AWS Lambda 로그 모니터링 하기 - ELK, CloudWatch Logs Subscription Filter

최근 서버리스 기반 단어 암기 앱 Remember Me 프로젝트를 AWS Lambda와 API Gateway를 활용하여 진행하고 있습니다. 서버리스 아키텍처를 구축하면서 다수의 Lambda Function을 프로비저닝 하였는데, 이 과정에서 각 Lambda Function의 로그가 CloudWatch Logs의 Log Group에 분산 저장되어 어떻게 이 로그 데이터를 수집하고 한 곳에서 관리할 수 있을지에 대해 고민하게 되었습니다.
이러한 로그 데이터를 효율적으로 수집하고 중앙 집중화하여 관리하는 방안을 찾던 중, 이전에 경험했던 EFK Stack을 떠올리게 되었습니다. CloudWatch Logs의 Subscription Filter를 활용해 Lambda Function을 구독하고 Subscription Filter 역할을 하는 Lambda Function이 로그데이터를 필터링한 뒤, 로그를 Logstash로 전송하고 전달받은 로그를 Elasticsearch에 저장한 후, Kibana를 통해 로그 데이터를 시각화하는 방식을 구상하게 되었습니다.
해당 포스트에서는 로컬 Kubernetes 환경에 Elasticsearch, Logstash, Kibana를 배포하고 CloudWatch Logs에 쌓이는 로그 데이터를 Amazon Data Firehose로 전송하는 것을 다뤄보도록 하겠습니다.
1. Workflows
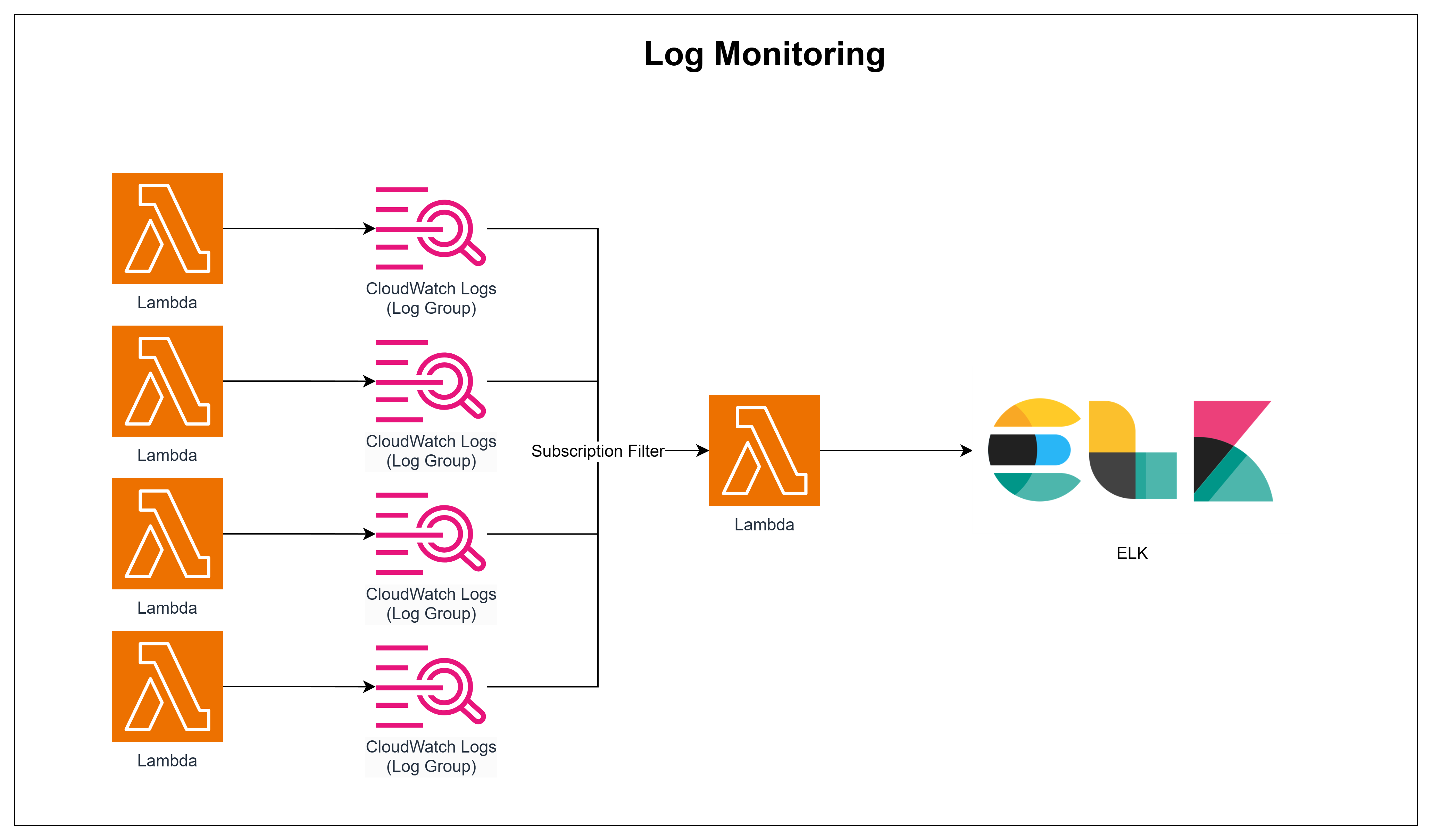
2. ELK Stack 구축
이전에 작성한 EFK Stack 구축하기 (2) - Elasticsearch와 EFK Stack 구축하기 (3) - Kibana를 참고해 Elasticsearch와 Kibana를 구축하고, Logstash는 별도의 Deployment를 통해 구축해보도록 하겠습니다.
2.1. Elasticsearch 배포
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
## CRD 설치
❯ kubectl create -f https://download.elastic.co/downloads/eck/2.15.0/crds.yaml
customresourcedefinition.apiextensions.k8s.io/agents.agent.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/apmservers.apm.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/beats.beat.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticmapsservers.maps.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticsearchautoscalers.autoscaling.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticsearches.elasticsearch.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/enterprisesearches.enterprisesearch.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/kibanas.kibana.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/logstashes.logstash.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/stackconfigpolicies.stackconfigpolicy.k8s.elastic.co created
## operator와 RBAC rule 설치
❯ kubectl apply -f https://download.elastic.co/downloads/eck/2.15.0/operator.yaml
namespace/elastic-system created
serviceaccount/elastic-operator created
secret/elastic-webhook-server-cert created
configmap/elastic-operator created
clusterrole.rbac.authorization.k8s.io/elastic-operator created
clusterrole.rbac.authorization.k8s.io/elastic-operator-view created
clusterrole.rbac.authorization.k8s.io/elastic-operator-edit created
clusterrolebinding.rbac.authorization.k8s.io/elastic-operator created
service/elastic-webhook-server created
statefulset.apps/elastic-operator created
validatingwebhookconfiguration.admissionregistration.k8s.io/elastic-webhook.k8s.elastic.co created
## Elasticsearch 리소스 manifest 파일 생성 elasticsearch.yaml
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch
namespace: logging
spec:
version: 8.16.0
nodeSets:
- name: default
count: 1
config:
# mmap 파일은 메모리 매핑을 통해 파일을 메모리에 올려 빠르게 액세스할 수 있지만, 시스템에 메모리 부족이 발생할 수 있음
# Kubernetes와 같은 컨테이너 환경에서는 메모리 제약이 있을 수 있어 false로 설정하여 메모리 관련 문제를 방지할 수 있음
node.store.allow_mmap: false
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: local-path
## 배포
❯ kubectl apply -f elasticsearch.yaml
elasticsearch.elasticsearch.k8s.elastic.co/elasticsearch created
## 네임스페이스 변경
❯ kubens logging
✔ Active namespace is "logging"
## 배포 확인
❯ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/elasticsearch-es-default-0 1/1 Running 0 4m35s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch-es-default ClusterIP None <none> 9200/TCP 4m37s
service/elasticsearch-es-http ClusterIP 10.98.237.32 <none> 9200/TCP 4m40s
service/elasticsearch-es-internal-http ClusterIP 10.101.122.149 <none> 9200/TCP 4m40s
service/elasticsearch-es-transport ClusterIP None <none> 9300/TCP 4m40s
NAME READY AGE
statefulset.apps/elasticsearch-es-default 1/1 4m37s
2.2. Kibana 배포
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
## Kibana 리소스 manifest 파일 생성 -> kibana.yaml
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana
namespace: logging
spec:
version: 8.16.0
count: 1
elasticsearchRef:
name: elasticsearch
## 배포
❯ kubectl apply -f kibana.yaml
kibana.kibana.k8s.elastic.co/kibana created
## 확인
❯ k get kibana
NAME HEALTH NODES VERSION AGE
kibana green 1 8.16.0 3m1s
## 초기 비밀번호 확인 (초기 유저 아이디: elastic)
❯ kubectl get secret elasticsearch-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo
Rkxxxxx19xxxxxmVxxxa
2.3. 포트포워딩 후 확인
2.4. Logstash 배포
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
apiVersion: logstash.k8s.elastic.co/v1alpha1
kind: Logstash
metadata:
name: logstash
spec:
count: 1
elasticsearchRefs:
- name: elasticsearch
clusterName: elasticsearch
version: 8.16.0
pipelines:
- pipeline.id: main
config.string: |
input {
http {
port => 5044
codec => json
}
}
output {
elasticsearch {
hosts => ["{elasticsearch domain}"]
index => "cloudwatch-logs-lambda-logs-%{+YYYY.MM.dd}"
user => "{elastic}"
password => "{password}"
}
}
services:
- name: http
service:
spec:
type: ClusterIP
ports:
- port: 5044
protocol: TCP
targetPort: 5044
volumeClaimTemplates:
- metadata:
name: logstash-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-path
3. Logstash -> Elasticsearch 연동 테스트
3.1. curl 명령어를 통해 logstash에 로그 데이터 전송
1
2
3
4
5
❯ curl -X POST "{log_stash_url}" \
-H "Content-Type: application/json" \
-d '{"message": "테스트 로그 메시지", "level": "info", "timestamp": "2024-11-20T05:49:03+09:00"}'
ok
3.2. 로그 확인 {elasticsearch url}/_search
logstash로 전송한 로그가 elasticsearch로 전송된 것을 확인할 수 있습니다.
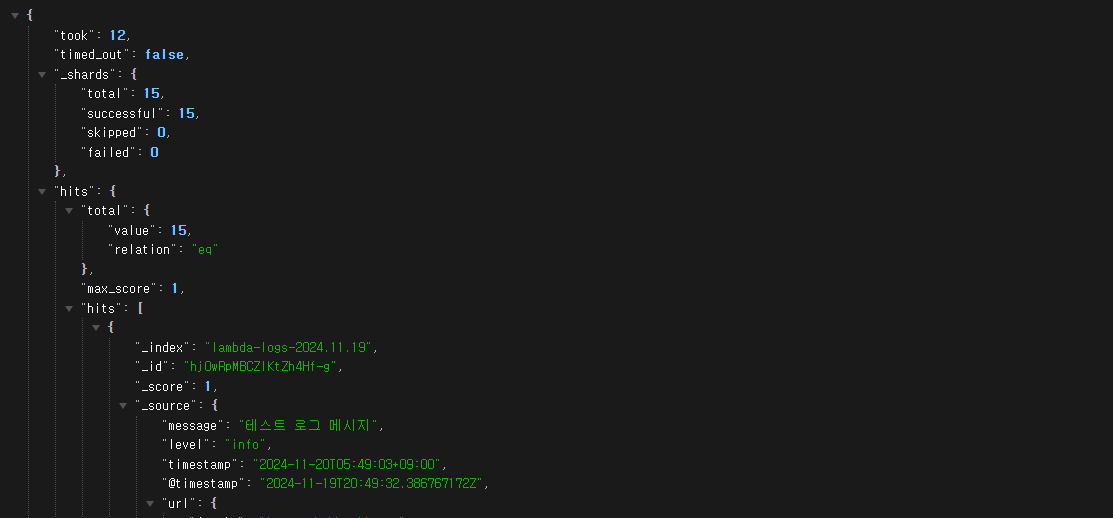
4. Log Group에서 발생시키는 로그데이터 확인
아래 event, content를 확인하기 위한 테스트용 Lambda Function을 생성하고, Lambda 함수의 handler에 어떤 데이터가 들어오는지 확인해보겠습니다.
1
2
3
4
5
def handler(event, context):
print(f"event type => {type(event)}")
print(f"event => {event}")
print(f"context type => {type(context)}")
print(f"context => {context}")
CloudWatch Logs의 Subscription Filter으로 위의 테스트용 Lambda Function로 지정해 테스트 한 결과. 들어오는 데이터의 형식은 아래와 같았습니다.
데이터의 형식에 대해 알아보니 해당 형식은 Log Group에서 Log Data를 전송할 때 데이터를 gzip으로 압축한 뒤, gzip파일을 base64로 인코딩 되어 전달된 결과라는 것을 알 수 있었습니다.
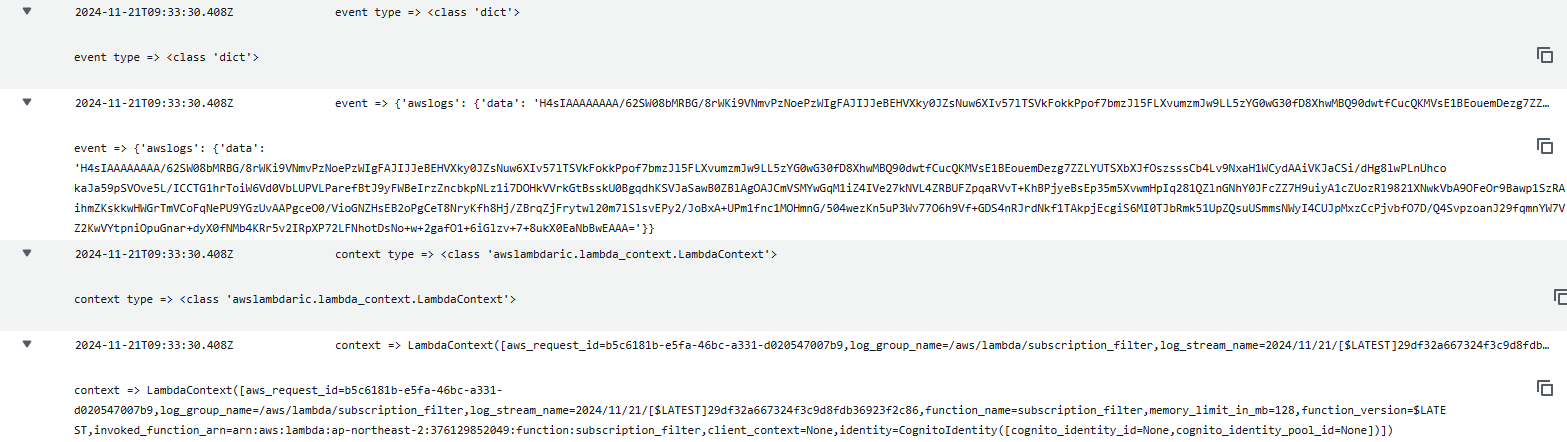
event를 보면 dictionary 타입으로
{'awslogs':{'data': 'gzip 압축 + base64 데이터'}}가 저장되는데 내부 구조가 어떤지 확인해보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# decode_data.py
import base64
import gzip
import io
encoded_data = 'H4sIAAAAAAAA/42Qy27bMBBFfyUYdClZ5PDNnYHYQYC0XVirxkZASWOHgB6uSDctDP974TwWXRTIei7m3nPOMFBK4UD1nyOBh9tlvXz6utpslncrKGB6GWkGD8Jojs4qZNJBAf10uJun0xE8VOElVX0Ymi5UB8r3YzvNM7X5Iaac3qKbPFMYwAMylBXnFbLq8cvDsl5t6l3TSCe71qKVQjqtrWg1MoVKiMCk3kMB6dSkdo7HHKdxHftMcwL/CJlSLt+aYfdatPpFY77ezhC762qr0Wg0TilppeXWKjTaMme5ttI6KwQ665hEwVEqoQ0ap7mFAnIcKOUwHMFzI5AjGikUU8WHr3eckvMSWc2N5+hRLBRTP7bZCkZOtVhKZ0UpyWDp3J6XPATJWWD7fcO2+f7b+vs2rym3z3E83MQPdTf91d1isdiOUAD9znNoM3XrSH2XwJ+Brpzg4XMPZvp5opSfXpV8Ztm/+P/FhMtld/kLrnn1cUACAAA='
# Base64 디코딩
decoded_data = base64.b64decode(encoded_data)
# Gzip 압축 해제
with gzip.GzipFile(fileobj=io.BytesIO(decoded_data)) as f:
original_data = f.read()
print(original_data.decode('utf-8'))
1
2
❯ python -u "decode_data.py"
{"messageType":"DATA_MESSAGE","owner":"376129852049","logGroup":"/aws/Lambda/getIncorrectLists","logStream":"2024/11/20/[$LATEST]bb494dc82843496683c62052533a046f","subscriptionFilters":["test-Lambda"],"logEvents":[{"id":"38627627955484818852768098168489833298904231245367279618","timestamp":1732122743505,"message":"2024-11-20T17:12:23.505Z\t830e95c2-4983-4e72-99f1-1aa410a0ffb0\tINFO\tFetching incorrect lists...\n","extractedFields":{"event":"INFO\tFetching incorrect lists...\n","request_id":"830e95c2-4983-4e72-99f1-1aa410a0ffb0","timestamp":"2024-11-20T17:12:23.505Z"}}]}
함수가 동작하면서 발생한 로그는
logEvents: 배열 형태로 하나씩 저장되어 전달되는 것을 확인할 수 있습니다.
5. Subscription Filter 역할을 하는 Lambda Function 생성
이전 단계에서 CloudWatch Logs의 Subscription Filter를 통해 데이터가 어떤 방식과 어떤 형식으로 전달되는지 확인할 수 있었습니다.
이제 해당 데이터를 사람이 읽을 수 있는 방식으로 변환 후 데이터를 Logstash로 전달하는 역할을 하는 Lambda Function을 생성해보겠습니다.
logstash url은 Secrets Manager에 값을 불러오는 방식으로 사용했습니다. (Lambda Function에 권한 부여 필수)
기본 내장된 모듈이 아닌 requests 모듈은 Lambda Layer로 추가해주셔야 합니다. 또한 CloudWatch Logs에서 해당 Lambda 함수를 호출할 역할과 권한을 할당해야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
import json
import gzip
import base64
import io
import requests
import boto3
from botocore.exceptions import ClientError
from datetime import datetime, timezone, timedelta
def get_secret():
secret_name = "logstash/url"
region_name = "ap-northeast-2"
# Create a Secrets Manager client
session = boto3.session.Session()
client = session.client(service_name="secretsmanager", region_name="ap-northeast-2")
try:
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
except ClientError as e:
raise e
secret = json.loads(get_secret_value_response["SecretString"])
return secret
def handler(event, context):
# Base64 Decode
decoded_data = base64.b64decode(event["awslogs"]["data"])
# Gzip 압축 해제
with gzip.GzipFile(fileobj=io.BytesIO(decoded_data)) as f:
original_data = f.read()
# json to dictionary
log_data = json.loads(original_data.decode("utf-8"))
print(f"{log_data} \n\n\n\n")
kst = timezone(timedelta(hours=9))
headers = {"Content-Type": "application/json"}
logstash_url = get_secret()["LOGSTASH_URL"]
for log_event in log_data["logEvents"]:
# 개별 로그 이벤트에 공통 필드 추가
# timestamp 변환
timestamp = log_event["timestamp"]
timestamp_in_seconds = timestamp / 1000
readable_time = datetime.fromtimestamp(timestamp_in_seconds, tz=kst).isoformat()
log_event["timestamp"] = readable_time
delivery_dict = dict
delivery_dict = {
"logGroup": log_data["logGroup"],
"eventId": log_event["id"],
"@timestamp": log_event["timestamp"],
"message": log_event["message"],
}
print(delivery_dict)
# Logstash로 개별 로그 이벤트 전송
response = requests.post(
logstash_url, data=json.dumps(delivery_dict), headers=headers
)
print(f"Logstash response: {response.status_code}, {response.text}")
return {"statusCode": 200, "body": "Logs sent to Logstash"}
6. CloudWatch Log Group - Subscription Filter 설정
예시를 위해 콘솔에서 작업했습니다. Lambda Function의 개수가 많아질경우 콘솔에서 작업하기 보다는 IaC 도구 사용을 추천드립니다.
CloudWatch에 들어가서 로그 그룹을 선택한 뒤, 작업 -> 구독 필터 -> Lambda 구독 필터 생성
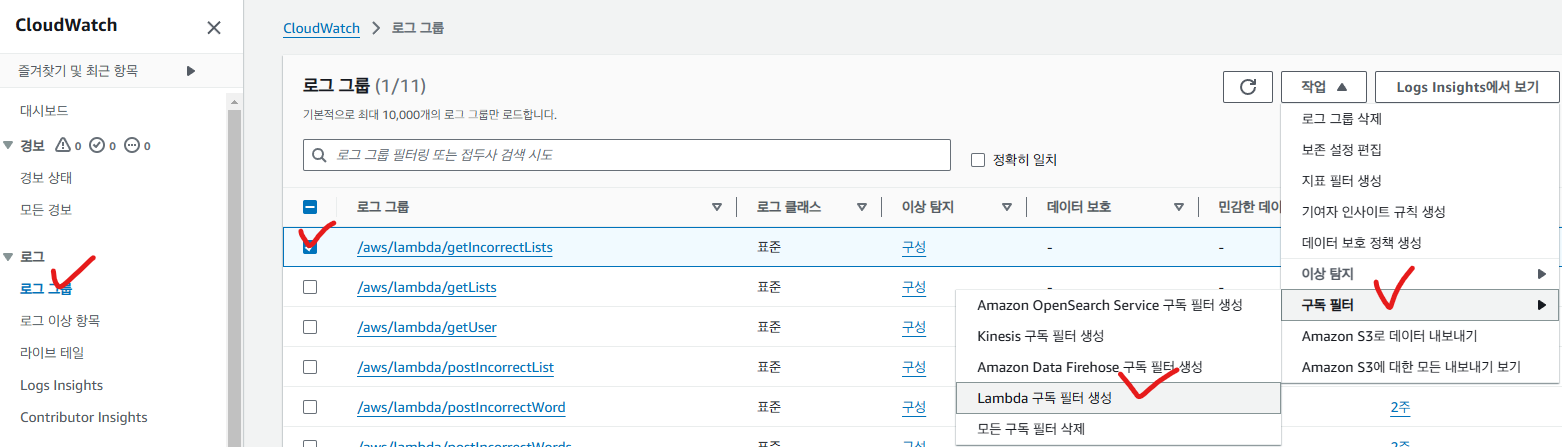
subscription filter 역할을 하는 Lambda function을 선택합니다.
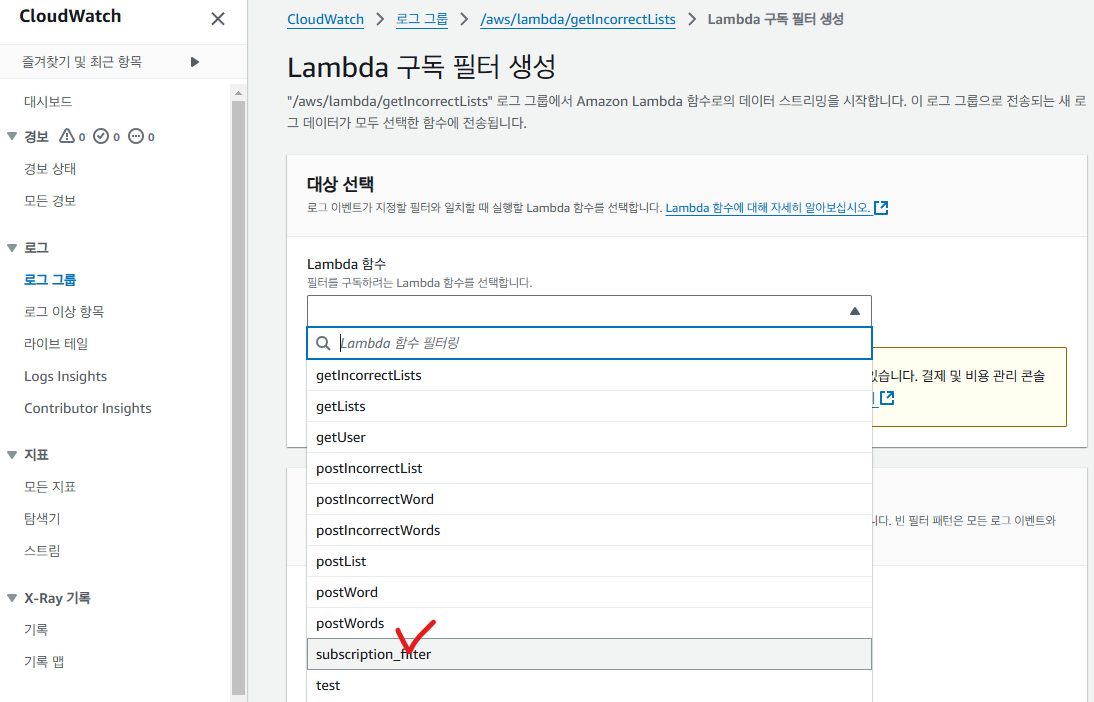
로그 형식을 JSON 방식으로 지정한 뒤, 구독 필터 이름을 넣어준 뒤 Subscription Filter를 생성합니다.
7. 테스트
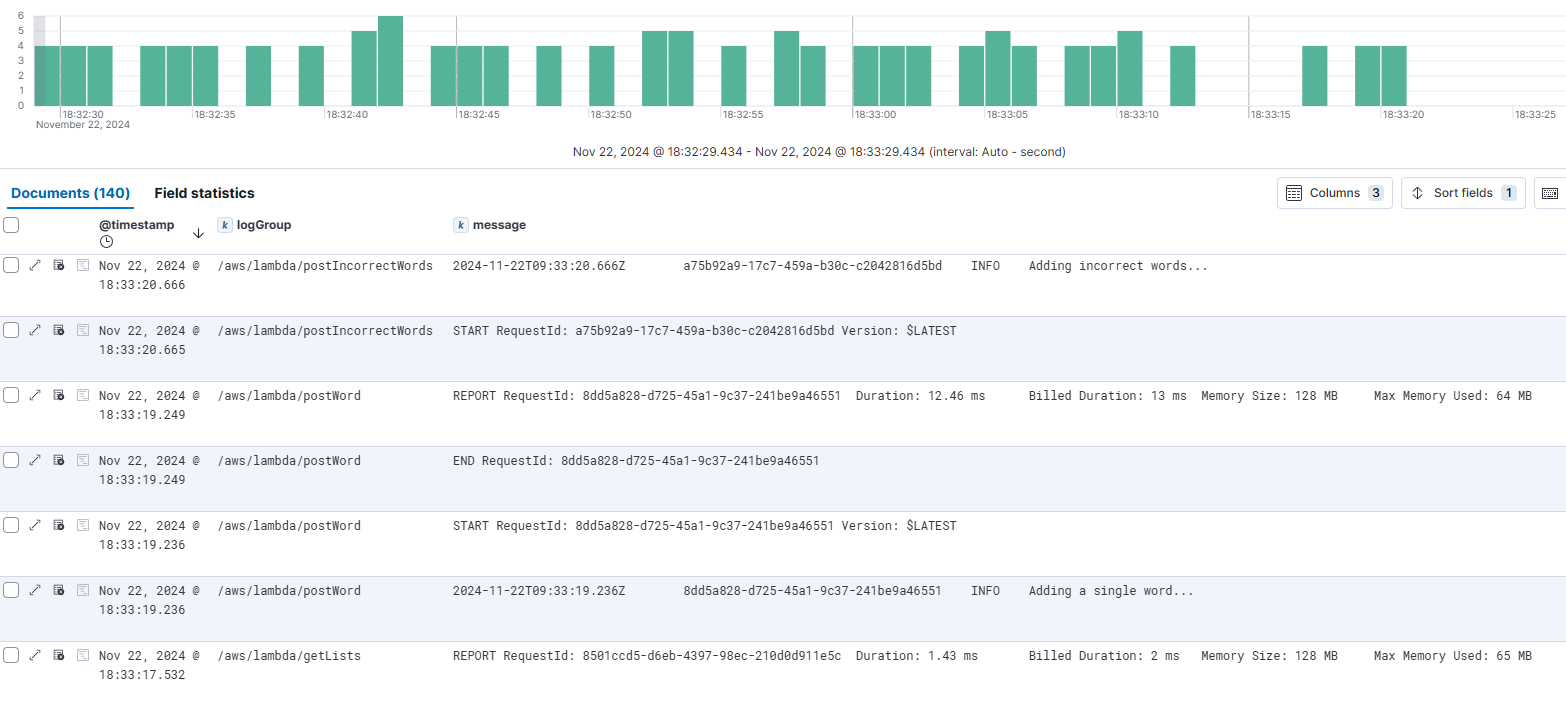
해당 Lambda Function을 호출한 뒤 kibana를 통해 해당 Lambda Function의 로그가 제대로 전달되는지 확인해보겠습니다.
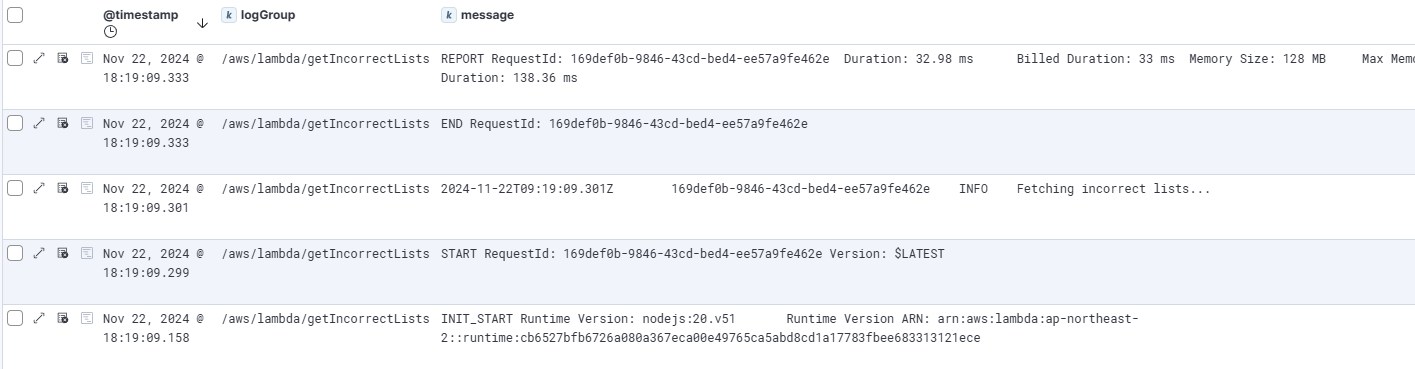
Lambda Function에서 생성되는 로그를 CloudWatch Log Group의 Subscribe Filter를 통해 Kibana에서 확인이 가능한 것을 알 수 있습니다.
8. 결과
ELK를 통해 다수의 Lambda Function에서 발생하는 로그 데이터를 한 곳에서 확인할 수 있게 되었습니다.
아직 Kibana Dashboard의 가시성과 로그 데이터 필터링 부분에서 많이 개선이 필요하지만. 휴식을 취하고 차근차근 개선해보도록 하겠습니다.
궁금하신 점이나 추가해야 할 부분은 댓글이나 아래의 링크를 통해 문의해주세요.
Written with KKamJi