Bedrock Knowledge Bases와 n8n으로 Slack RAG 챗봇 운영하기 - Google Docs 파싱부터 멘션 봇, 실측 함정까지

AWS Bedrock Knowledge Base 글에서는 Knowledge Bases의 구성 요소와 API, 접근제어를 정리했습니다. 이번 글은 그중 S3 Vectors를 직접 선택한 Customer-managed Knowledge Base를 실제로 조립한 기록입니다. 사내 정책 문서(Google Docs)를 지식 소스로 삼아, Slack에서 봇을 멘션하면 출처 딥링크가 달린 답변이 돌아오는 RAG 챗봇을 구축하고 운영까지 검증했습니다.
처음 설계는 단순했습니다. Google Docs를 PDF로 export해서 S3에 올리고, Lambda로 Slash Command를 받아 RetrieveAndGenerate를 호출하는 구조였습니다. 그런데 구축을 진행하면서 설계의 절반 이상이 뒤집혔습니다. PDF 대신 자체 파서로 섹션별 Markdown을 만들게 됐고, Lambda는 하나도 만들지 않았으며, RetrieveAndGenerate 대신 Retrieve + rerank + 외부 LLM 조합이 됐습니다. 이 글은 “무엇을 만들었나”와 함께 “왜 처음 설계가 틀렸고 무엇으로 바꿨나”를 실측 근거와 함께 정리합니다.
1. TL;DR
- Google Docs를 PDF로 변환하지 않습니다. Docs API JSON을 자체 파서로 섹션별 Markdown으로 만들어야 heading 앵커 딥링크 citation과 표 데이터 보존이 가능합니다.
- 벡터스토어는 S3 Vectors로 유휴 고정비를 없앴습니다. 대신 metadata 2KB 한도와 인덱스 immutable이라는 함정이 있습니다.
- Slack은 Slash Command + Lambda 대신 n8n Slack Trigger(멘션)가 서명 검증과 3초 ack를 내장 처리합니다. Lambda 0개.
- 질의는 RetrieveAndGenerate 대신 Retrieve + Cohere rerank + 외부 LLM으로 분리해 근거 게이트(“모르면 모른다”)를 직접 제어합니다.
- 질문 1건 약 $0.014, 고정비 월 $0.01 미만. 함정 10여 개를 전부 실측으로 밟고 해결 과정을 남겼습니다.
2. 이 글의 읽는 순서
처음 구축한다면 2 -> 3 -> 5 -> 6 -> 7 -> 9 -> 10 -> 12 순서로 읽으면 됩니다. Google Docs를 이미 Markdown으로 내보낼 수 있다면 3-4는 건너뛰고, Slack UX만 필요하면 9부터, 검색 품질과 비용만 검토한다면 10, 13, 14를 보면 됩니다.
이 글의 구성은 다음처럼 나뉩니다.
| 관심사 | 섹션 | 얻는 결과 |
|---|---|---|
| 원본 문서와 색인 품질 | 3-8 | Docs를 citation 가능한 Markdown으로 만들고 ingestion을 확인하는 방법 |
| Slack 챗봇 UX | 9 | 멘션 수신, 즉시 ack, 스레드 응답, 실패 표시 흐름 |
| 검색과 답변 품질 | 10-11, 14 | Retrieve, rerank, 근거 게이트, 평가 기준 |
| 권한과 비용 | 12-13 | 전용 role 체인과 workload 기준 비용 산정 |
이 글은 Bedrock이 저장소와 retrieval까지 운영하는 Managed Knowledge Base가 아니라, S3 Vectors와 IAM을 직접 구성하는 Customer-managed Knowledge Base 실습입니다.
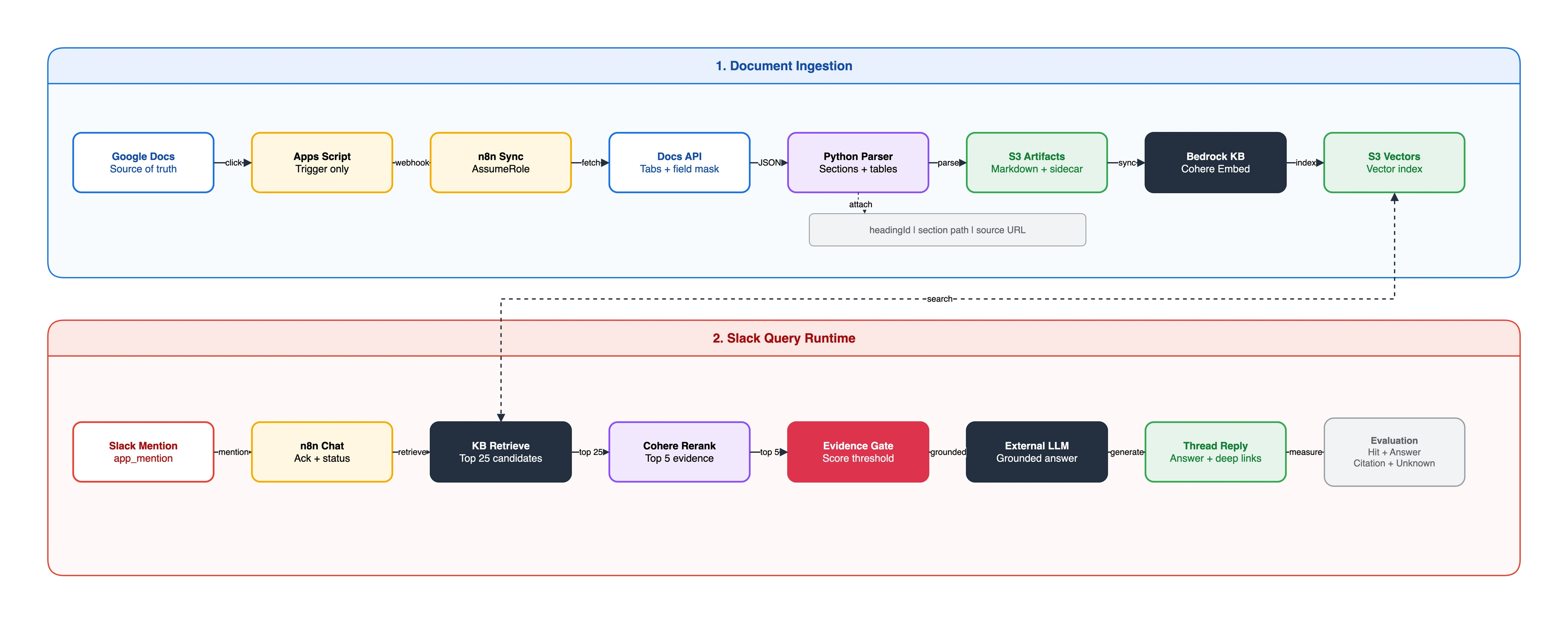
3. 목표 아키텍처
전체 흐름은 색인(ingestion)과 질의(chat) 두 파이프라인으로 나뉩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[색인] Google Docs 원본 수정
-> Apps Script 버튼 (webhook 트리거만, 문서 내용 미전송)
-> n8n sync workflow
-> Docs API fetch (Service Account, read-only)
-> Python 파서 (섹션 분리 + 표 선형화 + citation metadata)
-> S3 업로드 (섹션별 .md + .metadata.json)
-> Bedrock KB StartIngestionJob -> polling -> Slack 통지
[질의] Slack 봇 멘션 (@DocsBot)
-> n8n chat workflow
-> 즉시 :eyes: 리액션
-> KB Retrieve (후보 25) + Cohere rerank (상위 5)
-> 근거 게이트 (관련도 미달 시 거절)
-> LLM 답변 생성 (발췌 근거 강제)
-> 스레드 응답 + 출처 딥링크, :white_check_mark: (실패 시 :x:)
| 영역 | 구성 요소 | 처음 설계와 달라진 점 |
|---|---|---|
| 원본 문서 | Google Docs | 동일 (사람이 수정하는 SOT) |
| 변환 | 자체 Python 파서 (n8n Code 노드) | PDF export -> 섹션별 Markdown으로 변경 |
| 저장 | S3 (kb/ prefix) + metadata sidecar | 동일 골격, 레이아웃/스키마 재설계 |
| 벡터스토어 | S3 Vectors | OpenSearch Serverless -> 변경 (고정비) |
| 임베딩 | Cohere Embed Multilingual v3 | Titan -> 변경 (한국어) |
| 질의 | Retrieve + rerank + 외부 LLM | RetrieveAndGenerate -> 분리 |
| Slack | n8n Slack Trigger (app_mention) | Lambda + Slash Command -> 제거 |
| 자동화 | n8n workflow 2개 | Lambda wrapper -> n8n 단독(boto3) |
n8n 배포 자체는 이 글의 범위가 아닙니다(이미 운영 중이라고 가정). 이 글은 문서 파싱 품질, 벡터스토어 선택, 검색/생성 분리, Slack UX, IAM 격리, 그리고 그 과정에서 실측으로 밟은 함정들에 집중합니다.
4. 왜 PDF export를 버리고 자체 파서를 만들었나
설계 단계에서는 Google Docs를 PDF로 export해서 S3에 올리고, Bedrock Knowledge Base가 그 PDF를 그대로 ingest하는 구조를 계획했습니다. 협업 편집은 Docs가 편하고, PDF는 사용자가 실제로 보는 문서 형태와 가까워 Citation 설명이 쉽다는 이유였습니다. 실제로 구축하면서 이 방향을 버리고 Docs API JSON을 자체 Python 파서로 섹션별 Markdown으로 변환하는 구조로 바꿨습니다. PDF가 RAG 관점에서 세 가지를 만족하지 못했기 때문입니다.
4.1. Citation 딥링크가 문서/페이지 단위에서 멈춘다
RAG 챗봇의 신뢰성은 “이 답변의 근거가 원문 어디인가”를 사용자가 직접 눌러 확인할 수 있느냐에 달려 있습니다. PDF를 ingest하면 Citation은 문서 단위 또는 페이지 번호 단위가 한계입니다. 사용자는 “3페이지 어딘가”를 다시 눈으로 찾아야 합니다.
Google Docs의 실제 heading에는 headingId가 붙어 있고, 이 값으로 원문 특정 섹션에 바로 앵커할 수 있습니다.
1
https://docs.google.com/document/d/{docId}/edit#heading=h.abc123
파서가 섹션마다 이 headingId를 보존해 Citation URL에 #heading=<id>로 심으면, 출처를 클릭했을 때 원문의 해당 섹션으로 바로 이동합니다. PDF 경로에서는 만들 수 없는 링크입니다.
4.2. 정책 사실이 표 안에 있는데 PDF 표는 검색에서 죽는다
사내 정책 문서의 핵심 사실은 대부분 표 안에 있습니다. “휴가 종류별 부여 일수”, “경비 항목별 한도” 같은 값이 행/열 구조로 들어 있습니다. PDF export나 기본 파서가 표를 처리하면 셀이 줄바꿈으로 흩어지거나 rowspan(병합 셀) 헤더가 사라져서, 임베딩과 생성 양쪽에서 “라벨과 값의 연결”이 끊어집니다. 검색으로 표의 특정 행을 찾아도 그 값이 어느 항목의 것인지 모델이 복원하지 못합니다.
그래서 표를 행 단위 사실 블록으로 선형화했습니다. 각 데이터 행을 breadcrumb(섹션 경로)를 앞에 단 한 문장으로 펴서, 행 하나가 독립적으로 검색 가능한 사실이 되도록 만듭니다.
1
2
[경비 규정 > 3.2 항목별 한도] 식대 - 국내 출장: 1일 5만원
[경비 규정 > 3.2 항목별 한도] 식대 - 해외 출장: 1일 8만원
빈 라벨 셀은 이전 행 값을 물려받게(rowspan carry) 처리해서, 병합 셀 때문에 라벨이 비어도 각 행이 완결된 사실이 되도록 했습니다.
4.3. 실무 문서는 heading 스타일이 엉망이라 구조를 복원해야 한다
실제 사내 문서는 Word/Docs의 heading 스타일을 제대로 쓰지 않습니다. 챕터 번호를 굵은 본문 텍스트로 표기하거나, 같은 챕터 레벨인데 어떤 건 heading 스타일이고 어떤 건 그냥 문단인 경우가 흔합니다. 실측 대상 문서에서는 진짜 heading 스타일(HEADING_1 등)이 붙은 챕터가 3개뿐이었고, 나머지는 전부 번호로 시작하는 본문 문단이었습니다. 이 상태로 KB 청킹에 맡기면 문서에 챕터 구조 자체가 없는 것과 같습니다.
파서에서 번호 패턴(2.9, 2.15)을 heading으로 승격하고, 번호 깊이로 레벨을 정규화해 챕터 경계를 복원했습니다. 이 승격 휴리스틱이 오히려 사고를 냈던 경험은 섹션 파서 설계에서 다룹니다.
4.4. Docs API 응답 축소 (n8n 러너 OOM 실측)
파서 입력은 Docs API의 documents.get으로 가져옵니다. 탭 구조까지 받으려면 includeTabsContent=true가 필요합니다.
1
GET https://docs.googleapis.com/v1/documents/{docId}?includeTabsContent=true
- 증상: 파서를 실행하는 n8n Python 러너가 반복적으로 죽었습니다. task-runner 컨테이너의 cgroup 메모리 천장(512Mi)에서
oom_kill이 두 번 발생했습니다. - 원인: Docs API 전체 응답이 문서 스타일/서식 정보까지 포함해 지나치게 컸습니다. 파서가 실제로 읽는 필드는 텍스트, heading 스타일, 표, 탭 제목뿐인데 payload 전체를 메모리에 올리고 있었습니다. 실행 속도를 늦춰도 소용이 없었습니다. 피크 메모리 문제였기 때문입니다.
- 해결: Docs API
fields마스크로 응답 payload 자체를 축소했습니다. 파서가 읽는 필드만 남깁니다.
1
2
3
4
fields=tabs.tabProperties.title,tabs.documentTab.body.content(
paragraph(elements.textRun.content,paragraphStyle(namedStyleType,headingId)),
table.tableRows.tableCells.content.paragraph.elements.textRun.content
)
주의할 점이 하나 있습니다. includeTabsContent=true를 쓸 때 top-level body(...)를 마스크에 함께 넣으면 “legacy text-level fields” 400 에러가 납니다. 탭 기반 응답에서는 tabs.documentTab.body만 지정해야 합니다.
결과: PDF를 그대로 색인하는 대신, 섹션별 Markdown과 heading 딥링크를 색인합니다. 이 선택이 표의 사실 관계와 Slack citation의 클릭 가능성을 동시에 보존합니다.
5. 섹션 파서 설계 (Python, n8n Code 노드에서 실행)
파서는 별도 서비스가 아니라 n8n의 Python Code 노드에서 실행됩니다. 전체 파이프라인은 다음과 같습니다.
1
2
3
4
5
6
Docs API JSON
-> blocks (heading / paragraph / table) # 어댑터: 탭을 평탄화, heading 스타일 -> level
-> 가짜 heading 승격 + 레벨 정규화 # 번호 패턴을 heading으로
-> 섹션화 (heading stack) # leaf 섹션 단위로 분할
-> 표 선형화 # 행 -> 사실 블록
-> 섹션별 Markdown + metadata sidecar # S3 적재 산출물
5.1. n8n Python 러너 샌드박스 3제약 (실측)
n8n의 Python Code 노드는 일반 CPython이 아니라 제한된 샌드박스(task-runner-python)에서 실행됩니다. 파서를 옮기면서 소스로 확정한 제약이 세 가지입니다.
| 제약 | 내용 | 대응 |
|---|---|---|
| stdlib 제한 | datetime, json, time만 import 가능 | hashlib/re 등 미사용. 해시는 순수 Python FNV-1a로, 정규식은 문자 순회로 대체 |
| class 문 금지 | __build_class__가 제거되어 class 선언 자체가 “Security violations detected”로 차단 | 모든 상태를 dict로, 로직을 순수 함수로 작성 |
| 입력 전역 | 입력은 _items 전역으로만 접근 (_items[0]["json"]) | 노드 간 크로스 참조 대신 입력을 명시적으로 전달 |
- 증상: 파서 첫 실행에서 “Security violations detected”로 노드가 즉시 실패했습니다.
- 원인: 파서가 dataclass와 정규식(
re),hashlib을 쓰고 있었습니다. 샌드박스가class문과 허용되지 않은 import를 차단합니다. - 해결: 파서 전체를 dict + 순수 함수로 재작성하고, 패키지를 단일 파일로 번들해 Code 노드에 주입했습니다. 예를 들어 블록은 클래스 대신 dict 팩토리 함수로 만듭니다.
1
2
3
4
5
6
# class 대신 dict 팩토리. 샌드박스가 __build_class__를 제거하므로 순수 함수만 사용
def heading(level, text, heading_id=None):
return {"kind": "heading", "level": level, "text": text, "heading_id": heading_id}
def section(path, heading_id, blocks, level):
return {"path": path, "heading_id": heading_id, "blocks": blocks, "level": level}
change detection용 해시도 hashlib 없이 순수 Python으로 구현했습니다. 정확한 암호학적 해시가 아니라 결정적(deterministic) 다이제스트면 충분하기 때문입니다.
1
2
3
4
5
6
# hashlib 부재 -> FNV-1a 64-bit. 변경 감지용이라 결정성만 있으면 됨
def content_hash(text):
h = 0xCBF29CE484222325
for byte in text.encode("utf-8"):
h = ((h ^ byte) * 0x100000001B3) & 0xFFFFFFFFFFFFFFFF
return format(h, "016x")
5.2. 가짜 heading 승격 함정 (실측)
번호로 시작하는 문단을 heading으로 승격하는 휴리스틱이 제대로 사고를 냈습니다.
- 증상: 챕터 2.13부터 3.4까지 약 100개 섹션이 엉뚱한 상위 챕터 밑으로 오귀속됐습니다. 결국 Citation 경로에
801067 ...처럼 숫자로 시작하는 본문 문장이 챕터 제목처럼 노출됐습니다. - 원인: 승격 조건이 “숫자로 시작하면 heading”에 가까웠습니다.
801067처럼 숫자로 시작하는 본문 문장까지 level-1 heading으로 승격되어, 그 뒤에 오는 실제 챕터들을 전부 자기 밑으로 삼켰습니다. 여기에 실제 heading 스타일과 승격 heading의 레벨이 섞이면서(2.9는 진짜 H1,2.10은 승격 level-2) 형제여야 할 챕터가 중첩됐습니다. - 해결: 두 단계로 다듬었습니다.
- 승격 조건 강화: 번호 그룹당 자릿수를 1~2자리로 제한하고, 전체 길이 상한(60자)을 뒀습니다.
801067은 그룹당 6자리라 차단됩니다. - 레벨 정규화: 번호가 있는 heading은 실제 스타일 레벨과 무관하게 번호 깊이로 레벨을 통일했습니다(
2.9가 real H1이어도 번호 깊이 2로 취급). 이렇게 해야 챕터들이 전부 형제가 됩니다.
- 승격 조건 강화: 번호 그룹당 자릿수를 1~2자리로 제한하고, 전체 길이 상한(60자)을 뒀습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
_MAX_HEADING_LEN = 60 # 이보다 길면 숫자로 시작해도 본문 문장
_MAX_DIGITS_PER_GROUP = 2 # "2.15"는 OK, "801067"은 차단
def promote(blocks):
out = []
for b in blocks:
text = (b.get("text") or "").strip()
if b.get("kind") != "heading" and is_numbered_heading(text):
number = text.split()[0] # "2.10"
level = len(number.split(".")) # 번호 깊이로 레벨 통일
out.append(heading(level=level, text=text, heading_id=b.get("heading_id")))
else:
out.append(b)
return out
수정 후 288개 섹션으로 챕터 2.1~5.3이 원본 목차대로 정상 분리됐고, Citation 오염 경로도 사라졌습니다.
5.3. 섹션화
승격이 끝난 블록 스트림을 heading stack으로 순회하면서 leaf(하위 heading이 더 없는 지점) 단위로 섹션을 만듭니다. 상위 heading 아래에 첫 하위 heading이 나오기 전까지의 도입 문단은 그 레벨의 작은 섹션으로 따로 냅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def build_sections(blocks):
blocks, sections, stack, buf = promote(blocks), [], [], []
def flush():
if buf:
sections.append(section(
path=[h["text"] for h in stack],
heading_id=stack[-1]["heading_id"] if stack else None,
blocks=list(buf), level=stack[-1]["level"] if stack else 0))
buf.clear()
for b in blocks:
if b["kind"] == "heading":
flush()
while stack and stack[-1]["level"] >= b["level"]:
stack.pop()
stack.append(b)
else:
buf.append(b)
flush()
return sections
각 섹션은 Markdown 본문 파일 하나와, Citation에 필요한 metadata sidecar로 출력됩니다.
6. S3 레이아웃과 metadata sidecar
6.1. 계층 레이아웃 + inclusion_prefixes
파서 산출물은 backend-neutral artifact로 S3에 남깁니다. 검색이 이상하면 S3의 실제 chunk를 열어 “임베딩에 뭐가 들어갔는지”를 바로 확인할 수 있고, 나중에 다른 벡터 backend로 교체할 때도 같은 artifact를 재사용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
s3://docs-rag-artifacts/
kb/
<docId>/
sections/
001-intro.md
002-vacation-policy.md
...
manifests/
<docId>/
manifest.json # 색인 대상 아님 (변경 감지용)
Data source에는 kb/ prefix만 inclusion prefix로 지정합니다.
- 증상: 처음엔 flat 구조(
sections/*, 루트에manifest.json)였는데, 첫 ingestion 통계가 “290 documents”로 나왔습니다. 실제 섹션은 289개였습니다. - 원인: flat 구조에서 data source가 버킷을 통째로 스캔하면서 내부 관리 파일인
manifest.json까지 문서로 색인했습니다(289 + manifest = 290). 관리용 JSON이 검색 노이즈가 됩니다. - 해결: 색인 대상을
kb/prefix로 스코프하고, manifest는manifests/prefix로 분리했습니다. 구조적으로 내부 파일이 색인에서 빠집니다.
폴더 키를 title slug가 아니라 docId(불변)로 둔 이유도 있습니다. 문서 제목이 바뀌면 slug 기반 키는 구 키가 인덱스에 잔류해서 삭제되지 않은 유령 문서가 검색에 걸립니다. docId는 문서 수명 내내 바뀌지 않으므로 이 사고 경로를 원천 차단합니다.
6.2. metadata sidecar = citation 3키 (S3 Vectors 한도 실측)
설계 글에서는 type과 includeForEmbedding을 명시한 typed schema(약 10KB)를 metadata sidecar로 계획했습니다. S3 Vectors를 벡터 스토어로 쓰면서 이 형식을 전부 버렸습니다.
- 증상: 첫 ingestion에서 290개 문서 전부가 “invalid metadata attributes”로 실패했습니다. 한 건도 색인되지 않았습니다.
- 원인: Bedrock Knowledge Bases와 S3 Vectors를 함께 쓸 때 custom metadata는 vector당 1KB, 35개 키까지입니다. Bedrock이 chunk 본문과 원본 메타데이터를 넣는 내부 키(
AMAZON_BEDROCK_TEXT,AMAZON_BEDROCK_METADATA)를 non-filterable로 명시하지 않으면, 큰 내부 값이 filterable metadata로 취급되어 제한을 넘을 수 있습니다. 인덱스 스키마 문제라 전 문서가 실패합니다(인덱스 정의는 Terraform 섹션에서 다룹니다). - 해결: 인덱스에서 내부 키 2개를 non-filterable로 선언하는 것이 근본 수정이고, 병행해서 custom metadata를 citation에 실제로 쓰이는 3키로 다이어트했습니다. 1KB 한도 안에 여유를 남겨야 합니다.
1
2
3
4
5
6
7
{
"metadataAttributes": {
"doc_title": "경비 규정",
"doc_url": "https://docs.google.com/document/d/{docId}/edit#heading=h.abc123",
"section_path": "경비 규정 > 3.2 항목별 한도 > 식대"
}
}
doc_url에는 이미 heading 앵커가 심겨 있어 이 값 하나로 딥링크 Citation이 완성됩니다. content_hash나 source_version 같은 변경 감지용 데이터는 답변 생성에 쓰이지 않으므로 manifest로 옮겼고, 기능 손실은 없었습니다.
S3 Vectors에서는 metadata sidecar를 작게 유지해야 합니다. sidecar 형식은 includeForEmbedding 같은 Bedrock metadata 옵션을 지원하지만, 이 실습에서는 citation에 필요한 값만 남겨 1KB custom metadata 한도를 넘지 않게 했습니다.
7. Terraform으로 KB 정의하기 (S3 Vectors)
Knowledge Base 전체를 Terraform으로 정의합니다. 구성 요소는 S3 Vectors(vector bucket + index), KB service role, KB, S3 data source입니다. 아래는 마스킹한 예시명 기준 스니펫입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
resource "aws_s3vectors_vector_bucket" "docs_rag" {
vector_bucket_name = "docs-rag-kb-vector"
}
resource "aws_s3vectors_index" "docs_rag" {
vector_bucket_name = aws_s3vectors_vector_bucket.docs_rag.vector_bucket_name
index_name = "docs-rag-kb-index"
data_type = "float32"
dimension = 1024 # Cohere Embed Multilingual v3
distance_metric = "cosine"
# Bedrock 내부 키 2개는 반드시 non-filterable. 누락 시 전 문서 ingestion 실패.
metadata_configuration {
non_filterable_metadata_keys = ["AMAZON_BEDROCK_TEXT", "AMAZON_BEDROCK_METADATA"]
}
}
resource "aws_bedrockagent_knowledge_base" "docs_rag" {
name = "docs-rag-kb"
role_arn = aws_iam_role.docs_rag_kb.arn
knowledge_base_configuration {
type = "VECTOR"
vector_knowledge_base_configuration {
embedding_model_arn = "arn:aws:bedrock:ap-northeast-1::foundation-model/cohere.embed-multilingual-v3"
}
}
storage_configuration {
type = "S3_VECTORS"
s3_vectors_configuration {
index_arn = aws_s3vectors_index.docs_rag.index_arn
}
}
}
resource "aws_bedrockagent_data_source" "docs_rag" {
knowledge_base_id = aws_bedrockagent_knowledge_base.docs_rag.id
name = "docs-rag-kb-ds"
data_source_configuration {
type = "S3"
s3_configuration {
bucket_arn = aws_s3_bucket.docs_rag_artifacts.arn
inclusion_prefixes = ["kb/"] # manifests/ 등 내부 파일 색인 방지
}
}
vector_ingestion_configuration {
chunking_configuration {
chunking_strategy = "HIERARCHICAL"
hierarchical_chunking_configuration {
overlap_tokens = 60
level_configuration { max_tokens = 1500 } # parent
level_configuration { max_tokens = 300 } # child
}
}
}
}
7.1. hierarchical 1500 / 300 / 60을 고른 이유
청킹은 hierarchical로, parent 1500 / child 300 / overlap 60 토큰으로 설정했습니다. 검색은 좁게, 생성은 넓게 하기 위해서입니다. child(300)로 매칭 정밀도를 얻고, 반환은 parent(1500)로 받아 표나 조건 목록이 잘리지 않은 문맥을 생성 모델에 넘깁니다. 정책 문서는 “조건 나열 + 표” 구조라 작은 chunk만 주면 반쪽 답변이 됩니다. 파서가 이미 의미 단위(leaf 섹션)로 잘라 뒀으므로, 섹션 안에서의 추가 분할은 크기 기준으로 충분하고 semantic 청킹의 경계 탐지 이점은 중복입니다.
7.2. 인덱스 immutable 함정 (실측)
- 증상: metadata 실패(색인 파이프라인 섹션의 non-filterable 누락)를 고치려고 인덱스의
non_filterable_metadata_keys를 바꾼 뒤terraform apply를 하자, s3vectors index 하나의 변경이 KB와 data source까지 연쇄 replace로 번졌습니다. apply 이후에는 data source가 404(ResourceNotFoundException)로 조회 자체가 안 됐습니다. - 원인: S3 Vectors 인덱스는 사실상 immutable입니다. non-filterable 키 변경이 인덱스 replace를 유발하고, 그 인덱스를 참조하는 KB의
index_arn이 바뀌면서 KB가 destroy + create됩니다. KB가 destroy될 때 AWS가 하위 data source를 함께 삭제하는데, Terraform state에는 구 data source가 남아 있어 이후 update가 stale 404를 냅니다. - 해결: state에서 data source를 제거한 뒤 재apply하면 새 KB 아래에 data source가 다시 생성됩니다.
1
2
terraform state rm aws_bedrockagent_data_source.docs_rag
terraform apply # data source 1개만 add
교훈은 명확합니다. 인덱스 스키마(non-filterable 키 등)는 최초 생성 시 확정해야 합니다. 나중에 바꾸면 KB/data source ID까지 바뀌어서, 그 ID를 참조하는 워크플로우와 권한 정책을 전부 갱신해야 하는 연쇄 작업이 따라옵니다.
결과: S3 Vectors는 이 비용 구조에 잘 맞지만 semantic search만 지원합니다. hybrid search가 필수라면 이 설계가 아니라 다른 Customer-managed 벡터스토어를 선택해야 합니다.
8. n8n sync 워크플로우 (Lambda 없이)
설계에서는 n8n이 Bedrock을 호출하는 부분에 작은 Lambda wrapper를 두는 방식을 추천했습니다. IAM 권한과 재시도 로직을 Lambda에 몰아넣는다는 이유였습니다. 실제로는 Lambda 없이 n8n 단독으로 색인 파이프라인을 완성했습니다. n8n 러너 이미지에 boto3를 허용하고 IRSA를 붙이면 Lambda가 불필요했고, 오히려 n8n HTTP 노드의 SigV4가 특정 서비스에서 함정이 있어 boto3로 우회해야 했습니다.
노드 체인은 다음과 같습니다.
1
2
3
4
5
6
7
8
Sync Webhook (Header Auth)
-> Normalize Input (docId 등 정규화)
-> Fetch Google Doc (HTTP, SA credential)
-> Parse Sections (Code, Python 파서)
-> S3 PutObject (HTTP, 섹션 md + sidecar 업로드)
-> Start Ingestion Job (Code, boto3)
-> Wait 15s -> Get Ingestion Job (Code, boto3)
-> Ingestion Done? (IF) -> Notify Slack
8.1. n8n HTTP awsAssumeRole SigV4 함정 (실측)
n8n의 AWS credential(awsAssumeRole)로 SigV4 서명을 붙이는 HTTP 노드가 두 서비스에서 각각 다른 이유로 막혔습니다.
S3: region ‘s3’ 오파싱
- 증상: S3 PutObject가 403
AuthorizationHeaderMalformed(“the region ‘s3’ is wrong”)로 실패했습니다. - 원인: n8n awsAssumeRole은 요청 호스트의 첫 라벨로 SigV4 서비스와 리전을 추측합니다. virtual-hosted 스타일 URL(
<bucket>.s3.<region>.amazonaws.com)은 첫 라벨이 버킷명이라 리전을s3로 오파싱합니다. - 해결: path-style URL로 바꿔서 호스트 첫 라벨이
s3가 되고 리전이 경로에서 정상 파싱되도록 했습니다.
1
2
3
4
5
# 오파싱 (virtual-hosted)
https://docs-rag-artifacts.s3.ap-northeast-1.amazonaws.com/kb/{docId}/sections/001.md
# 정상 (path-style)
https://s3.ap-northeast-1.amazonaws.com/docs-rag-artifacts/kb/{docId}/sections/001.md
bedrock-agent: 서명 서비스명 불일치
- 증상:
StartIngestionJob을 HTTP로 호출하자 403 “Credential should be scoped to correct service: ‘bedrock’“이 났습니다. - 원인:
bedrock-agent-*호스트의 실제 SigV4 서명 서비스명은 호스트 라벨과 달리bedrock입니다(AWS 특례). n8n은 호스트 첫 라벨대로bedrock-agent로 서명하므로 매치되지 않습니다. S3처럼 URL을 조작해서 해결할 방법이 없습니다. - 해결: 이 노드만 Python Code 노드(boto3)로 교체했습니다. n8n 러너 이미지에 boto3를 허용(allowlist)하고 IRSA env를 passthrough하면, IRSA role로 전용 role을 assume해서
bedrock-agent클라이언트를 정상적으로 씁니다. boto3가 서명 서비스명을 올바르게 처리하므로 Lambda wrapper가 필요 없습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import boto3
_sts = boto3.client("sts", region_name="ap-northeast-1")
_creds = _sts.assume_role(
RoleArn="arn:aws:iam::<account-id>:role/docs-rag-role",
RoleSessionName="docs-rag-ingest",
)["Credentials"]
_client = boto3.client(
"bedrock-agent", region_name="ap-northeast-1",
aws_access_key_id=_creds["AccessKeyId"],
aws_secret_access_key=_creds["SecretAccessKey"],
aws_session_token=_creds["SessionToken"],
)
_job = _client.start_ingestion_job(
knowledgeBaseId="<KB_ID>", dataSourceId="<DS_ID>")["ingestionJob"]
return [{"json": {"ingestionJobId": _job["ingestionJobId"], "status": _job["status"]}}]
이 구조는 설계 글의 “Lambda wrapper 추천”을 뒤집는 근거가 됩니다. n8n에 boto3 허용과 IRSA만 있으면, 별도 배포 파이프라인/시크릿 관리/로그 조회를 새로 구성할 필요가 없습니다.
8.2. Apps Script는 얇은 트리거로만
문서 담당자가 색인을 갱신하는 진입점은 Google Docs 메뉴 버튼(Apps Script)입니다. 이 스크립트는 문서 내용을 전송하지 않습니다. {docId, ts, triggeredBy}만 웹훅으로 POST하고, 실제 추출은 n8n이 서비스 계정(SA)으로 Docs API를 호출해서 합니다.
1
2
3
Google Docs 메뉴 버튼 (Apps Script)
-> POST {docId, ts} (Header Auth 토큰)
-> n8n Sync Webhook
이렇게 하면 권한 모델이 “SA에 문서 공유” 하나로 수렴합니다. 문서 내용이 Apps Script 경로로 흐르지 않아 전송 실패/로깅 지점이 줄고, Apps Script 로직이 얇아서 버전관리 부담도 작습니다. 파서가 n8n에 있으므로 수동 트리거(curl로 같은 웹훅 호출)로도 동일한 파이프라인이 돕니다. PoC 검증 전체를 curl로 수행할 수 있었습니다.
9. ingestion 검증
9.1. ingestion statistics 읽는 법
StartIngestionJob은 비동기라 job이 끝날 때까지 상태를 폴링하고, 완료되면 통계를 확인합니다. GetIngestionJob 응답의 statistics가 핵심입니다.
| 필드 | 의미 | 확인 포인트 |
|---|---|---|
numberOfDocumentsScanned | 스캔한 문서 수 | 기대 섹션 수와 일치하는가 (색인 파이프라인 섹션의 manifest 오색인 사고를 여기서 잡음) |
numberOfNewDocumentsIndexed | 신규 색인 문서 수 | 최초 sync면 전체, 재sync면 변경분만 |
numberOfDocumentsFailed | 실패 문서 수 | 0이 아니면 metadata 한도 등 확인 |
최초 ingestion에서 scanned가 섹션 수 + 1이면 manifest가 딸려 들어간 것이고, failed가 전체 수와 같으면 metadata attributes 문제(S3 Vectors 한도)입니다. 두 증상 모두 앞선 섹션의 실측 사고와 직결됩니다.
9.2. 증분 재색인 (실측)
문서를 수정하고 재sync하면 전체가 아니라 변경된 섹션만 재색인됩니다. 실측에서 288개를 scanned했지만 재색인된 것은 147개였고, 경로가 바뀌지 않은 챕터는 자동으로 스킵됐습니다. S3 키가 docId 기반으로 안정적이고 섹션 경로가 유지되므로, Bedrock이 변경분만 감지해 임베딩 비용을 아낍니다. 전체 재임베딩 비용이 $0.1 미만인 작은 코퍼스라도, 증분 동작 덕에 잦은 문서 수정에서 색인이 빠르게 끝납니다.
9.3. IF 폴링 regex 함정 (실측)
- 증상: ingestion이 실제로는 이미 끝났는데 폴링 루프가 멈추지 않았고, 결국 “Task request timed out after 60 seconds”로 워크플로우가 죽었습니다.
- 원인: 완료 판정 IF 노드의 regex가
COMPLETE,FAILED(쉼표가 든 리터럴 문자열)였습니다.FAILED상태를 매치하지 못해 Wait/Get 루프가 무한 반복했고, 러너가 고갈되어 timeout이 2차 증상으로 터졌습니다. - 해결: 정규식 OR로 바꿨습니다.
1
2
3
4
5
# 잘못됨: 리터럴 문자열, 어느 상태와도 매치 안 됨
COMPLETE,FAILED
# 올바름: 정규식 OR
COMPLETE|FAILED
종료 상태(COMPLETE 또는 FAILED)를 만나면 루프를 빠져나가고, 그 결과를 Slack으로 통지합니다.
10. Slack 연동: Slash Command 대신 멘션 + n8n Slack Trigger
기존 설계는 Slack Slash Command를 받아 3초 안에 ack를 반환하는 수신 Lambda를 두고, 서명 검증과 Bedrock 질의를 그 Lambda가 처리하는 구조였습니다. 실제로 구축하면서는 이 계층을 전부 걷어내고 n8n Slack Trigger 노드 하나로 대체했습니다.
Slack Events API를 직접 받으려면 세 가지를 반드시 처리해야 합니다.
| 요구사항 | 내용 |
|---|---|
| 서명 검증 | X-Slack-Signature, X-Slack-Request-Timestamp, raw body로 HMAC-SHA256 검증 |
| URL 검증 | 앱 등록 시 오는 url_verification challenge에 그대로 응답 |
| 즉시 ack | 3초 안에 200을 반환하지 않으면 Slack이 재전송 |
n8n의 Slack Trigger 노드(app_mention 이벤트)는 이 세 가지를 노드 내부에서 처리합니다. 서명 검증, challenge 응답, 즉시 200 ack가 전부 트리거에 내장되어 있어 별도의 수신 Lambda가 필요 없습니다. Slash Command 대신 채널에서 @DocsBot을 멘션하는 방식으로 바꾸면, 봇을 초대한 채널 어디서나 자연어로 질문할 수 있습니다.
1
@DocsBot 휴가는 며칠 전에 신청해야 하나요?
10.1. 함정 1. 수동 webhook + 서명 검증은 구현 자체가 불가능
- 증상: 처음에는 범용 Webhook 노드로 Slack 이벤트를 받고, Python Code 노드에서 서명을 직접 검증하려 했습니다. Code 노드가
import hmac,import hashlib에서 바로 실패했습니다. - 원인: n8n Python 러너 샌드박스는 stdlib import를
datetime,json,time만 허용합니다(task-runner-python 소스로 확정). HMAC-SHA256 서명 검증에 필요한hmac,hashlib을 아예 import할 수 없습니다. - 해결: 서명 검증을 Node.js 계층에서 처리하는 Slack Trigger 노드를 쓰는 것이 사실상 유일한 선택지였습니다. “가벼운 webhook + Python 검증”은 러너 제약 때문에 처음부터 불가능했고, 이 제약을 확인한 뒤로는 트리거 노드로 확정했습니다.
Python Code 노드로 서명 검증을 직접 구현할 계획이라면, 러너 이미지의 허용 stdlib 목록부터 확인하세요.
hmac/hashlib이 막혀 있으면 검증 로직 자체를 올릴 수 없습니다.
10.2. 리액션으로 처리 상태 노출
Slash Command의 응답 지연 대신, 멘션한 메시지에 봇이 리액션을 달아 처리 상태를 보여줍니다. 무응답 구간을 없애는 것이 목적입니다.
| 리액션 | 의미 |
|---|---|
| :eyes: | 질문 접수, 처리 중 |
| :white_check_mark: | 답변 완료 (스레드 확인) |
| :x: | 처리 실패 (재시도 또는 담당자 문의) |
접수 즉시 :eyes:를 달고, 답변을 스레드에 남긴 뒤 :eyes:를 제거하고 :white_check_mark:로 교체합니다. 중간에 어느 노드가 실패하면 :eyes:를 제거하고 :x:를 답니다.
10.3. 함정 2. executionOrder v1은 병렬 분기 순서를 보장하지 않는다
- 증상:
:eyes:와:white_check_mark:가 동시에 남거나,:eyes:제거가 동작하지 않는 것처럼 보였습니다. - 원인: 처음에는 트리거 다음 노드에서 “Ack 리액션 분기”와 “Retrieve 분기”를 병렬로 뒀는데, n8n executionOrder v1은 분기 배열의 순서를 따르지 않습니다. Ack 분기가 전체 흐름이 끝난 뒤(+12초쯤) 맨 마지막에 실행돼,
:eyes:가 붙기도 전에 제거 노드가 먼저 돌면서 지울 리액션이 없는 상태가 됐습니다. - 해결: 병렬 분기를 걷어내고 직렬 체인으로 재구성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Slack Trigger (app_mention)
|
Extract Query (Python: 멘션 토큰 제거 -> 질문만)
|
Ack Reaction (:eyes: 추가)
|
Restore Input (Set: query/channel/thread_ts 필드 복원)
|
Retrieve KB (Python + boto3)
|
Evidence? (IF: 근거 임계 통과 여부)
| |
Gemini Generate Reject Reply
| |
Answer Reply Remove Ack (:eyes: 제거)
|
Remove Ack (:eyes: 제거)
|
Done Reaction (:white_check_mark: 추가)
여기에 한 가지 함정이 더 있습니다. Slack 노드(Ack Reaction)의 출력이 {ok: true}라서 입력으로 들어온 query, channel, thread_ts를 통째로 덮어씁니다. 파이썬 Code 노드는 $('노드명')으로 다른 노드 출력을 크로스참조할 수 없기 때문에, Ack 다음에 Set 노드(Restore Input)를 두고 $('Extract Query')에서 필드를 다시 복원해 Retrieve 노드로 넘겼습니다. 실패 경로도 별도로 붙여서(각 노드 onError=continueErrorOutput), 어느 단계가 실패해도 :eyes:를 제거하고 :x:를 남기도록 했습니다.
11. Retrieve + rerank + 외부 LLM
기존 설계는 RetrieveAndGenerate 한 번으로 검색과 생성을 함께 처리했습니다. 실제 구축에서는 이를 Retrieve(검색 + rerank) 와 외부 LLM 생성으로 분리했습니다.
분리한 이유는 두 가지입니다.
- 생성 모델 자유:
RetrieveAndGenerate는 생성 모델이 Bedrock 모델로 묶입니다. 검색과 생성을 나누면 속도, 한국어 품질, 이미 보유한 유료 티어를 기준으로 생성 모델을 자유롭게 고를 수 있습니다. - 근거 게이트 직접 제어: 검색 점수가 임계에 못 미치면 생성을 아예 건너뛰고 “근거를 찾지 못했다”고 응답하는 로직을, 애플리케이션(Code 노드) 레벨에서 직접 넣을 수 있습니다.
11.1. rerank가 필요한 이유
임베딩 cosine 점수만으로는 근거 임계 게이트를 세울 수 없습니다. 실측에서 cosine 상위 점수가 0.89~0.84로 좁게 뭉쳐, “이 질문은 답할 근거가 있다/없다”를 가르는 컷을 어디에 둘지 정할 수 없었습니다. rerank 점수축은 분별력이 큽니다. 같은 질의에서 rerank는 목표 섹션을 1위 0.89로 올리고 하위권을 0.30까지 떨어뜨려, 1위와 6위 사이가 0.59가량 벌어졌습니다. 근거 임계 게이트는 이 rerank 점수축에서만 의미가 있습니다.
rerank는 별도 API 호출이 아니라 Retrieve 호출 안의 rerankingConfiguration으로 통합했습니다(모델 cohere.rerank-v3-5). 후보 25개를 뽑아 rerank로 상위 5개만 남깁니다.
| 파라미터 | 값 | 근거 |
|---|---|---|
numberOfResults (후보) | 25 | rerank 요금은 질의당 문서 100개까지 동일 - 후보 확대에 추가 비용 없음 |
numberOfRerankedResults (최종) | 5 | 최종 k는 LLM 입력 토큰과 직결 - 여기서 조절 |
| 근거 임계 | rerank 1위 점수 기준 컷 | 컷 미달이면 생성 생략, 거절 응답 |
11.2. 함정. rerank IAM 403 두 번
- 증상 1: 호출자 role(
docs-rag-role)에bedrock:Rerank를 줬는데도 403. CloudTrail의 세션명이BedrockReranking-*였습니다. - 원인 1: Retrieve에서 rerank를 쓸 때는 호출자 role과 KB service role 모두 권한이 필요합니다. 호출자 role에는
bedrock:Retrieve,bedrock:Rerank,bedrock:InvokeModel이, KB service role에는bedrock:Rerank,bedrock:InvokeModel이 필요합니다. 호출자 role만 설정했으므로 Bedrock이 service role로 수행한 rerank에서 거부됐습니다. - 증상 2: KB service role에 Rerank 권한을 추가했는데도 여전히 403.
- 원인 2:
bedrock:Rerank는 resource type을 지원하지 않는 액션입니다(AWS service reference에서Resources: None확인). 정책에서 rerank 모델 ARN으로 스코프하면 조용히 매치되지 않아 계속 거부됩니다. - 해결: 두 role에 필요한 권한을 모두 부여하고,
bedrock:Rerank는Resource: "*"로 열어야 합니다.bedrock:InvokeModel은 resource-level을 지원하므로 rerank 모델 ARN 제한을 유지하되 별도 Sid로 분리했습니다. 아래 정책 조각은 KB service role에도 같은 방식으로 적용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
{
"Sid": "Rerank",
"Effect": "Allow",
"Action": "bedrock:Rerank",
"Resource": "*"
},
{
"Sid": "InvokeRerankModel",
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:ap-northeast-1::foundation-model/cohere.rerank-v3-5:0"
}
검색은 n8n Python Code 노드에서 boto3로 호출합니다. IRSA로 받은 자격증명으로 전용 role을 assume한 뒤 bedrock-agent-runtime의 retrieve를 부릅니다(전용 role 체인은 다음 섹션 참고). reranking은 텍스트 데이터에만 적용하므로, 이 실습처럼 Markdown 텍스트를 반환하는 흐름에 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import boto3
_sts = boto3.client("sts", region_name="ap-northeast-1")
_creds = _sts.assume_role(
RoleArn="arn:aws:iam::<account-id>:role/docs-rag-role",
RoleSessionName="docs-rag-chat",
)["Credentials"]
_client = boto3.client(
"bedrock-agent-runtime",
region_name="ap-northeast-1",
aws_access_key_id=_creds["AccessKeyId"],
aws_secret_access_key=_creds["SecretAccessKey"],
aws_session_token=_creds["SessionToken"],
)
_resp = _client.retrieve(
knowledgeBaseId="docs-rag-kb",
retrievalQuery={"text": _query[:900]},
retrievalConfiguration={
"vectorSearchConfiguration": {
"numberOfResults": 25,
"rerankingConfiguration": {
"type": "BEDROCK_RERANKING_MODEL",
"bedrockRerankingConfiguration": {
"modelConfiguration": {
"modelArn": "arn:aws:bedrock:ap-northeast-1::foundation-model/cohere.rerank-v3-5:0"
},
"numberOfRerankedResults": 5,
},
},
}
},
)
결과: 이 챗봇은 후보 25개를 Retrieve로 가져와 텍스트 rerank 후 5개만 남기고, 최고 점수가 기준에 못 미치면 LLM 호출을 생략합니다. 검색 실패를 자연스러운 답변으로 포장하지 않는 것이 이 분리의 핵심입니다.
12. 생성: 외부 LLM 호출과 thinking 함정
생성 모델은 발췌 기반 QA에서 속도, 한국어 품질, 이미 보유한 유료 티어를 기준으로 골랐습니다. 여기서는 예시로 Gemini 3.5 Flash를 사용했지만, 어떤 LLM인지는 본질이 아닙니다. 검색과 생성을 분리했기 때문에 Bedrock의 생성 모델로 바꿔도 동일한 구조가 그대로 성립합니다.
12.1. 함정. thinking 토큰이 답변을 절단한다
- 증상: 답변이 중간에 잘려 나왔습니다.
- 원인: thinking 모델은 사고 토큰이
maxOutputTokens를 잠식합니다. 실측에서 thinking에 983 토큰을 쓰고 답변은 37 토큰만 나온 채MAX_TOKENS로 절단됐습니다. - 해결: 발췌 기반 QA에는 긴 사고가 필요 없습니다.
thinkingConfig.thinkingBudget=0으로 끄고maxOutputTokens를 넉넉히 잡았습니다. 사고 토큰을 안 쓰니 속도와 비용도 함께 개선됐습니다.
1
2
3
4
5
6
7
{
"generationConfig": {
"temperature": 0.3,
"maxOutputTokens": 4096,
"thinkingConfig": { "thinkingBudget": 0 }
}
}
발췌를 그대로 옮기는 QA처럼 추론 깊이가 얕은 작업에서는 thinking을 끄는 편이 낫습니다. thinking이 켜져 있으면 사고 토큰이 출력 한도를 먼저 소진해 답변이 잘립니다.
12.2. 프롬프트 원칙
- 발췌 밖 내용은 추측하지 않고, 근거가 부족하면 “정책 문서에서 확인되지 않습니다”로 응답
- 각 사실 뒤에 사용한 발췌 번호를
[n]으로 표기 - 핵심 답 1~2문장 먼저, 이어서 조건/예외/한도 등 상세를 불릿으로
- Slack 형식 지시(굵게
*텍스트*, 불릿-). 다만 모델이 여전히**를 뱉으므로 후처리에서replace로 정리
12.3. citation 조립과 링크 함정
citation은 검색 결과 metadata의 doc_url(문서 heading 앵커 딥링크)과 section_path로 조립합니다. Slack 링크는 <url|label> 형식인데, label에 >가 들어가면 링크가 그 지점에서 조기 종료됩니다. section_path가 상위 > 하위 형태라 그대로 넣으면 링크가 깨져, 구분자를 middle dot으로 교체했습니다.
1
2
3
# section_path의 '>'가 Slack 링크를 끊으므로 구분자를 교체
_label = _h["section_path"].replace(" > ", " / ")
_cites.append(f"[{_i2}] <{_h['doc_url']}|{_label}>")
답변 스레드에는 핵심 답 + 불릿 아래에 *근거* 목록으로 이 링크들을 붙입니다. 사용자가 링크를 눌러 원문 해당 섹션을 바로 확인할 수 있습니다.
13. IAM 설계: 전용 role 체인
n8n은 여러 팀이 공용으로 쓰는 워크플로우 플랫폼입니다. n8n의 IRSA role에 Knowledge Base 권한을 직접 부여하면, 그 클러스터의 모든 워크플로우가 KB를 호출할 수 있게 됩니다. blast radius가 플랫폼 전체로 번지는 셈입니다.
그래서 KB 접근 권한은 별도의 전용 role(docs-rag-role)에 담고, 이 role을 assume할 수 있는 주체를 n8n IRSA role(n8n-role)로만 제한했습니다.
1
2
3
4
5
6
7
8
n8n Pod (IRSA: n8n-role)
|
| sts:AssumeRole (docs-rag-role의 trust policy가 n8n-role만 허용)
v
docs-rag-role
- bedrock-agent-runtime:Retrieve (docs-rag-kb 로 스코프)
- bedrock:Rerank (Resource: "*")
- bedrock:InvokeModel (rerank 모델 ARN 로 스코프)
이렇게 하면 정책 검색 워크플로우만 이 체인을 타고, 다른 워크플로우는 assume 대상이 아니라서 KB에 닿지 못합니다.
시크릿은 종류별로 다르게 관리합니다.
| 시크릿 | 관리 방식 |
|---|---|
| 색인 webhook 트리거 | n8n Header Auth credential (환경변수 미사용) |
| Slack | Slack signing secret + credential store |
| 생성 LLM API key | credential store에 저장, API 타겟 URL로 사용처 제한 |
AWS 자격증명은 정적 키 대신 IRSA + AssumeRole 체인으로만 흐르게 해서, 워크플로우 JSON이나 환경변수에 장기 크레덴셜을 두지 않습니다.
결과: rerank를 켠 Retrieve는 호출자 role과 KB service role의 권한을 함께 검증해야 합니다. 한쪽 role만 확인하면 CloudTrail에는 Bedrock 세션이 보이는데 호출자는 자기 권한만 점검하는 혼동이 생깁니다.
14. 비용
비용 구조의 핵심은 고정비가 작고 대부분 사용량에 비례한다는 점입니다. S3 Vectors는 저장, 쓰기, query request, query 처리량, 반환 데이터에 각각 과금합니다. 현재 규모(수 MB, 작은 검색 결과)에서는 스토리지와 S3 Vectors query 비용이 작고, OpenSearch Serverless 같은 유휴 고정비가 없습니다.
2026-07 단가 기준입니다.
| 항목 | 단가 | 비고 |
|---|---|---|
| Cohere Rerank 3.5 (Bedrock) | $2.00 / 1,000 질의 | 1질의 = 문서 100개까지 포함 |
| 생성 LLM (예: Gemini Flash) | 입력 $1.50 / 1M, 출력 $9.00 / 1M 토큰 | 질문당 비용의 약 80% |
| Cohere Embed Multilingual v3 | 약 $0.10 / 1M 토큰 | 색인 시에만 발생 |
| S3 Vectors 저장 | $0.06 / GB-월 | 현재 규모에서 무시 가능 |
| S3 Vectors query | $2.50 / 1M 요청 + 처리/반환 데이터 | index 크기와 top-k에 따라 달라짐 |
| Customer-managed Knowledge Base | 별도 KB 리소스 과금 없음 | parser, embedding, rerank, 벡터스토어, 생성 모델 사용량은 별도 |
현재 규모에 대입하면 이렇습니다.
| 구분 | 비용 |
|---|---|
| 고정비 (스토리지 일체) | 월 $0.01 미만 |
| 문서 전체 재색인 1회 | $0.1 미만 |
| 질문 1건 (rerank + 생성 + 검색) | 약 $0.014 |
질문 1건 약 $0.014는 이 실습의 프롬프트 길이와 응답 길이로 측정한 값입니다. 이 중 생성 LLM 출력 토큰이 약 80%를 차지합니다. 즉 답변 길이 정책이 곧 비용 레버입니다. rerank를 빼면 질문당 $0.002를 아끼지만, 근거 임계 게이트가 rerank 점수축에 의존하므로 정확도 대비 유지가 이득입니다. 모델과 리전 단가는 수시로 바뀌므로 배포 전에는 해당 리전의 가격표와 Cost Explorer로 다시 계산합니다.
사용량 시나리오(영업일 22일 기준)입니다.
| 사용량 | 월 비용 |
|---|---|
| 50 질문/일 | 약 $15 |
| 200 질문/일 | 약 $62 |
| 500 질문/일 | 약 $154 |
50 질문/일이 월 약 $15입니다. 항상 떠 있는 벡터 스토어의 고정비를 매달 내는 구조와 달리, 질문이 없는 날은 사실상 과금이 없습니다.
15. 평가와 다음 단계
정확도를 감으로 판단하지 않으려면 평가 질문셋이 필요합니다. 실사용 질문 10~20개로 골든 Q&A를 만들고, 다음 지표를 기록합니다.
| 지표 | 설명 |
|---|---|
| retrieval hit rate | 정답 섹션이 검색 결과에 포함된 비율 |
| answer correctness | 기대 키워드 또는 기준 답변과 일치한 비율 |
| citation correctness | citation이 맞는 섹션을 가리킨 비율 |
| unknown handling | 근거 없는 질문에 “확인되지 않습니다”로 답한 비율 |
이 질문셋은 정확도 측정에서 그치지 않고 실측 튜닝의 기준선이 됩니다. 튜닝 대상은 다음과 같습니다.
- top-k: 후보 수(
numberOfResults)와 최종 수(numberOfRerankedResults) - 근거 임계값: rerank 점수 몇 점 아래를 거절 처리할지
- 청킹 파라미터: 섹션 분할 단위
16. 마무리
설계 문서 시점의 그림과 완성 시점의 그림을 비교하면, 살아남은 것은 “Google Docs가 원본, S3가 배포 산출물, n8n이 자동화 계층”이라는 골격뿐입니다. PDF도 Lambda도 RetrieveAndGenerate도 구축 과정에서 실측에 밀려 사라졌습니다.
이번 구축에서 얻은 교훈을 한 줄씩 남기면 다음과 같습니다.
1
2
3
4
5
문서 구조 품질이 검색 품질의 상한이다 - 파서는 보정 수단일 뿐
관리형 RAG를 쓰더라도 문서 전처리는 직접 소유해야 citation 품질이 나온다
벡터스토어 선택은 검색 품질보다 비용 구조와 제약(metadata 한도, immutable)을 먼저 본다
검색과 생성을 분리하면 모델 선택과 근거 게이트의 자유를 얻는다
실행 플랫폼(n8n)의 제약은 문서가 아니라 실측으로 드러난다 - 작게 검증하며 전진
평가 질문셋(골든 Q&A) 기반 튜닝 결과가 쌓이면 후속 글로 정리하겠습니다.
17. Reference
- AWS Docs - Amazon S3 Vectors with Bedrock Knowledge Bases
- AWS Docs - Include metadata in a data source to improve knowledge base query
- AWS Docs - How content chunking works for knowledge bases
- AWS API Reference - Retrieve
- AWS Docs - Improve relevance of query responses with a reranker model
- AWS Docs - Permissions for reranking in Amazon Bedrock
- AWS Docs - Knowledge Bases service role and permissions
- AWS Pricing - Amazon Bedrock
- AWS Pricing - Amazon S3
- Google Docs API - documents.get
- n8n Docs - Slack Trigger node
- n8n Docs - Code node
- Slack Docs - Verifying requests from Slack
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi