자라지만, 위키피디아도 “on some other architectures it grows the opposite direction”이라고 명시합니다. (2) 시작 위치(base) 는 ASLR이 매 실행마다 무작위화합니다. ASLR은 “the address space positions of key data areas of a process, including the base of the executable and the positions of the stack, heap and libraries”를 randomize하는 보안 기법으로, 어느 주소에서 시작하는지를 흔들 뿐 stack이 자라는 방향 자체를 바꾸지는 않습니다. 즉 ASLR이 걸려 있어도 “stack은 높은 주소에서 아래로, heap은 낮은 주소에서 위로”라는 상대적 배치 관례는 그대로입니다.
이번 편의 주인공은 이 중 stack과 heap입니다.
2. Stack: 자동, 빠름, 스레드별
함수를 호출할 때마다 그 함수용 스택 프레임(stack frame) 이 stack에 쌓입니다. 프레임에는 지역변수, 파라미터, 복귀 주소 등이 담깁니다.
1
2
3
4
5
6
process() 호출
-> process 프레임 push
calc() 호출
-> calc 프레임 push
-> calc 끝 -> calc 프레임 pop (자동 해제)
-> process 끝 -> process 프레임 pop
특징:
- 스레드마다 자기 stack을 가진다 (Series 1 3편의 “스레드 스택”이 바로 이것).
- LIFO + 자동: 함수가 끝나면 프레임이 그냥 pop된다. 직접 해제하지 않는다.
- 빠르다: 할당이 스택 포인터를 옮기는 것뿐이라 탐색도 GC도 없다.
- 크기 제한: 정해진 한도가 있어 재귀가 너무 깊으면 stack overflow.
- 수명: 그 함수 호출 동안만.
크기 제한은 코드로 바로 재현됩니다. 종료 조건 없는 재귀는 프레임을 끝없이 push하다 한도를 넘기는 순간 터집니다.
1
2
3
4
5
6
7
static int recurse(int depth) {
return recurse(depth + 1); // 복귀 없이 프레임만 계속 push
}
public static void main(String[] args) {
System.out.println(recurse(0)); // Exception: java.lang.StackOverflowError
}
각 호출마다 지역변수와 복귀 주소를 담은 프레임이 쌓이는데, 이 프레임들이 스레드 stack 한도를 초과하면 JVM은 더 push할 공간이 없어 StackOverflowError를 던집니다. heap이 부족할 때의 OutOfMemoryError와는 발생 영역이 다릅니다.
3. Heap: 동적, 공유, 느림
new(Java) 또는 malloc(C)으로 실행 중에 동적으로 할당하는 영역입니다.
특징:
- 공유: 모든 스레드가 접근할 수 있다.
- 동적이고 오래 산다: 만든 함수가 끝나도 객체는 참조가 있는 한 heap에 남는다.
- 해제: C는 수동(
free), Java는 GC가 회수한다 (Series 2 뒤쪽 편 주제). - 느리다(단, 조건부): 할당기가 빈 블록을 찾고 장부를 관리해야 하며, 조각화(fragmentation)가 생길 수 있다.
- 수명: 참조가 살아있는 동안.
다만 “heap 할당은 느리다”를 일반 원칙으로 굳히면 JVM에서는 어긋납니다. JVM heap은 공유 영역이지만, 매 객체마다 전체 heap에 락을 거는 방식이 아니라 스레드마다 heap 한 조각을 미리 떼어 주는 TLAB(Thread-Local Allocation Buffer) 기법을 씁니다. 그 조각 안에서는 포인터만 옮겨(bump-the-pointer) 객체를 잡으므로 stack 할당에 가깝게 빠릅니다.
Small objects are allocated in thread local areas (TLAs). The thread local areas are free chunks reserved from the heap and given to a Java thread for exclusive use. The thread can then allocate objects in its TLA without synchronizing with other threads.
스레드가 자기 TLAB를 다 쓰면 그때만 새 조각을 heap에서 받아 가므로, 스레드 간 동기화 비용은 객체 단위가 아니라 버퍼 보충 단위로 줄어듭니다. “heap이 느리다”는 락 경합이나 조각화가 실제로 발생할 때의 상대적 비용이지, 모든 할당이 항상 느리다는 뜻은 아닙니다.
4. Stack vs Heap 한눈에
1
2
3
4
5
6
7
void process() {
int count = 10; // stack: 지역 변수(원시값)
Order order = new Order(); // 'order' 참조는 stack, new Order() 객체는 heap
}
// process() 가 끝나면:
// count, order(참조) -> stack 프레임과 함께 사라짐
// Order 객체 -> heap 에 남음 (GC 가 회수할 때까지)
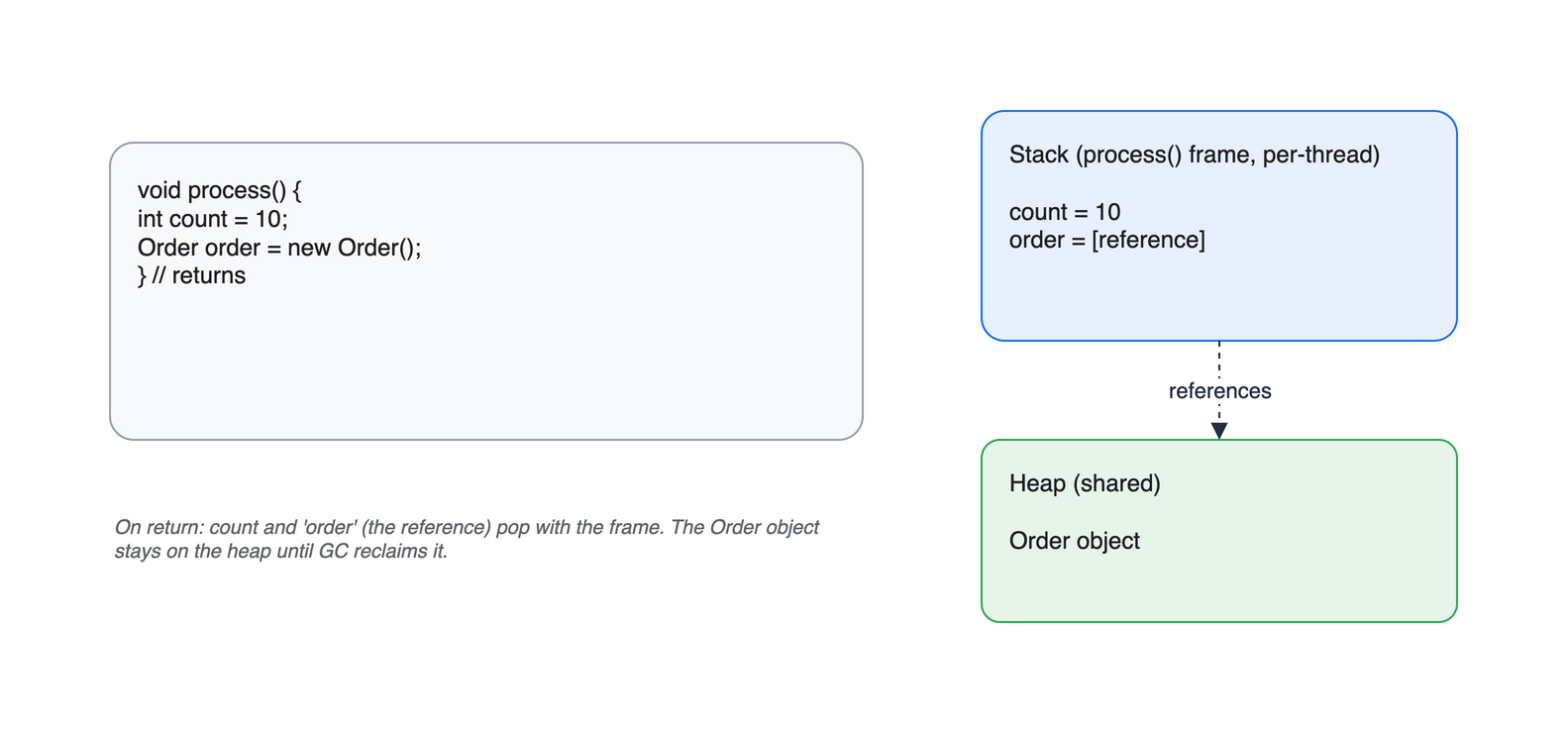 참조(order)는 stack 프레임에, 객체(Order)는 heap에
참조(order)는 stack 프레임에, 객체(Order)는 heap에
| Stack | Heap | |
|---|---|---|
| 할당/해제 | 자동(프레임 push/pop) | 동적(new) / GC, free |
| 소유 | 스레드별 | 전체 공유 |
| 속도 | 빠름(포인터 이동) | 느릴 수 있음(탐색/장부/조각화, 단 JVM은 TLAB로 완화) |
| 담는 것 | 지역변수, 참조, 프레임 | 동적 객체 |
| 수명 | 함수 호출 동안 | 참조 살아있는 동안 |
5. JVM, 그리고 Series 1과의 연결
- Series 1 3편의 “스레드 스택 = native 메모리”가 바로 여기 그 stack입니다. JVM 프로세스 안에서 스레드마다 하나씩 잡히고, JVM heap(
-Xmx) 바깥의 native 영역입니다. - Java의
new객체가 사는 곳이 여기 그 heap인데, JVM에서는 GC가 관리하는 특수한 heap입니다.
capstone 복선: 컨테이너 메모리는 이 stack(스레드별 native) + heap + 기타를 모두 포함합니다. “왜
-Xmx만 보면 안 되나”의 뿌리가 이 레이아웃입니다.
다음 편에서는 JVM이 이 일반 레이아웃을 어떻게 구체화하는지 - heap을 young/old로 쪼개고, metaspace와 스레드 스택은 native에 두고, direct(off-heap)까지 - 를 매핑합니다.
6. 참고 자료
- Wikipedia - Data segment (text / data / bss / heap / stack): https://en.wikipedia.org/wiki/Data_segment
- Wikipedia - .bss (실행 파일에서 차지하는 공간): https://en.wikipedia.org/wiki/.bss
- Wikipedia - Address space layout randomization (ASLR base randomization): https://en.wikipedia.org/wiki/Address_space_layout_randomization
- Oracle - JRockit JVM Diagnostics Guide, Thread Local Areas (TLA로 동기화 없이 할당): https://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/geninfo/diagnos/garbage_collect.html
- 추가 읽을거리: Operating Systems - Three Easy Pieces (OSTEP), Address Spaces: https://pages.cs.wisc.edu/~remzi/OSTEP/
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi