Spring Boot HTTP 요청 처리 흐름 개요

인프라를 다루다 보면 애플리케이션은 “컨테이너 안에서 도는 검은 상자”처럼 보일 때가 많습니다. GET /orders/42 요청 하나가 들어오면 그 안에서 무슨 일이 벌어지는지, 왜 요청이 몰리면 스레드와 메모리가 같이 올라가는지 설명하려면 결국 그 상자를 열어봐야 합니다.
이 글은 Spring/JVM 백엔드 학습 시리즈의 첫 편으로, 깊이 들어가기 전에 요청 한 건이 Spring Boot 앱을 통과하는 전체 경로를 계층별로 한 번 그려봅니다. 각 부품의 내부 해부는 뒤 편에서 다루고, 여기서는 “전체 지도”와 핵심 감각 두 가지를 잡는 게 목표입니다.
TL;DR
- Spring Boot 앱은 “톰캣 위에 올리는 war”가 아니라, 톰캣을 부품으로 삼킨 단일 실행 프로세스(
java -jar)다.- 모든 요청은 DispatcherServlet 하나(front controller) 를 먼저 거친 뒤 알맞은 컨트롤러로 분배된다.
- Spring MVC는 요청당 워커 스레드 1개를 점유하는 모델이다. 이게 트래픽-스레드-메모리 관계의 출발점이다.
1. 요청 한 건의 여정: 30초 요약
한 문장으로 요약하면 이렇습니다.
클라이언트가 보낸 HTTP 요청이 JVM 프로세스 안에 내장된 웹서버(Tomcat) 로 들어와 -> 워커 스레드 하나를 배정받고 -> DispatcherServlet(앱 내부 라우터) 이 알맞은 컨트롤러로 넘기고 -> 비즈니스 로직 실행 후 -> JSON으로 직렬화돼 응답으로 나간다. 그동안 그 워커 스레드 1개는 요청이 끝날 때까지 묶여 있다.
그림으로 보면 다음과 같습니다.
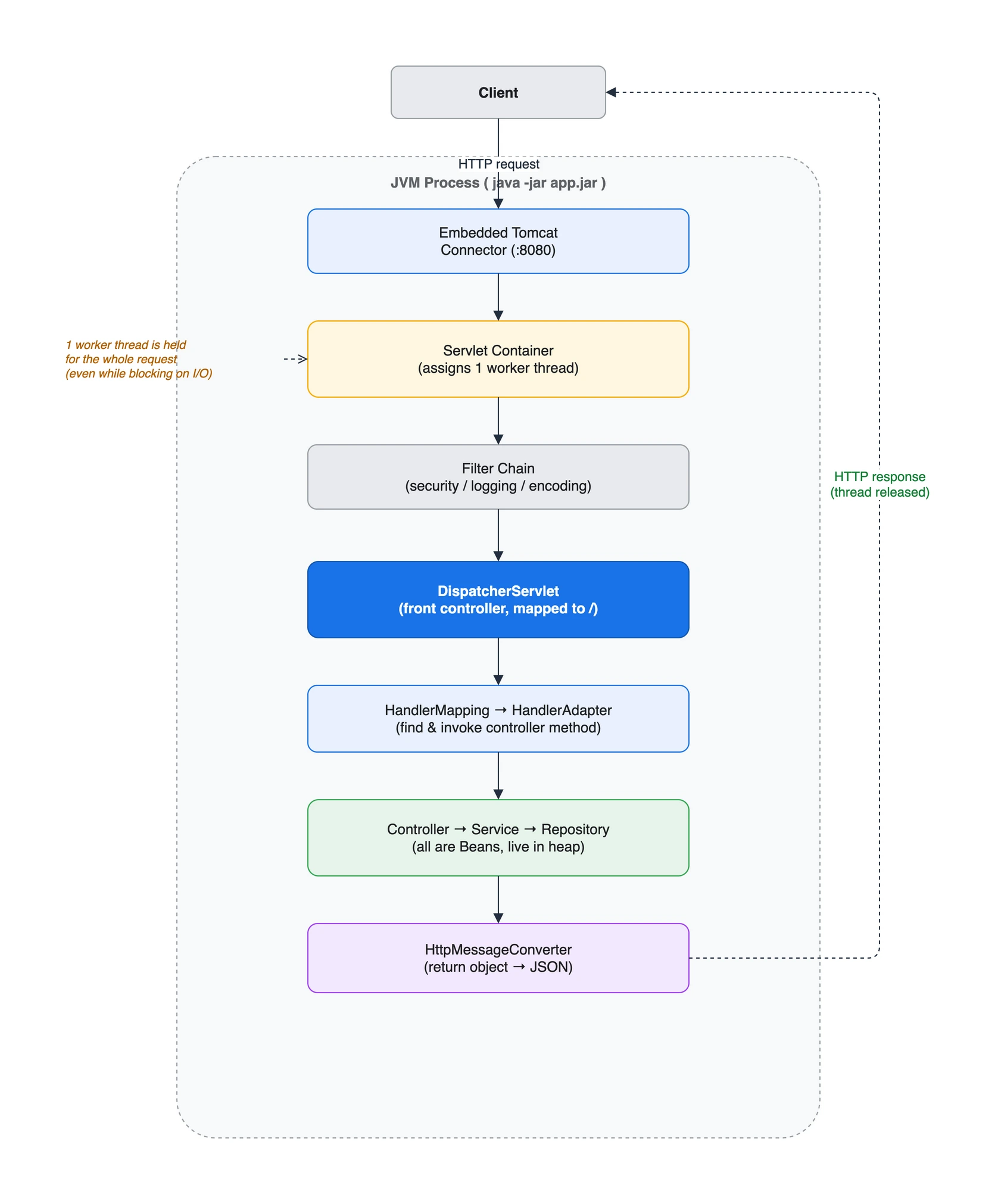 요청 한 건이 JVM 프로세스 안에서 계층을 통과하는 경로
요청 한 건이 JVM 프로세스 안에서 계층을 통과하는 경로
2. 핵심 통찰 1: Spring Boot 앱은 “톰캣을 품은 단일 프로세스”
가장 먼저 깨야 할 통념은 톰캣과 앱의 관계입니다.
예전(전통적) 방식 - 서버와 앱이 분리
1
2
3
4
5
[서버 머신]
└─ Tomcat (독립 프로세스, 따로 설치/운영)
├─ webapps/order.war (앱 A)
├─ webapps/user.war (앱 B)
└─ webapps/catalog.war (앱 C)
Tomcat을 별도로 설치하고, 내 앱은 .war로 빌드해 Tomcat의 webapps/에 떨어뜨립니다. Tomcat 프로세스 하나가 여러 war 앱을 호스팅하고, Tomcat의 생명주기는 내 앱과 별개로 굴러갑니다.
Spring Boot 방식 - 앱이 서버를 품음
1
2
3
4
5
[컨테이너 / 파드]
└─ java -jar app.jar (OS 프로세스 1개 = JVM 1개)
└─ 내 코드가 부팅하며 Tomcat을 "객체로" 띄운다
- Tomcat = 라이브러리(jar 의존성). 스레드 몇 개로 프로세스 안에 존재
- 내 앱은 단 하나
spring-boot-starter-web 의존성이 내장 Tomcat을 끌고 오고, java -jar app.jar 한 줄이면 OS 프로세스 하나가 떠서 그 안에서 코드가 Tomcat을 객체처럼 생성해 포트를 엽니다. 즉 1 jar = 1 프로세스 = 1 JVM = 1 내장 톰캣 = 1 앱입니다.
“톰캣이 내 앱을 담는 그릇”이 아니라, “내 앱이 톰캣을 부품으로 삼킨 단일 실행체” 입니다.
이게 운영 관점에서 중요한 이유:
- 컨테이너 = 프로세스: 이미지에 JRE와 jar만 있으면 되고,
docker run하면 그게 곧 그 프로세스다. 파드 1개 = 프로세스 1개 = 앱 1개. - 메모리 경계가 그 프로세스 하나: JVM 힙, 톰캣 스레드풀, off-heap이 전부 이 단일 프로세스 메모리 안에 있다. 컨테이너 memory limit을 잡는다는 건 이 프로세스 하나를 sizing하는 것이다.
- 스케일 = 인스턴스를 더 띄우기(파드 늘리기)지, “큰 톰캣에 war를 더 얹기”가 아니다.
3. 핵심 통찰 2: DispatcherServlet은 모든 요청의 단일 관문(front controller)
두 번째 통찰은 요청이 앱 안에서 어떻게 분배되는가입니다.
서블릿(Servlet)은 “특정 URL로 온 요청을 처리하는 Java 객체”입니다. front controller 패턴이 없던 시절에는 URL마다 서블릿을 따로 만들어 매핑했습니다.
1
2
3
4
5
GET /login -> LoginServlet
GET /order -> OrderServlet
GET /users -> UserServlet
(요청 종류마다 서블릿을 만들고 URL을 일일이 매핑)
문제: 인증/로깅/JSON 변환 같은 공통 처리가 서블릿마다 중복/분산됨
Spring MVC는 대신 단 하나의 서블릿(DispatcherServlet) 이 / 즉 모든 요청을 받습니다. 받은 뒤 요청을 보고 알맞은 핸들러(@Controller 메서드)로 넘깁니다(dispatch). 그래서 이름이 dispatcher이고, 모든 처리의 맨 앞단에 선다는 뜻에서 front controller입니다.
1
2
3
GET /login ┐
GET /order ├──> DispatcherServlet ──> (내부에서) 알맞은 @Controller 메서드로 dispatch
GET /users ┘ (URL "/" 전부를 받는 단 1개의 서블릿)
Spring 공식 레퍼런스도 이를 그대로 정의합니다.
Spring MVC, as many other web frameworks, is designed around the front controller pattern where a central Servlet, the DispatcherServlet, provides a shared algorithm for request processing, while actual work is performed by configurable delegate components.
덕분에 우리가 작성하는 @Controller는 서블릿이 아니라 그냥 메서드가 됩니다. 서블릿스러운 저수준 작업은 DispatcherServlet이 대신 해줍니다.
참고로 plain Spring에서는 이 DispatcherServlet을 개발자가 직접 등록(
WebApplicationInitializer)하지만, Spring Boot에서는 자동 등록(DispatcherServletAutoConfiguration)하고 기본적으로/에 매핑합니다. “Boot라서 서블릿을 직접 등록하지 않는다”는 점도 함께 기억해 두면 4편(자동설정)으로 자연스럽게 이어집니다.
DevSecOps 관점 비유로는, Ingress Controller나 API Gateway 한 개가 모든 외부 요청을 먼저 받아 뒤 서비스로 라우팅하는 구조와 같습니다. 다만 그게 앱 프로세스 안에서 in-process 컨트롤러 메서드로 라우팅되는 버전인 셈입니다.
4. 계층별로 따라가기
위 다이어그램의 각 박스를 순서대로 짚으면 다음과 같습니다.
- Embedded Tomcat - Connector (:8080): TCP 연결을 수락하고 HTTP를 파싱한다.
- Servlet Container: 스레드풀에서 워커 스레드 1개를 배정하고, 요청/응답을
HttpServletRequest/HttpServletResponse객체로 감싼다. - Filter Chain: 앱 코드 진입 전 관문. 보안, 로깅, 인코딩 같은 공통 처리가 여기서 일어난다.
- DispatcherServlet: front controller. 요청을 받아 처리 흐름을 조율한다.
- HandlerMapping -> HandlerAdapter: 이 URL을 처리할
@Controller메서드를 찾고(mapping), 파라미터를 바인딩해 호출한다(adapter). - Controller -> Service -> Repository: 실제 비즈니스 로직과 데이터 접근. 이들은 모두 “빈(Bean)”으로, 시작 시 한 개씩 만들어져 힙에 상주한다(2편 주제).
- HttpMessageConverter: 컨트롤러가 반환한 객체를 JSON 등으로 직렬화해 응답으로 내보낸다.
4번 박스인 DispatcherServlet은 핸들러를 찾기 전에 매 요청마다 정해진 준비 작업을 거칩니다. WebApplicationContext를 요청 속성으로 바인딩해 이후 단계가 빈에 접근할 수 있게 하고, locale resolver와 (설정돼 있다면) multipart resolver를 적용한 뒤, 그제서야 알맞은 핸들러를 탐색합니다. Spring 공식 레퍼런스의 처리 순서가 이를 그대로 기술합니다.
The
WebApplicationContextis searched for and bound in the request as an attribute that the controller and other elements in the process can use. It is bound by default under theDispatcherServlet.WEB_APPLICATION_CONTEXT_ATTRIBUTEkey.
…
An appropriate handler is searched for. If a handler is found, the execution chain associated with the handler (preprocessors, postprocessors, and controllers) is run to prepare a model for rendering.
즉 5번의 HandlerMapping -> HandlerAdapter는 이 준비가 끝난 다음에 실행되는 단계이고, REST 컨트롤러라면 뷰를 렌더링하는 대신 HandlerAdapter 안에서 응답을 직접 만들어(7번 HttpMessageConverter) 내보냅니다. 이 안을 더 파고드는 건 3편(DispatcherServlet 해부)에서 다룹니다.
응답은 역순으로 필터를 통과해 톰캣이 HTTP 응답을 써 보내고, 그제서야 워커 스레드가 풀로 반납됩니다.
핵심: 워커 스레드 하나가 요청 처리 시작부터 끝까지 점유됩니다. DB 응답을 기다리는 블로킹 구간에도 그 스레드는 놀면서 묶여 있습니다. 이 점이 3편(thread-per-request)과 capstone의 메모리 이야기로 이어집니다.
5. 용어 지도
이번 편에서 던진 용어들과, 각각을 깊게 다루는 편을 미리 표로 정리합니다.
| 용어 | 한 줄 정의 | 깊게 다루는 편 |
|---|---|---|
| 내장 서버(embedded server) | 앱이 부품으로 품은 웹서버(Tomcat) | 4편 |
| 서블릿 / 서블릿 컨테이너 | HTTP를 Java 객체로 다루는 표준 / 그 런타임 | 3편 |
| Filter | 앱 코드 진입 전 공통 관문(보안/로깅) | 3편 |
| DispatcherServlet | 모든 요청의 단일 진입 라우터(front controller) | 3편 |
| HandlerMapping / HandlerAdapter | URL과 메서드 매칭 / 메서드 호출 | 3편 |
| Bean / IoC 컨테이너 | 컨테이너가 만들어 관리하는 객체 | 2편 |
| thread-per-request | 요청당 워커 스레드 1개 점유 | 3편 |
| Netty | WebFlux의 내장 서버(Tomcat의 비동기 짝). off-heap direct memory를 적극 사용 | WebFlux/Netty |
6. 이 시리즈를 읽는 순서
이 글은 큰 그림이자 시리즈 전체의 reading-order map 역할도 합니다. 탑다운으로 “눈에 보이는 요청 흐름”에서 시작해 점점 아래 계층(JVM, 메모리)으로 내려가고, 마지막에 실제 운영 이슈를 capstone으로 회수합니다.
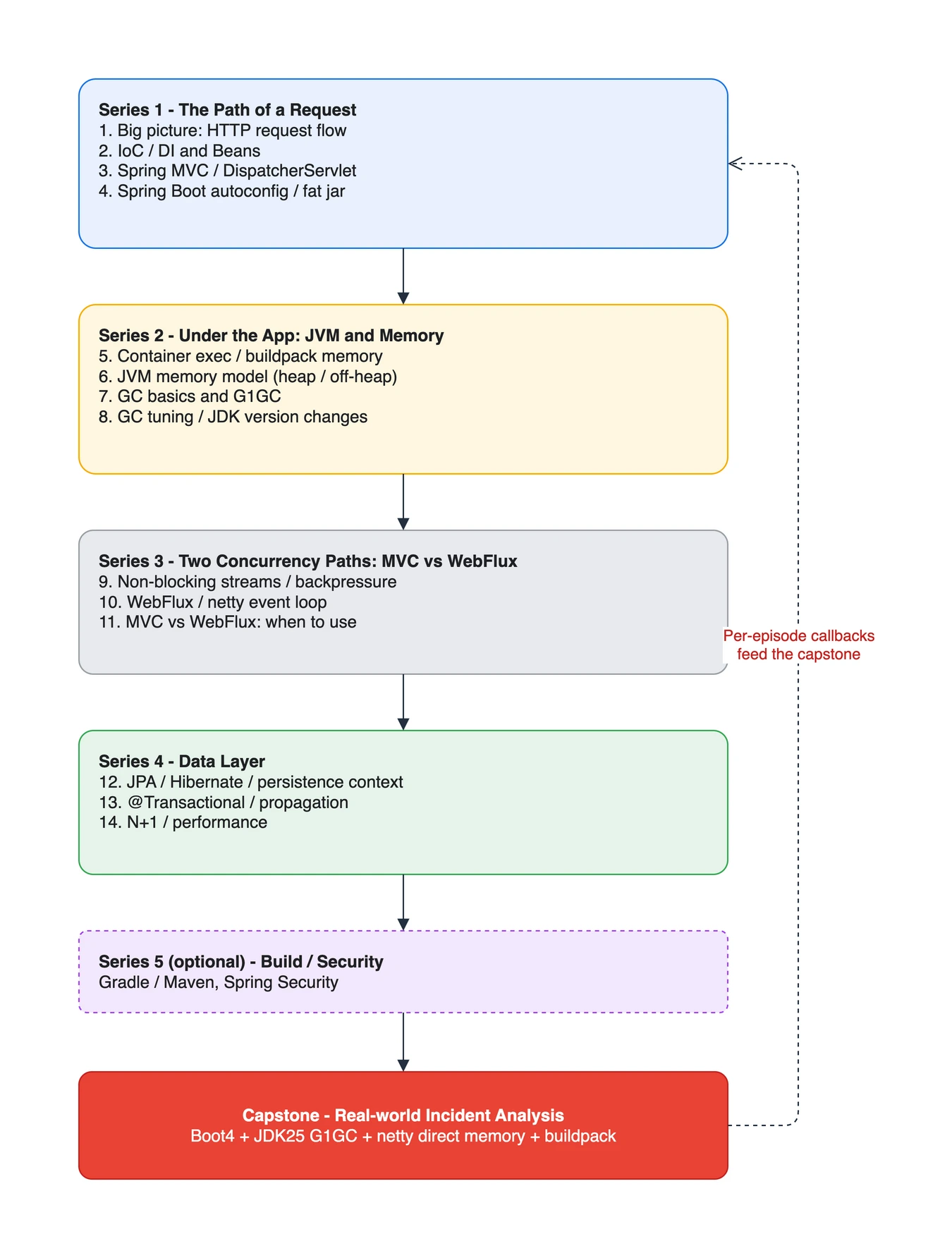 탑다운 학습 경로: 요청 흐름에서 시작해 JVM/메모리로 내려가고 capstone으로 회수
탑다운 학습 경로: 요청 흐름에서 시작해 JVM/메모리로 내려가고 capstone으로 회수
7. 마무리
이번 편에서 잡아야 할 두 감각은 (1) Spring Boot 앱 = 톰캣을 품은 단일 프로세스, (2) 모든 요청은 DispatcherServlet 하나를 먼저 거친다는 것입니다. 그리고 “요청 1개 = 워커 스레드 1개”라는 모델은 앞으로 메모리와 동시성을 이해하는 출발점이 됩니다.
다음 편(IoC/DI와 Bean)에서는 6번 박스에서 잠깐 언급한 “빈(Bean)”으로 들어갑니다. Spring이 왜 객체를 직접 만들지 않고 컨테이너에 맡기는지(IoC/DI), 그리고 그 빈들이 어떻게 힙에 상주하는지를 다룹니다.
8. 참고 자료
- Spring Framework Reference - Web MVC, DispatcherServlet: https://docs.spring.io/spring-framework/reference/web/webmvc/mvc-servlet.html
- Spring Framework Reference - DispatcherServlet 요청 처리 순서(Sequence): https://docs.spring.io/spring-framework/reference/web/webmvc/mvc-servlet/sequence.html
- Spring Boot Reference - Running your application (
java -jar): https://docs.spring.io/spring-boot/reference/using/running-your-application.html - Spring Boot - Executable jar structure(BOOT-INF): https://docs.spring.io/spring-boot/how-to/build.html
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi