JPA N+1 문제와 해결 - fetch join, batch size, EntityGraph

Series 4 1편에서 영속성 컨텍스트를, 2편에서 트랜잭션을 봤습니다. JPA(Java Persistence API, 현재 Jakarta Persistence) 를 사용할 때 자주 마주치는 성능 문제 중 하나가 N+1 selects입니다. 코드는 단순하지만 실행 SQL을 보면 예상보다 많은 SELECT가 나가는 상황입니다. 이번 글에서는 N+1이 생기는 조건과 fetch join, batch fetching, EntityGraph, DTO projection을 언제 선택할지 정리합니다. Series 4(데이터 계층)의 마무리입니다.
TL;DR
- N+1: 부모 목록을 한 번 조회한 뒤, 반복문에서 초기화되지 않은 연관을 접근하면 부모 수만큼 추가 조회가 발생할 수 있는 패턴입니다.
- fetch join: JPQL
join fetch로 이번 조회에 필요한 연관을 같은 조회 계획에 포함합니다.- batch fetching: Hibernate의
@BatchSize또는default_batch_fetch_size가 초기화할 프록시나 컬렉션을IN조건으로 묶어 추가 조회 수를 줄입니다.- EntityGraph / DTO projection: 조회별 fetch plan을 선언하거나, 화면에 필요한 데이터만 투영합니다.
- 함정: 컬렉션 fetch join과 페이징, 둘 이상의 bag 컬렉션 fetch join은 결과셋 크기와 메모리 사용량을 먼저 검토해야 합니다.
1. N+1이란
Order가 items를 LAZY로 가지고 있을 때, 주문 목록을 조회한 뒤 각 주문의 items를 접근하는 흔한 코드입니다. LAZY는 연관을 즉시 읽지 않겠다는 힌트이며, 실제 추가 SQL은 영속성 컨텍스트에 이미 해당 연관이 있는지와 구현체의 fetch plan에 따라 달라집니다. 아래처럼 아직 초기화되지 않은 컬렉션을 순회 중에 처음 접근하면 N+1 패턴이 나타날 수 있습니다.
1
2
3
4
5
List<Order> orders = orderRepository.findAll(); // 쿼리 1: SELECT * FROM orders (N건)
for (Order o : orders) {
o.getItems().size(); // LAZY items 접근 -> 주문마다 SELECT (쿼리 N건)
}
// 총 1 + N 번의 쿼리
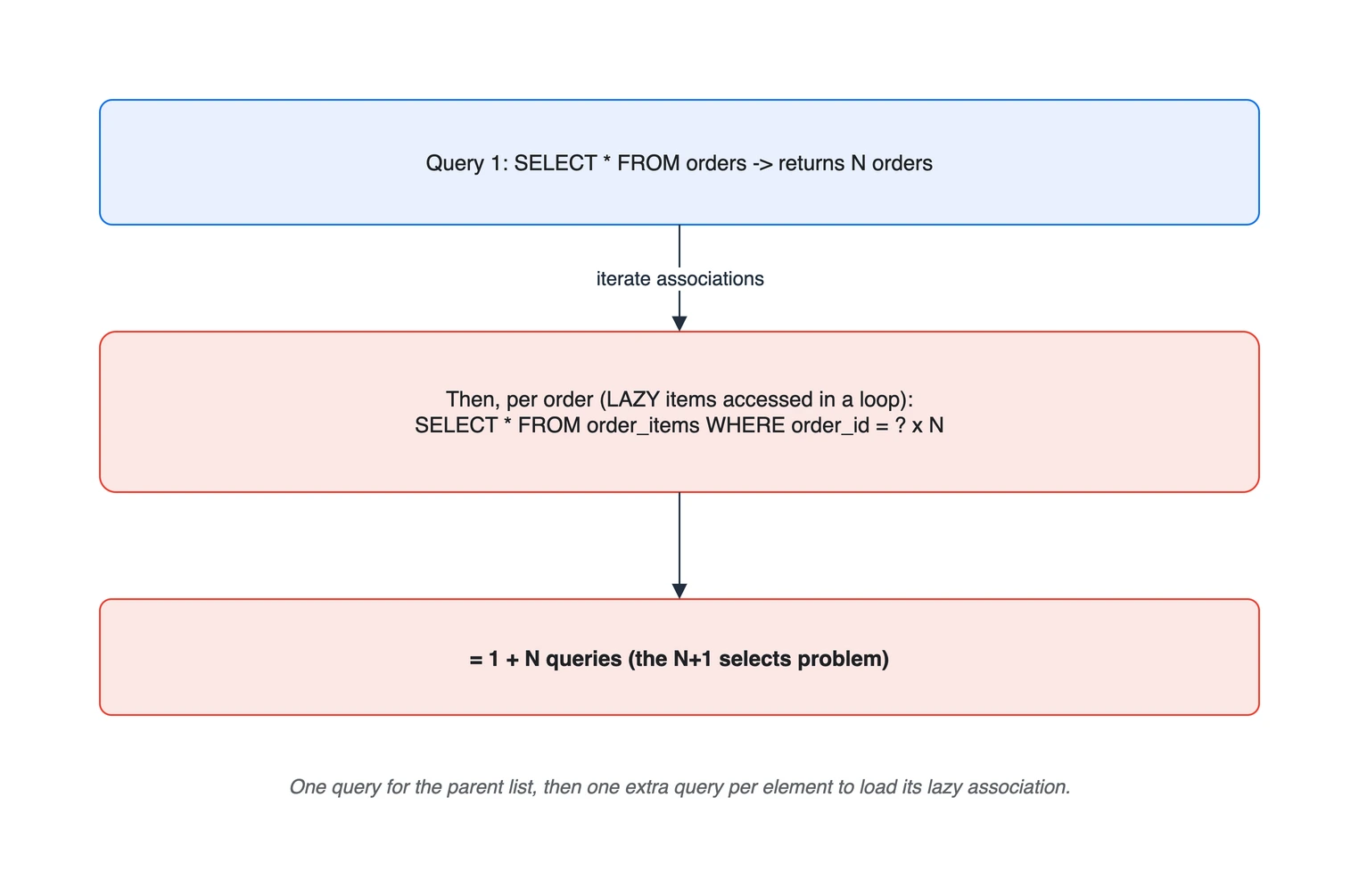 부모 목록을 1번 조회하고, 각 요소의 LAZY 연관을 접근할 때마다 추가 쿼리가 나가 1 + N번이 된다.
부모 목록을 1번 조회하고, 각 요소의 LAZY 연관을 접근할 때마다 추가 쿼리가 나가 1 + N번이 된다.
주문이 100건이면 1 + 100 = 101번의 쿼리가 나갑니다. 데이터가 늘수록 선형으로 악화되므로, 목록이 커질 때 갑자기 느려지는 전형적인 원인입니다.
LAZY자체가 문제는 아닙니다. 문제는 조회 목적을 확인하지 않은 채 목록을 순회하면서 연관을 초기화하는 패턴입니다. 해결은 화면 또는 유스케이스에 필요한 연관만 명시적으로 가져오고, SQL과 행 수를 함께 확인하는 것입니다.
2. 해결 전략 한눈에
먼저 조회 목적을 정합니다. 목록 화면에서 연관을 반드시 표시한다면 fetch join 또는 EntityGraph를, 페이지 단위로 여러 컬렉션을 표시한다면 batch fetching을, 엔티티 변경이 없는 읽기 모델이라면 DTO projection을 우선 검토합니다.
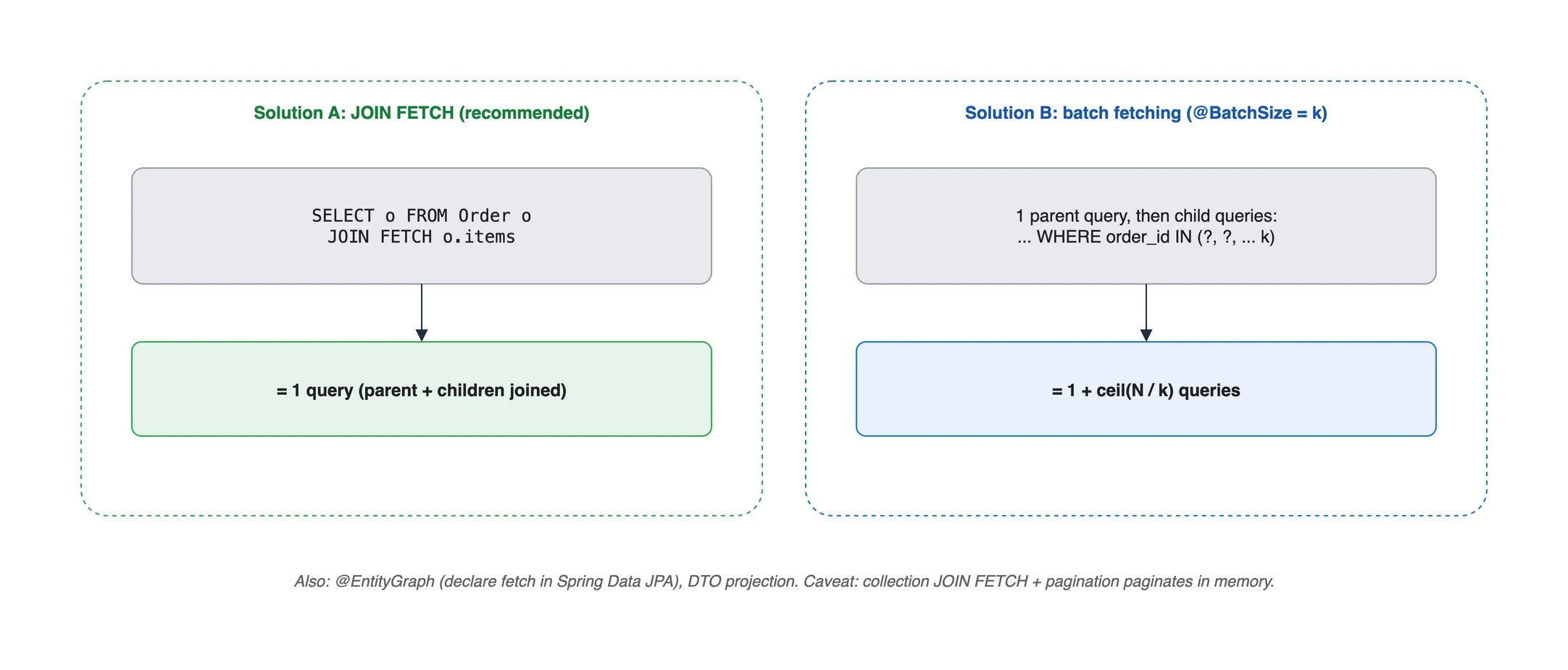 fetch join은 조인으로 한 쿼리에, batch fetching은 IN 절로 묶어 1 + ceil(N/k)번에 가져온다.
fetch join은 조인으로 한 쿼리에, batch fetching은 IN 절로 묶어 1 + ceil(N/k)번에 가져온다.
3. fetch join (권장)
JPQL join fetch는 반환할 엔티티의 연관을 같은 조회에서 가져오도록 지정합니다. Jakarta Persistence 명세에서 fetch join은 연관 또는 컬렉션을 조회 결과의 부수 효과로 가져오는 문법입니다. 필요한 to-one 연관이나 작은 컬렉션을 목록과 함께 보여 줄 때 가장 직접적인 선택입니다.
1
2
@Query("select o from Order o join fetch o.items")
List<Order> findAllWithItems(); // items까지 한 쿼리에
연관이 단일(@ManyToOne, @OneToOne)이면 결과 행이 크게 늘지 않아 특히 다루기 쉽습니다. 컬렉션 fetch join은 부모 행이 자식 수만큼 반복될 수 있으므로, 반환 행 수와 페이징 요구사항을 함께 확인해야 합니다.
4. batch fetching (@BatchSize)
연관을 여전히 LAZY로 두되, 초기화가 필요할 때 Hibernate가 여러 건을 IN 조건으로 묶어 가져오도록 하는 방식입니다. 배치 크기를 k로 잡으면, 같은 세션에서 초기화되는 대상이 충분하다는 조건에서 추가 조회 수는 대략 ceil(N/k)에 가까워집니다. 실제 묶음 수는 이미 초기화된 연관, 활성 프록시 수, 데이터베이스의 IN 조건 제한에 따라 달라집니다.
1
2
3
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
@BatchSize(size = 100)
private List<Item> items;
1
2
3
4
5
6
# 전역 적용 (application.yml)
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
부모 목록의 DB 페이징을 보존하면서 컬렉션을 후속 조회해야 할 때 유용합니다. 다만 배치 크기는 크게 잡을수록 항상 좋은 값이 아닙니다. 실제 페이지 크기, 평균 컬렉션 크기, 쿼리 계획을 보고 조정합니다.
5. EntityGraph와 DTO projection
@EntityGraph: Jakarta Persistence의 entity graph는 조회 시 적용할 fetch plan입니다. Spring Data JPA에서는 리포지토리 메서드에 가져올 연관을 선언할 수 있습니다.
1
2
3
@EntityGraph(attributePaths = "items")
@Query("select o from Order o")
List<Order> findAllWithItemsGraph();
- DTO projection: 엔티티 전체가 아니라 화면에 필요한 컬럼만 조회합니다. 변경 감지나 연관 탐색이 필요 없는 조회 전용 화면이라면, 엔티티를 영속성 컨텍스트에 올리는 비용 자체를 피할 수 있습니다.
6. 함정
- 컬렉션 fetch join + 페이징. 컬렉션 fetch join에
setFirstResult()또는setMaxResults()를 조합하면, Hibernate는 기본 설정에서 DB가 아닌 메모리에서 페이징할 수 있고 경고를 남깁니다. 부모 목록은 먼저 페이지 단위로 조회하고, 컬렉션은 batch fetching이나 두 번째 조회로 채우는 방식을 검토합니다. 필요하면 Hibernate의 fail-fast 설정으로 이 조합을 배포 전에 차단합니다. - 둘 이상의 bag 컬렉션 fetch join. 인덱스가 없는
List같은 bag 컬렉션을 둘 이상 한 번에 fetch join하면 Hibernate가MultipleBagFetchException을 낼 수 있습니다.Set으로 바꾼다고 카테시안 곱과 큰 결과셋 문제가 사라지는 것은 아니므로, 보통은 조회를 분리하거나 DTO로 평탄화합니다. - fetch join 남발. 필요 없는 연관까지 가져오면 중복 행, 큰 결과셋, 영속성 컨텍스트 메모리 사용량이 커질 수 있습니다. 화면별로 필요한 연관과 예상 행 수를 기준으로 선택합니다.
7. Series 4 마무리
영속성 컨텍스트 -> 트랜잭션과 전파 -> N+1과 성능으로 데이터 계층 세 편을 마쳤습니다. JPA가 추상화해 주는 편의 뒤에서 실제로 무슨 일이 일어나는지, 즉 언제 SQL이 나가고 어떤 객체가 영속성 컨텍스트에 남는지를 확인하면 성능 문제를 예방할 수 있습니다.
capstone 연결: N+1은 DB 부하만이 아니라 대량 엔티티를 JVM 힙에 올리는 문제이기도 합니다. 목록이 커질수록 영속성 컨텍스트에 쌓이는 객체와 쿼리가 함께 늘어, GC 압박과 응답 지연으로 이어집니다.
실무에서는 먼저 SQL 로그나 APM으로 부모 조회 뒤의 반복 SELECT를 확인합니다. 그 다음 to-one 또는 작은 컬렉션에는 fetch join, 페이징되는 컬렉션에는 batch fetching, 읽기 모델에는 DTO projection을 적용하고, 변경 전후 쿼리 수와 반환 행 수를 비교하면 됩니다.
8. Reference
- Jakarta Persistence Specification
- Hibernate ORM User Guide - Fetching
- Hibernate ORM Introduction - Tuning and performance
- Spring Data JPA Reference - JPA EntityGraph
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi