리액티브 프로그래밍과 Reactor 기초 - Reactive Streams, backpressure, Mono/Flux

Series 1 3편에서 Spring MVC는 thread-per-request, 즉 “요청당 워커 스레드 1개가 I/O를 기다리는 동안에도 묶여 있다”고 했습니다. Series 3은 그 블로킹을 하지 않는 다른 모델 - 리액티브(WebFlux) - 을 다룹니다. 그 첫걸음으로 이번 편은 리액티브의 개념과 Reactor의 기초를 잡습니다.
TL;DR
- 블로킹(명령형)은 “호출하고 결과를 기다리며 스레드를 점유”하고, 리액티브(논블로킹)는 “데이터 흐름(stream)을 선언하고, 준비되면 반응”한다.
- Reactive Streams는 비동기 스트림 처리의 표준이고, 핵심은 backpressure(소비자가 받을 양을
request(n)으로 제어).- Reactor(WebFlux의 기반)의 두 타입:
Mono(0..1) /Flux(0..N). 연산자는 파이프라인을 조립할 뿐,subscribe()전엔 아무 일도 일어나지 않는다(lazy).- 블로킹을 안 하니 스레드가 묶이지 않고, 그래서 적은 스레드(event loop)로 많은 요청을 처리할 수 있다(다음 편).
1. 블로킹 vs 리액티브
아래 예시에서 Order는 단순한 도메인 레코드라고 가정합니다. 그리고 같은 데이터를 조회하더라도 반환 타입이 다르므로 repository도 둘로 나눕니다: 블로킹 JPA repository는 blockingRepo(값 Order를 직접 반환), 리액티브 R2DBC repository는 reactiveRepo(Mono<Order>/Flux<Order>를 반환)로 표기합니다.
1
2
3
4
5
6
7
8
9
10
// 도메인 타입 (예시): record Order(Long id, boolean paid) {}
// 블로킹 / 명령형 - blockingRepo.findById(id) 반환 타입: Order
Order o = blockingRepo.findById(id); // 결과 나올 때까지 이 스레드가 멈춰서 기다림
use(o);
// 리액티브 / 논블로킹 - reactiveRepo.findById(id) 반환 타입: Mono<Order>
reactiveRepo.findById(id) // "조회하면 -> 이렇게 처리해라" 파이프라인을 선언
.map(this::toDto) // 스레드를 붙잡지 않음
.subscribe(this::use); // 데이터가 준비되면 그때 흘러옴
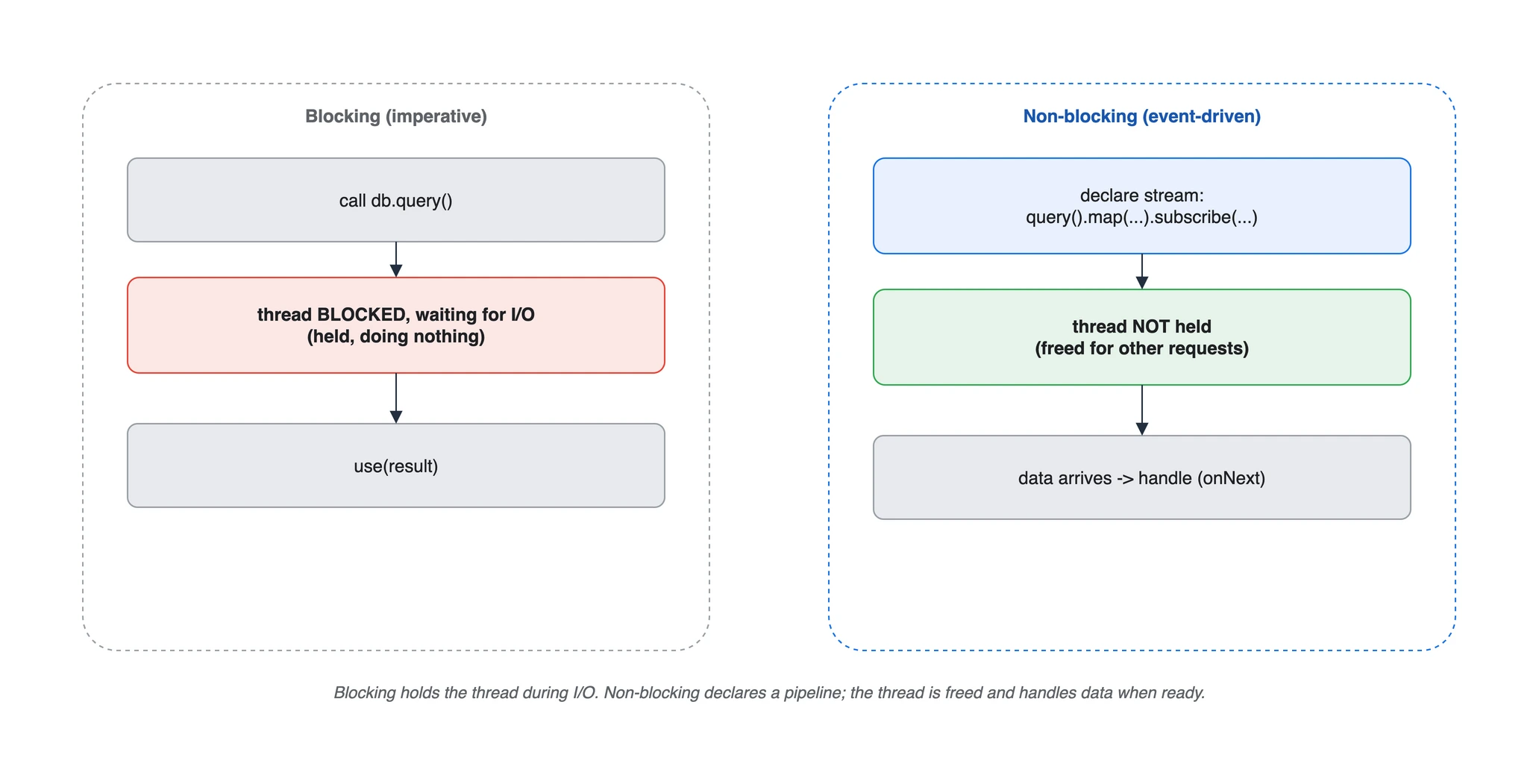 블로킹: I/O 대기 동안 스레드 점유 vs 논블로킹: 파이프라인 선언, 스레드 freed, 준비되면 처리
블로킹: I/O 대기 동안 스레드 점유 vs 논블로킹: 파이프라인 선언, 스레드 freed, 준비되면 처리
- 명령형: “호출하고, 기다리고, 받는다.” 기다리는 동안 스레드 점유.
- 리액티브: “데이터 스트림을 선언하고, 오면 반응(react)한다.” 기다리며 스레드를 묶지 않음.
2. Reactive Streams와 backpressure
리액티브의 공통 규격이 Reactive Streams입니다.
provide a standard for asynchronous stream processing with non-blocking back pressure.
4개 인터페이스로 구성됩니다 (Java의 java.util.concurrent.Flow에도 동일 규격이 있습니다).
- Publisher: 데이터를 내보내는 쪽
- Subscriber: 소비하는 쪽 (
onNext/onComplete/onError) - Subscription: 둘을 잇는 계약 (요청량/취소 제어)
- Processor: Publisher이자 Subscriber (중간 변환)
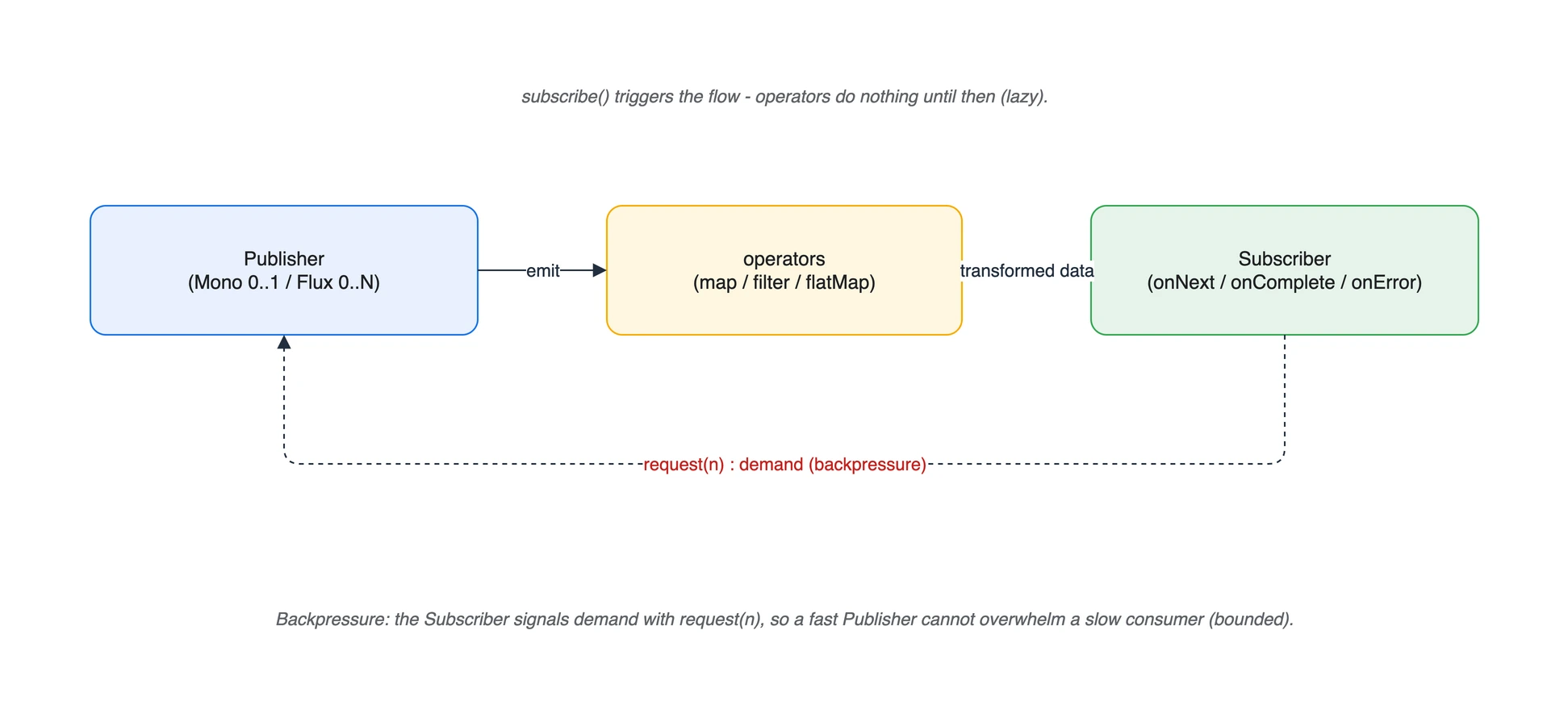 Publisher -> operators -> Subscriber, 그리고 Subscriber가 request(n)으로 demand를 거꾸로 신호
Publisher -> operators -> Subscriber, 그리고 Subscriber가 request(n)으로 demand를 거꾸로 신호
핵심은 backpressure입니다. 소비자가 request(n)으로 받을 양을 직접 신호하므로, 빠른 생산자가 느린 소비자를 압도하지 않습니다.
구체적으로 demand가 흐르는 방향은 데이터와 반대입니다. subscribe() 시점에 Subscriber는 Subscription을 받고, subscription.request(n)을 호출해 “지금 최대 n개까지 받을 수 있다”고 위로(upstream) 신호합니다. Publisher는 그 demand 한도 안에서만 onNext로 데이터를 내려보내고, Subscriber가 n개를 다 처리하면 다시 request로 추가 demand를 채워 넣습니다. Reactor 공식 문서는 이 모델을 다음과 같이 설명합니다.
A subscriber can work in unbounded mode and let the source push all the data at its fastest achievable rate or it can use the
requestmechanism to signal the source that it is ready to process at mostnelements.
즉 request(n)으로 n을 제한하면 소비 속도에 맞춰 bounded queue가 유지되고, demand를 사실상 무제한으로 열어두면(request(Long.MAX_VALUE)) 생산자가 최대 속도로 밀어내는 순수 push 모델이 됩니다. 이 두 극단 사이를 request(n)이 메우기 때문에 Reactor는 이를 push-pull 혼합이라고 부릅니다.
This transforms the push model into a push-pull hybrid, where the downstream can pull n elements from upstream if they are readily available.
back pressure is an integral part of this model in order to allow the queues which mediate between threads to be bounded.
3. Reactor: Mono / Flux, 그리고 lazy
Spring WebFlux가 쓰는 구현체가 Reactor입니다. 두 핵심 타입:
A
Fluxobject represents a reactive sequence of 0..N items
a
Monoobject represents a single-value-or-empty (0..1) result
1
2
3
4
5
6
7
// reactiveRepo: R2DBC 등 리액티브 repository (Mono/Flux 반환)
Mono<Order> one = reactiveRepo.findById(id); // 0 또는 1
Flux<Order> many = reactiveRepo.findAll(); // 0..N
many.filter(Order::paid)
.map(Order::id)
.subscribe(System.out::println); // 이 시점에 비로소 데이터가 흐름
결정적 원칙은 subscribe() 전엔 아무 일도 일어나지 않는다는 것입니다.
when you write a
Publisherchain, data does not start pumping into it by default. Instead, you create an abstract description of your asynchronous process … By the act of subscribing, you tie thePublisherto aSubscriber, which triggers the flow of data in the whole chain.
즉 map/filter 등은 “조립(assembly)”만 하고, subscribe()가 호출돼야 데이터가 흐릅니다 (lazy). 이 lazy 특성은 두 시점을 구분하면 분명해집니다. assembly time은 filter/map 같은 연산자를 연결해 파이프라인이라는 추상 서술을 만드는 단계이고, subscription time은 subscribe()로 그 서술을 실제로 실행하는 단계입니다. 다음 코드는 둘이 다른 시점임을 보여줍니다.
1
2
3
4
5
6
7
8
9
Flux<Order> pipeline =
reactiveRepo.findAll()
.filter(Order::paid)
.map(Order::id); // 여기까지가 assembly time: DB 조회는 아직 일어나지 않음
// ... 여기서는 아무 일도 일어나지 않는다. pipeline은 그저 "할 일의 설계도"일 뿐 ...
pipeline.subscribe(System.out::println); // subscription time: 이제 demand(request)가
// 위로 흐르고 findAll() 조회가 실제로 실행됨
같은 pipeline을 두 번 subscribe()하면 조회도 두 번 실행됩니다. 연산자 체인 자체에는 부수 효과(side effect)가 없고, 트리거는 오직 subscribe()이기 때문입니다.
4. 연결: 왜 이게 event loop를 가능케 하나
블로킹을 안 하니 스레드가 I/O 대기에 묶이지 않습니다. 그래서 적은 수의 고정 스레드(event loop)로 수많은 요청을 번갈아 처리할 수 있습니다. 이게 다음 편 Spring WebFlux + netty event loop의 핵심이고, Series 1 3편 thread-per-request(요청당 스레드 1개 점유)의 정반대입니다.
주의: 리액티브 파이프라인 안에서 블로킹 코드(예: 블로킹 JDBC,
Thread.sleep)를 호출하면 event loop 스레드가 묶여 전체가 느려집니다. 이 트레이드오프는 Series 3 3편(MVC vs WebFlux 선택 기준)에서 다룹니다.
DevSecOps 비유: backpressure는 흐름 제어(TCP flow control, bounded queue, rate limit)와 같은 발상이고, 리액티브는 동기 블로킹 대신 이벤트 기반(nginx event loop, async handler)으로 일하는 모델입니다.
5. 참고 자료
- Reactor Reference - Core Features (Mono / Flux): https://projectreactor.io/docs/core/release/reference/coreFeatures.html
- Reactor Reference - Reactive Programming (Nothing Happens Until You subscribe()): https://projectreactor.io/docs/core/release/reference/reactiveProgramming.html
- Reactive Streams (표준 / backpressure): https://www.reactive-streams.org/
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi