Spring WebFlux와 netty event loop - 적은 스레드, 그리고 off-heap 메모리

Series 3 1편에서 리액티브는 “블로킹을 하지 않는다”는 데까지 봤습니다. 그런데 블로킹을 하지 않으면 서버 스레드는 구체적으로 어떻게 동작할까요. “적은 스레드로 많은 요청을 처리한다”는 말의 실체는 무엇이고, netty가 쓰는 메모리는 왜 JVM 힙 바깥(off-heap)에 있을까요. 이번 글에서는 Spring WebFlux의 실행 모델인 event loop와 netty의 direct memory를 살펴봅니다. 앞의 Series 1 3편 thread-per-request와 Series 2의 JVM 메모리 구조가 여기서 다시 만납니다.
TL;DR
- Spring WebFlux의 기본 서버는 Netty이고, thread-per-request가 아니라 event loop 모델로 동작한다.
- 적은 수의 고정 스레드(보통 CPU 코어 수)가 다수 커넥션을 논블로킹으로 번갈아 처리한다. 절대 막지 않으니 요청마다 스레드를 늘릴 필요가 없다.
- 황금률: event loop를 블로킹하지 마라. 블로킹 라이브러리는
publishOn/boundedElastic로 다른 스레드에 격리한다.- netty는 소켓 I/O에 direct memory(off-heap) 버퍼를 쓴다. 힙 바깥이라 GC 관리 밖이고 native I/O에서 복사를 줄인다. 이게 Series 2 off-heap / 컨테이너 메모리 > -Xmx와 직결된다.
1. 복습과 질문: 블로킹을 안 하면 스레드는 어떻게 도는가
Series 1 3편의 Spring MVC는 thread-per-request였습니다. 요청 하나에 워커 스레드 하나가 붙고, DB 조회나 외부 호출 같은 I/O를 기다리는 동안에도 그 스레드는 그대로 점유됩니다. 동시 요청이 200개면 워커 스레드도 약 200개가 필요하고, 그 대부분은 “아무 일도 안 하면서 결과를 기다리는” 상태입니다.
Series 3 1편에서는 그 반대 모델을 봤습니다. 리액티브는 “조회하면 이렇게 처리하라”는 파이프라인을 선언할 뿐이고, subscribe() 전에는 아무것도 흐르지 않으며, I/O를 기다리며 스레드를 붙잡지 않습니다.
그렇다면 자연스러운 질문이 생깁니다. 블로킹을 하지 않으면 서버는 스레드를 몇 개나 쓸까요. 요청이 많아질 때 스레드도 같이 늘어날까요. 이번 글은 이 질문에 답하는 WebFlux의 실행 모델을 다룹니다.
2. WebFlux는 무엇 위에서 도는가 - 기본 서버 Netty
Spring WebFlux는 Spring의 논블로킹 리액티브 웹 스택입니다. Servlet(동기 블로킹) 기반인 Spring MVC와는 별개의 스택이고, 기본 서버부터 다릅니다. WebFlux의 기본 서버는 Netty입니다.
Spring Boot defaults to Netty, because it is more widely used in the asynchronous, non-blocking space and lets a client and a server share resources.
- Spring Framework Reference, Servers
Netty는 자바의 비동기 이벤트 기반 네트워크 프레임워크입니다. 소켓에서 데이터가 도착하는 등의 이벤트가 발생하면 콜백을 호출하는 방식으로 동작하며, WebFlux는 이 위에서 HTTP 요청을 논블로킹으로 처리합니다. Tomcat이나 Jetty 위에서도 WebFlux를 띄울 수는 있지만, 기본이자 권장 조합은 Netty입니다.
It is strongly advised not to map Servlet filters or directly manipulate the Servlet API in the context of a WebFlux application. For the reasons listed above, mixing blocking I/O and non-blocking I/O in the same context will cause runtime issues.
- Spring Framework Reference
즉 WebFlux는 단순히 “MVC에 리액티브 타입만 얹은 것”이 아니라, 논블로킹 서버 위에서 도는 별도의 실행 모델입니다. 그 핵심이 다음 절의 event loop입니다.
3. event loop 스레딩 모델 - 적은 스레드로 많은 요청
1절의 질문에 대한 답입니다. WebFlux 서버의 요청 처리 스레드 수는 동시 요청 수가 아니라 CPU 코어 수에 비례합니다.
On a “vanilla” Spring WebFlux server (for example, no data access or other optional dependencies), you can expect one thread for the server and several others for request processing (typically as many as the number of CPU cores).
- Spring Framework Reference, Threading Model
이 적은 수의 스레드를 event loop worker라고 부릅니다. WebFlux는 애플리케이션이 블로킹하지 않는다고 가정하기 때문에, 요청마다 스레드를 만드는 대신 작고 고정된 스레드 풀로 모든 요청을 처리합니다.
In Spring WebFlux (and non-blocking servers in general), it is assumed that applications do not block. Therefore, non-blocking servers use a small, fixed-size thread pool (event loop workers) to handle requests.
- Spring Framework Reference, Threading Model
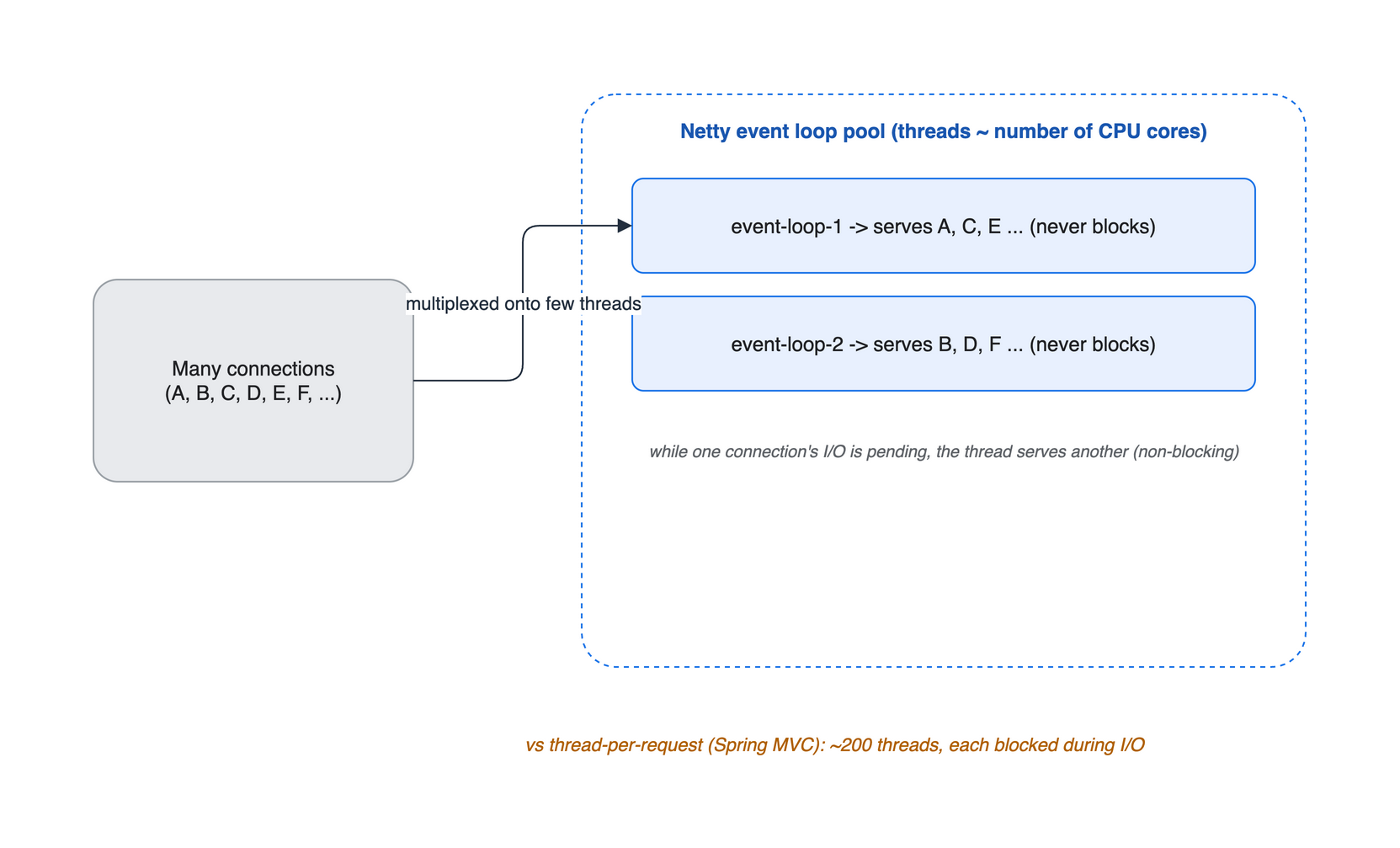 event loop 스레드 수는 CPU 코어 수 수준. 한 커넥션의 I/O가 진행 중이면 같은 스레드가 다른 커넥션을 처리한다(never blocks). thread-per-request(MVC)는 요청당 스레드가 I/O 동안 묶인다.
event loop 스레드 수는 CPU 코어 수 수준. 한 커넥션의 I/O가 진행 중이면 같은 스레드가 다른 커넥션을 처리한다(never blocks). thread-per-request(MVC)는 요청당 스레드가 I/O 동안 묶인다.
핵심은 다중화(multiplexing)입니다. event loop 스레드는 어떤 커넥션의 I/O 응답을 기다리는 동안 그 자리에서 멈추지 않고, 준비된 다른 커넥션의 일을 처리합니다. 블로킹이 없으니 스레드가 노는 시간이 없고, 그래서 적은 스레드로도 수많은 커넥션을 감당할 수 있습니다.
“To scale” and “small number of threads” may sound contradictory, but to never block the current thread (and rely on callbacks instead) means that you do not need extra threads, as there are no blocking calls to absorb.
- Spring Framework Reference, Concurrency Model
그런데 적은 스레드가 빠른 생산자(예: 대량 응답을 쏟아내는 업스트림)를 만나면, 소비 속도보다 데이터가 빨리 밀려들 위험이 있습니다. 이 흐름을 제어하는 장치가 Reactive Streams의 backpressure입니다. 구독자(downstream)는 자신이 처리할 수 있는 만큼만 request(n)으로 요구하고, 생산자(upstream)는 그 요구량을 넘겨 밀어내지 않습니다.
A subscriber can work in unbounded mode and let the source push all the data at its fastest achievable rate or it can use the
requestmechanism to signal the source that it is ready to process at mostnelements.
- Reactor Reference, Reactive Programming
이 요구 신호는 체인을 따라 위로 전파됩니다. 즉 가장 아래쪽 소비자가 느리면 그 압력이 단계를 거슬러 올라가 맨 위 생산자의 생산 속도까지 조절합니다.
Propagating signals upstream is also used to implement backpressure, which we described in the assembly line analogy as a feedback signal sent up the line when a workstation processes more slowly than an upstream workstation.
- Reactor Reference, Reactive Programming
덕분에 event loop는 무한정 쌓이는 버퍼로 메모리를 터뜨리지 않고, 소비 가능한 만큼만 받아 처리하는 push-pull 하이브리드로 동작합니다.
두 모델을 비교하면 차이가 분명해집니다.
| 항목 | thread-per-request (Spring MVC) | event loop (Spring WebFlux) |
|---|---|---|
| 스레드 수 | 동시 요청 수에 비례 (수백 개) | 고정, CPU 코어 수 수준 (수 개) |
| I/O 대기 시 | 그 요청의 스레드가 묶임 | 스레드는 다른 커넥션을 처리 |
| 동시성 한계 | 스레드 풀 크기 / 메모리 | event loop 처리량 |
| 블로킹 호출 | 그 요청만 느려짐 | event loop 전체가 멈출 위험 |
마지막 행이 다음 절의 주제입니다. 적은 스레드는 강력하지만 대가가 있습니다.
4. 황금률: event loop를 막지 마라
적은 스레드 모델의 대가는 명확합니다. event loop 스레드 하나가 블로킹되면, 그 스레드가 담당하던 수많은 커넥션이 전부 함께 멈춥니다. thread-per-request에서는 블로킹이 그 요청 하나만 느리게 하지만, event loop에서는 한 번의 블로킹이 광범위한 영향을 줍니다. 그래서 WebFlux의 황금률은 “event loop를 블로킹하지 마라”입니다.
그렇다면 블로킹 라이브러리를 꼭 써야 할 때는 어떻게 할까요. 공식 문서는 다른 스레드로 처리를 옮기는 탈출구를 제시합니다.
What if you do need to use a blocking library? Both Reactor and RxJava provide the publishOn operator to continue processing on a different thread. That means there is an easy escape hatch. Keep in mind, however, that blocking APIs are not a good fit for this concurrency model.
- Spring Framework Reference, Concurrency Model
실무에서의 선택은 보통 다음과 같습니다.
- DB 접근: 블로킹 JDBC 대신 R2DBC(리액티브 드라이버)를 쓴다.
- 외부 HTTP 호출: 블로킹
RestTemplate대신 논블로킹WebClient를 쓴다. - 불가피한 블로킹 코드: 전용 스레드 풀인
Schedulers.boundedElastic()에 격리한다.
1
2
3
4
5
6
7
8
9
10
11
12
// 안티패턴: event loop 스레드에서 그대로 subscribe될 때의 블로킹 JDBC 호출
// fromCallable 자체는 lambda를 구독 시점에 실행할 뿐, 스레드를 옮기지 않는다.
// 별도 Scheduler 지정이 없으면 구독한 스레드(여기서는 event loop)에서 실행되어
// -> 이 스레드가 담당하던 모든 커넥션이 함께 멈춘다
Mono<Order> bad = Mono.fromCallable(() -> jdbcRepo.findById(id));
// 격리: 블로킹 작업을 boundedElastic 스레드로 옮긴다
Mono<Order> ok = Mono.fromCallable(() -> jdbcRepo.findById(id))
.subscribeOn(Schedulers.boundedElastic()); // event loop 보호
// 더 나은 방향: 애초에 논블로킹 드라이버(R2DBC) 사용
Mono<Order> best = r2dbcRepo.findById(id);
블로킹을 boundedElastic로 격리하는 것은 “탈출구”이지 “해법”이 아닙니다. 블로킹 비중이 크다면 event loop의 이점이 사라지므로, 그런 워크로드는 오히려 Spring MVC가 단순하고 적합할 수 있습니다. 이 선택 기준은 다음 편에서 다룹니다.
5. netty와 direct memory - 왜 off-heap인가
이제 메모리로 넘어갑니다. netty는 소켓에서 바이트를 읽고 씁니다. 이때 쓰는 I/O 버퍼를 JVM 힙이 아니라 direct memory(off-heap)에 둡니다. 왜일까요.
핵심은 native I/O입니다. OS의 read/write 같은 시스템 콜은 메모리 주소가 고정된 버퍼를 필요로 합니다. 그런데 JVM 힙의 객체는 GC가 정리하면서 위치를 옮길 수 있어, 커널에 직접 넘기기 어렵습니다. 그래서 힙 버퍼를 쓰면 한 번 더 복사가 일어납니다. direct buffer는 GC가 옮기지 않는 native 메모리라 이 복사를 피할 수 있습니다.
Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer’s content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system’s native I/O operations.
- Java SE 21 API, java.nio.ByteBuffer
다만 direct buffer는 공짜가 아닙니다. 할당과 해제 비용이 일반 힙 버퍼보다 비싸므로, 매 요청마다 새로 만들고 버리면 손해입니다.
The buffers returned by this method typically have somewhat higher allocation and deallocation costs than non-direct buffers.
- Java SE 21 API, java.nio.ByteBuffer
그래서 netty는 direct buffer를 매번 새로 할당하지 않고 풀링(pooling)합니다. 기본 할당자인 PooledByteBufAllocator는 메모리 arena와 thread-local 캐시로 버퍼를 재사용하며, direct buffer도 이 풀로 관리합니다(isDirectBufferPooled()가 true를 반환). 비싼 할당/해제를 줄이는 대신, 풀이 잡아둔 off-heap 메모리는 GC가 자동으로 회수하지 않으므로 한 번 늘어난 direct memory 사용량은 쉽게 줄지 않습니다. 누수처럼 보이는 증가의 상당수는 사실 이 풀이 유지하는 정상 점유분입니다.
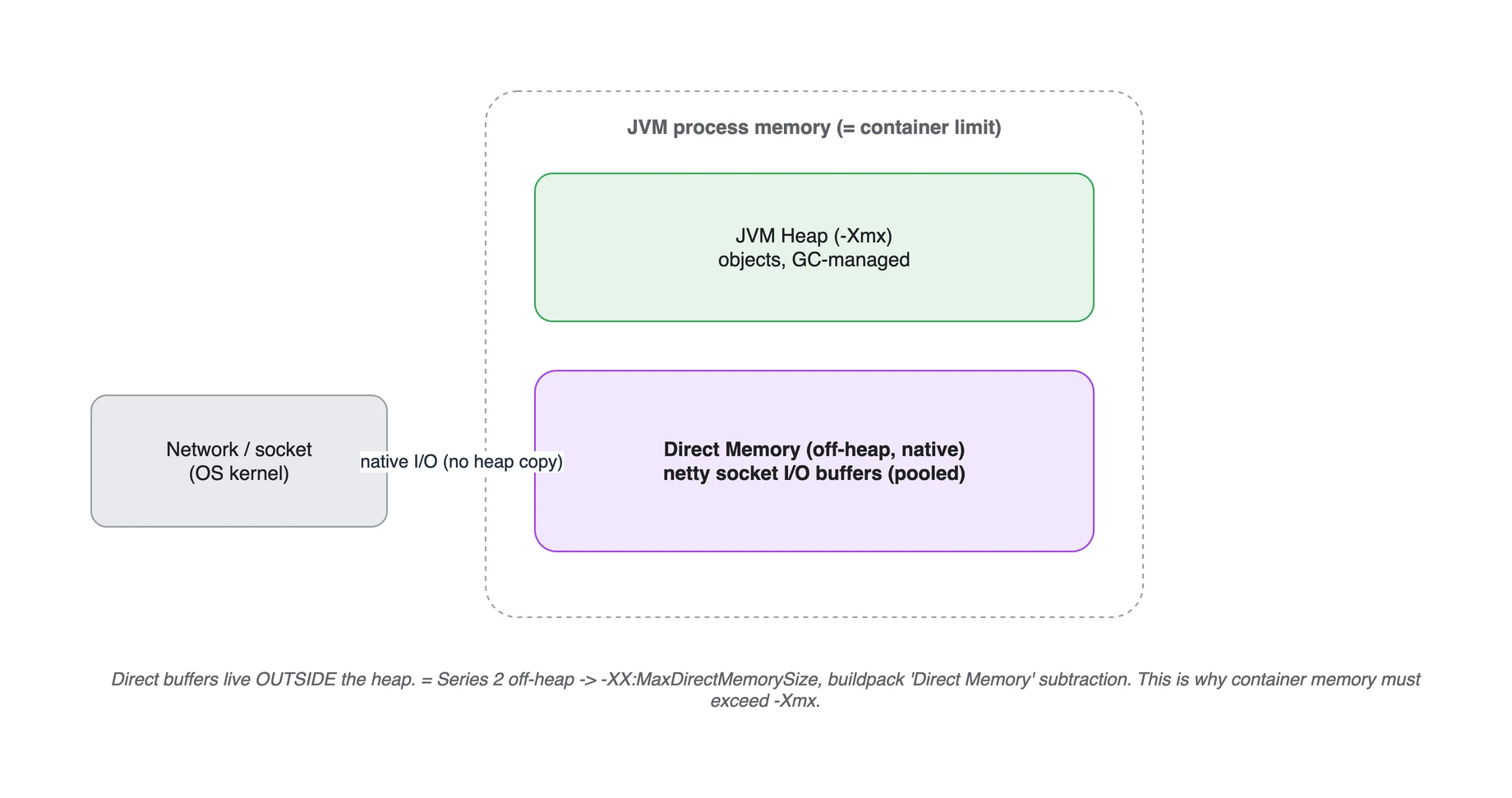 JVM process memory = JVM Heap(-Xmx) + Direct Memory(off-heap). netty 소켓 I/O 버퍼는 후자에 있어 커널과 복사 없이 주고받는다. 그래서 컨테이너 메모리는 -Xmx보다 커야 한다.
JVM process memory = JVM Heap(-Xmx) + Direct Memory(off-heap). netty 소켓 I/O 버퍼는 후자에 있어 커널과 복사 없이 주고받는다. 그래서 컨테이너 메모리는 -Xmx보다 커야 한다.
그리고 이 메모리의 위치가 중요합니다. direct buffer는 GC가 관리하는 일반 힙 바깥에 있습니다.
The contents of direct buffers may reside outside of the normal garbage-collected heap, and so their impact upon the memory footprint of an application might not be obvious.
- Java SE 21 API, java.nio.ByteBuffer
여기서 Series 2와 연결됩니다.
- JVM 메모리 구조 편에서 본 “direct / off-heap” 영역이 바로 이것입니다.
- buildpack memory calculator가 컨테이너 메모리에서 “Direct Memory”를 따로 빼두는 이유이기도 합니다.
- 상한은
-XX:MaxDirectMemorySize로 설정합니다. 명시하지 않으면 JVM이 자동으로 크기를 정합니다(보통-Xmx에 준하는 값). 즉 컨테이너 메모리 산정 시 “direct는 0”이 아니라 힙만큼 더 잡힐 수 있다고 봐야 합니다.- 그래서 컨테이너 메모리는 -Xmx보다 커야 합니다. 힙 + direct memory + metaspace + 스레드 스택 등이 모두 한 프로세스 안에 들어가기 때문입니다.
-XX:MaxDirectMemorySize의 기본 동작은 java launcher 매뉴얼에 명시되어 있습니다.
Sets the maximum total size (in bytes) of the
java.niopackage, direct-buffer allocations. … If not set, the flag is ignored and the JVM chooses the size for NIO direct-buffer allocations automatically.
- java SE 21 launcher manual, -XX:MaxDirectMemorySize
특히 WebFlux/netty 앱은 동시 커넥션이 많을수록 I/O 버퍼로 쓰는 direct memory가 커질 수 있습니다. 따라서 컨테이너 메모리를 산정할 때 힙(-Xmx)만 보면 안 되고, off-heap을 반드시 함께 고려해야 합니다.
이번 글에서는 WebFlux가 적은 event loop 스레드로 다수 커넥션을 논블로킹 처리하는 모델과, netty가 off-heap direct memory를 I/O 버퍼로 쓰는 이유를 봤습니다.
capstone 연결: event loop 모델과 off-heap direct memory는 커리큘럼 마지막 capstone(실전 메모리/GC 사례)에서 다시 회수합니다. 서비스명이나 실측치 없이, 일반화된 메커니즘과 재구성된 예시로만 다룹니다.
다음 편에서는 그러면 언제 WebFlux를 쓰고 언제 MVC가 더 나은지, 즉 두 모델의 선택 기준과 트레이드오프를 정리합니다. event loop가 항상 이득은 아니기 때문입니다.
DevSecOps 비유: event loop는 nginx나 Node.js의 단일 스레드 이벤트 루프(epoll 기반 다중 커넥션 처리)와 같은 발상이고, off-heap의 복사 회피는 sendfile/mmap의 zero-copy와 닮았습니다. “event loop를 블로킹하지 마라”는 곧 “비동기 이벤트 루프 안에서 동기 syscall로 워커를 막지 마라”와 같은 원칙입니다.
6. 참고 자료
- Spring Framework Reference - Spring WebFlux (Servers / Threading Model / Concurrency Model): https://docs.spring.io/spring-framework/reference/web/webflux/new-framework.html
- Reactor Reference - Reactive Programming (backpressure / request mechanism): https://projectreactor.io/docs/core/release/reference/reactiveProgramming.html
- Java SE 21 API - java.nio.ByteBuffer (Direct vs. non-direct buffers): https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/nio/ByteBuffer.html
- Netty 4.1 API - PooledByteBufAllocator (direct buffer pooling): https://netty.io/4.1/api/io/netty/buffer/PooledByteBufAllocator.html
- Java SE 21 - java launcher manual (-XX:MaxDirectMemorySize): https://docs.oracle.com/en/java/javase/21/docs/specs/man/java.html
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi